 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Safety Analysis for LLMs: a Benchmark, an Assessment, and a Path Forward
Apr 12, 2024While Large Language Models (LLMs) have seen widespread applications across numerous fields, their limited interpretability poses concerns regarding their safe operations from multiple aspects, e.g., truthfulness, robustness, and fairness. Recent research has started developing quality assurance methods for LLMs, introducing techniques such as offline detector-based or uncertainty estimation methods. However, these approaches predominantly concentrate on post-generation analysis, leaving the online safety analysis for LLMs during the generation phase an unexplored area. To bridge this gap, we conduct in this work a comprehensive evaluation of the effectiveness of existing online safety analysis methods on LLMs. We begin with a pilot study that validates the feasibility of detecting unsafe outputs in the early generation process. Following this, we establish the first publicly available benchmark of online safety analysis for LLMs, including a broad spectrum of methods, models, tasks, datasets, and evaluation metrics. Utilizing this benchmark, we extensively analyze the performance of state-of-the-art online safety analysis methods on both open-source and closed-source LLMs. This analysis reveals the strengths and weaknesses of individual methods and offers valuable insights into selecting the most appropriate method based on specific application scenarios and task requirements. Furthermore, we also explore the potential of using hybridization methods, i.e., combining multiple methods to derive a collective safety conclusion, to enhance the efficacy of online safety analysis for LLMs. Our findings indicate a promising direction for the development of innovative and trustworthy quality assurance methodologies for LLMs, facilitating their reliable deployments across diverse domains.
LRR: Language-Driven Resamplable Continuous Representation against Adversarial Tracking Attacks
Apr 09, 2024



Visual object tracking plays a critical role in visual-based autonomous systems, as it aims to estimate the position and size of the object of interest within a live video. Despite significant progress made in this field, state-of-the-art (SOTA) trackers often fail when faced with adversarial perturbations in the incoming frames. This can lead to significant robustness and security issues when these trackers are deployed in the real world. To achieve high accuracy on both clean and adversarial data, we propose building a spatial-temporal continuous representation using the semantic text guidance of the object of interest. This novel continuous representation enables us to reconstruct incoming frames to maintain semantic and appearance consistency with the object of interest and its clean counterparts. As a result, our proposed method successfully defends against different SOTA adversarial tracking attacks while maintaining high accuracy on clean data. In particular, our method significantly increases tracking accuracy under adversarial attacks with around 90% relative improvement on UAV123, which is even higher than the accuracy on clean data.
PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
Apr 06, 2024



Despite tremendous advancements in large language models (LLMs) over recent years, a notably urgent challenge for their practical deployment is the phenomenon of hallucination, where the model fabricates facts and produces non-factual statements. In response, we propose PoLLMgraph, a Polygraph for LLMs, as an effective model-based white-box detection and forecasting approach. PoLLMgraph distinctly differs from the large body of existing research that concentrates on addressing such challenges through black-box evaluations. In particular, we demonstrate that hallucination can be effectively detected by analyzing the LLM's internal state transition dynamics during generation via tractable probabilistic models. Experimental results on various open-source LLMs confirm the efficacy of PoLLMgraph, outperforming state-of-the-art methods by a considerable margin, evidenced by over 20% improvement in AUC-ROC on common benchmarking datasets like TruthfulQA. Our work paves a new way for model-based white-box analysis of LLMs, motivating the research community to further explore, understand, and refine the intricate dynamics of LLM behaviors.
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024



As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
DEEP-ICL: Definition-Enriched Experts for Language Model In-Context Learning
Mar 07, 2024



It has long been assumed that the sheer number of parameters in large language models (LLMs) drives in-context learning (ICL) capabilities, enabling remarkable performance improvements by leveraging task-specific demonstrations. Challenging this hypothesis, we introduce DEEP-ICL, a novel task Definition Enriched ExPert Ensembling methodology for ICL. DEEP-ICL explicitly extracts task definitions from given demonstrations and generates responses through learning task-specific examples. We argue that improvement from ICL does not directly rely on model size, but essentially stems from understanding task definitions and task-guided learning. Inspired by this, DEEP-ICL combines two 3B models with distinct roles (one for concluding task definitions and the other for learning task demonstrations) and achieves comparable performance to LLaMA2-13B. Furthermore, our framework outperforms conventional ICL by overcoming pretraining sequence length limitations, by supporting unlimited demonstrations. We contend that DEEP-ICL presents a novel alternative for achieving efficient few-shot learning, extending beyond the conventional ICL.
PromptCharm: Text-to-Image Generation through Multi-modal Prompting and Refinement
Mar 06, 2024



The recent advancements in Generative AI have significantly advanced the field of text-to-image generation. The state-of-the-art text-to-image model, Stable Diffusion, is now capable of synthesizing high-quality images with a strong sense of aesthetics. Crafting text prompts that align with the model's interpretation and the user's intent thus becomes crucial. However, prompting remains challenging for novice users due to the complexity of the stable diffusion model and the non-trivial efforts required for iteratively editing and refining the text prompts. To address these challenges, we propose PromptCharm, a mixed-initiative system that facilitates text-to-image creation through multi-modal prompt engineering and refinement. To assist novice users in prompting, PromptCharm first automatically refines and optimizes the user's initial prompt. Furthermore, PromptCharm supports the user in exploring and selecting different image styles within a large database. To assist users in effectively refining their prompts and images, PromptCharm renders model explanations by visualizing the model's attention values. If the user notices any unsatisfactory areas in the generated images, they can further refine the images through model attention adjustment or image inpainting within the rich feedback loop of PromptCharm. To evaluate the effectiveness and usability of PromptCharm, we conducted a controlled user study with 12 participants and an exploratory user study with another 12 participants. These two studies show that participants using PromptCharm were able to create images with higher quality and better aligned with the user's expectations compared with using two variants of PromptCharm that lacked interaction or visualization support.
m2mKD: Module-to-Module Knowledge Distillation for Modular Transformers
Feb 26, 2024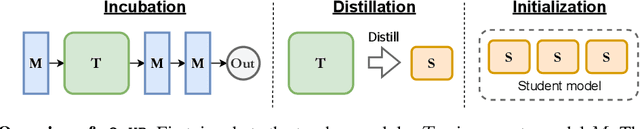
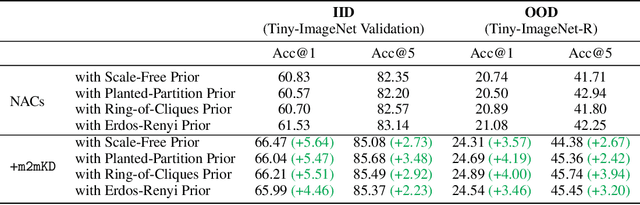
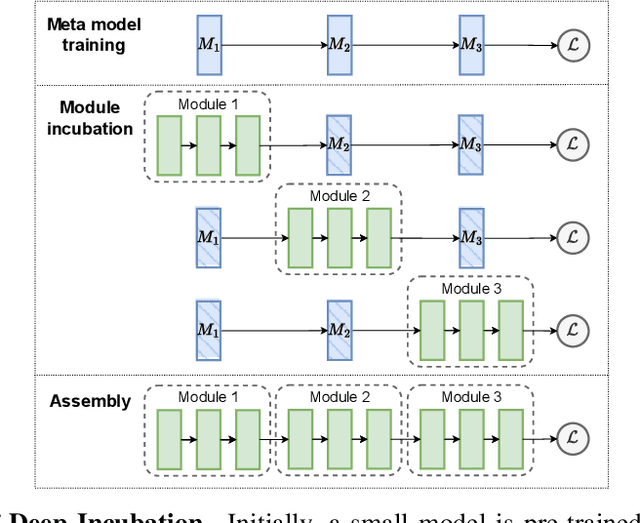
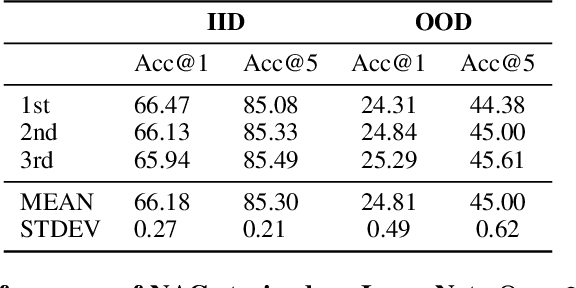
Modular neural architectures are gaining increasing attention due to their powerful capability for generalization and sample-efficient adaptation to new domains. However, training modular models, particularly in the early stages, poses challenges due to the optimization difficulties arising from their intrinsic sparse connectivity. Leveraging the knowledge from monolithic models, using techniques such as knowledge distillation, is likely to facilitate the training of modular models and enable them to integrate knowledge from multiple models pretrained on diverse sources. Nevertheless, conventional knowledge distillation approaches are not tailored to modular models and can fail when directly applied due to the unique architectures and the enormous number of parameters involved. Motivated by these challenges, we propose a general module-to-module knowledge distillation (m2mKD) method for transferring knowledge between modules. Our approach involves teacher modules split from a pretrained monolithic model, and student modules of a modular model. m2mKD separately combines these modules with a shared meta model and encourages the student module to mimic the behaviour of the teacher module. We evaluate the effectiveness of m2mKD on two distinct modular neural architectures: Neural Attentive Circuits (NACs) and Vision Mixture-of-Experts (V-MoE). By applying m2mKD to NACs, we achieve significant improvements in IID accuracy on Tiny-ImageNet (up to 5.6%) and OOD robustness on Tiny-ImageNet-R (up to 4.2%). On average, we observe a 1% gain in both ImageNet and ImageNet-R. The V-MoE-Base model trained using m2mKD also achieves 3.5% higher accuracy than end-to-end training on ImageNet. The experimental results demonstrate that our method offers a promising solution for connecting modular networks with pretrained monolithic models. Code is available at https://github.com/kamanphoebe/m2mKD.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
Large Language Models Based Fuzzing Techniques: A Survey
Feb 07, 2024In the modern era where software plays a pivotal role, software security and vulnerability analysis have become essential for software development. Fuzzing test, as an efficient software testing method, are widely used in various domains. Moreover, the rapid development of Large Language Models (LLMs) has facilitated their application in the field of software testing, demonstrating remarkable performance. Considering that existing fuzzing test techniques are not entirely automated and software vulnerabilities continue to evolve, there is a growing trend towards employing fuzzing test generated based on large language models. This survey provides a systematic overview of the approaches that fuse LLMs and fuzzing tests for software testing. In this paper, a statistical analysis and discussion of the literature in three areas, namely LLMs, fuzzing test, and fuzzing test generated based on LLMs, are conducted by summarising the state-of-the-art methods up until 2024. Our survey also investigates the potential for widespread deployment and application of fuzzing test techniques generated by LLMs in the future.
Learning to Robustly Reconstruct Low-light Dynamic Scenes from Spike Streams
Jan 19, 2024



As a neuromorphic sensor with high temporal resolution, spike camera can generate continuous binary spike streams to capture per-pixel light intensity. We can use reconstruction methods to restore scene details in high-speed scenarios. However, due to limited information in spike streams, low-light scenes are difficult to effectively reconstruct. In this paper, we propose a bidirectional recurrent-based reconstruction framework, including a Light-Robust Representation (LR-Rep) and a fusion module, to better handle such extreme conditions. LR-Rep is designed to aggregate temporal information in spike streams, and a fusion module is utilized to extract temporal features. Additionally, we have developed a reconstruction benchmark for high-speed low-light scenes. Light sources in the scenes are carefully aligned to real-world conditions. Experimental results demonstrate the superiority of our method, which also generalizes well to real spike streams. Related codes and proposed datasets will be released after publication.