 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADEV: A Language-Driven Testing and Evaluation Platform for Vision-Language-Action Models in Robotic Manipulation
Oct 07, 2024



Building on the advancements of Large Language Models (LLMs) and Vision Language Models (VLMs), recent research has introduced Vision-Language-Action (VLA) models as an integrated solution for robotic manipulation tasks. These models take camera images and natural language task instructions as input and directly generate control actions for robots to perform specified tasks, greatly improving both decision-making capabilities and interaction with human users. However, the data-driven nature of VLA models, combined with their lack of interpretability, makes the assurance of their effectiveness and robustness a challenging task. This highlights the need for a reliable testing and evaluation platform. For this purpose, in this work, we propose LADEV, a comprehensive and efficient platform specifically designed for evaluating VLA models. We first present a language-driven approach that automatically generates simulation environments from natural language inputs, mitigating the need for manual adjustments and significantly improving testing efficiency. Then, to further assess the influence of language input on the VLA models, we implement a paraphrase mechanism that produces diverse natural language task instructions for testing. Finally, to expedite the evaluation process, we introduce a batch-style method for conducting large-scale testing of VLA models. Using LADEV, we conducted experiments on several state-of-the-art VLA models, demonstrating its effectiveness as a tool for evaluating these models. Our results showed that LADEV not only enhances testing efficiency but also establishes a solid baseline for evaluating VLA models, paving the way for the development of more intelligent and advanced robotic systems.
MORTAR: A Model-based Runtime Action Repair Framework for AI-enabled Cyber-Physical Systems
Aug 07, 2024



Cyber-Physical Systems (CPSs) are increasingly prevalent across various industrial and daily-life domains, with applications ranging from robotic operations to autonomous driving. With recent advancements in artificial intelligence (AI), learning-based components, especially AI controllers, have become essential in enhancing the functionality and efficiency of CPSs. However, the lack of interpretability in these AI controllers presents challenges to the safety and quality assurance of AI-enabled CPSs (AI-CPSs). Existing methods for improving the safety of AI controllers often involve neural network repair, which requires retraining with additional adversarial examples or access to detailed internal information of the neural network. Hence, these approaches have limited applicability for black-box policies, where only the inputs and outputs are accessible during operation. To overcome this, we propose MORTAR, a runtime action repair framework designed for AI-CPSs in this work. MORTAR begins by constructing a prediction model that forecasts the quality of actions proposed by the AI controller. If an unsafe action is detected, MORTAR then initiates a repair process to correct it. The generation of repaired actions is achieved through an optimization process guided by the safety estimates from the prediction model. We evaluate the effectiveness of MORTAR across various CPS tasks and AI controllers. The results demonstrate that MORTAR can efficiently improve task completion rates of AI controllers under specified safety specifications. Meanwhile, it also maintains minimal computational overhead, ensuring real-time operation of the AI-CPSs.
Multilingual Blending: LLM Safety Alignment Evaluation with Language Mixture
Jul 10, 2024



As safety remains a crucial concern throughout the development lifecycle of Large Language Models (LLMs), researchers and industrial practitioners have increasingly focused on safeguarding and aligning LLM behaviors with human preferences and ethical standards. LLMs, trained on extensive multilingual corpora, exhibit powerful generalization abilities across diverse languages and domains. However, current safety alignment practices predominantly focus on single-language scenarios, which leaves their effectiveness in complex multilingual contexts, especially for those complex mixed-language formats, largely unexplored. In this study, we introduce Multilingual Blending, a mixed-language query-response scheme designed to evaluate the safety alignment of various state-of-the-art LLMs (e.g., GPT-4o, GPT-3.5, Llama3) under sophisticated, multilingual conditions. We further investigate language patterns such as language availability, morphology, and language family that could impact the effectiveness of Multilingual Blending in compromising the safeguards of LLMs. Our experimental results show that, without meticulously crafted prompt templates, Multilingual Blending significantly amplifies the detriment of malicious queries, leading to dramatically increased bypass rates in LLM safety alignment (67.23% on GPT-3.5 and 40.34% on GPT-4o), far exceeding those of single-language baselines. Moreover, the performance of Multilingual Blending varies notably based on intrinsic linguistic properties, with languages of different morphology and from diverse families being more prone to evading safety alignments. These findings underscore the necessity of evaluating LLMs and developing corresponding safety alignment strategies in a complex, multilingual context to align with their superior cross-language generalization capabilities.
GenSafe: A Generalizable Safety Enhancer for Safe Reinforcement Learning Algorithms Based on Reduced Order Markov Decision Process Model
Jun 06, 2024



Although deep reinforcement learning has demonstrated impressive achievements in controlling various autonomous systems, e.g., autonomous vehicles or humanoid robots, its inherent reliance on random exploration raises safety concerns in their real-world applications. To improve system safety during the learning process, a variety of Safe Reinforcement Learning (SRL) algorithms have been proposed, which usually incorporate safety constraints within the Constrained Markov Decision Process (CMDP) framework. However, the efficacy of these SRL algorithms often relies on accurate function approximations, a task that is notably challenging to accomplish in the early learning stages due to data insufficiency. To address this problem, we introduce a Genralizable Safety enhancer (GenSafe) in this work. Leveraging model order reduction techniques, we first construct a Reduced Order Markov Decision Process (ROMDP) as a low-dimensional proxy for the original cost function in CMDP. Then, by solving ROMDP-based constraints that are reformulated from the original cost constraints, the proposed GenSafe refines the actions taken by the agent to enhance the possibility of constraint satisfaction. Essentially, GenSafe acts as an additional safety layer for SRL algorithms, offering broad compatibility across diverse SRL approaches. The performance of GenSafe is examined on multiple SRL benchmark problems. The results show that, it is not only able to improve the safety performance, especially in the early learning phases, but also to maintain the task performance at a satisfactory level.
Online Safety Analysis for LLMs: a Benchmark, an Assessment, and a Path Forward
Apr 12, 2024While Large Language Models (LLMs) have seen widespread applications across numerous fields, their limited interpretability poses concerns regarding their safe operations from multiple aspects, e.g., truthfulness, robustness, and fairness. Recent research has started developing quality assurance methods for LLMs, introducing techniques such as offline detector-based or uncertainty estimation methods. However, these approaches predominantly concentrate on post-generation analysis, leaving the online safety analysis for LLMs during the generation phase an unexplored area. To bridge this gap, we conduct in this work a comprehensive evaluation of the effectiveness of existing online safety analysis methods on LLMs. We begin with a pilot study that validates the feasibility of detecting unsafe outputs in the early generation process. Following this, we establish the first publicly available benchmark of online safety analysis for LLMs, including a broad spectrum of methods, models, tasks, datasets, and evaluation metrics. Utilizing this benchmark, we extensively analyze the performance of state-of-the-art online safety analysis methods on both open-source and closed-source LLMs. This analysis reveals the strengths and weaknesses of individual methods and offers valuable insights into selecting the most appropriate method based on specific application scenarios and task requirements. Furthermore, we also explore the potential of using hybridization methods, i.e., combining multiple methods to derive a collective safety conclusion, to enhance the efficacy of online safety analysis for LLMs. Our findings indicate a promising direction for the development of innovative and trustworthy quality assurance methodologies for LLMs, facilitating their reliable deployments across diverse domains.
Self-Refined Large Language Model as Automated Reward Function Designer for Deep Reinforcement Learning in Robotics
Oct 02, 2023



Although Deep Reinforcement Learning (DRL) has achieved notable success in numerous robotic applications, designing a high-performing reward function remains a challenging task that often requires substantial manual input. Recently, Large Language Models (LLMs) have been extensively adopted to address tasks demanding in-depth common-sense knowledge, such as reasoning and planning. Recognizing that reward function design is also inherently linked to such knowledge, LLM offers a promising potential in this context. Motivated by this, we propose in this work a novel LLM framework with a self-refinement mechanism for automated reward function design. The framework commences with the LLM formulating an initial reward function based on natural language inputs. Then, the performance of the reward function is assessed, and the results are presented back to the LLM for guiding its self-refinement process. We examine the performance of our proposed framework through a variety of continuous robotic control tasks across three diverse robotic systems. The results indicate that our LLM-designed reward functions are able to rival or even surpass manually designed reward functions, highlighting the efficacy and applicability of our approach.
ISR-LLM: Iterative Self-Refined Large Language Model for Long-Horizon Sequential Task Planning
Aug 26, 2023



Motivated by the substantial achievements observed in Large Language Models (LLMs) in the field of natural language processing, recent research has commenced investigations into the application of LLMs for complex, long-horizon sequential task planning challenges in robotics. LLMs are advantageous in offering the potential to enhance the generalizability as task-agnostic planners and facilitate flexible interaction between human instructors and planning systems. However, task plans generated by LLMs often lack feasibility and correctness. To address this challenge, we introduce ISR-LLM, a novel framework that improves LLM-based planning through an iterative self-refinement process. The framework operates through three sequential steps: preprocessing, planning, and iterative self-refinement. During preprocessing, an LLM translator is employed to convert natural language input into a Planning Domain Definition Language (PDDL) formulation. In the planning phase, an LLM planner formulates an initial plan, which is then assessed and refined in the iterative self-refinement step by using a validator. We examine the performance of ISR-LLM across three distinct planning domains. The results show that ISR-LLM is able to achieve markedly higher success rates in task accomplishments compared to state-of-the-art LLM-based planners. Moreover, it also preserves the broad applicability and generalizability of working with natural language instructions.
Towards Building AI-CPS with NVIDIA Isaac Sim: An Industrial Benchmark and Case Study for Robotics Manipulation
Jul 31, 2023



As a representative cyber-physical system (CPS), robotic manipulator has been widely adopted in various academic research and industrial processes, indicating its potential to act as a universal interface between the cyber and the physical worlds. Recent studies in robotics manipulation have started employing artificial intelligence (AI) approaches as controllers to achieve better adaptability and performance. However, the inherent challenge of explaining AI components introduces uncertainty and unreliability to these AI-enabled robotics systems, necessitating a reliable development platform for system design and performance assessment. As a foundational step towards building reliable AI-enabled robotics systems, we propose a public industrial benchmark for robotics manipulation in this paper. It leverages NVIDIA Omniverse Isaac Sim as the simulation platform, encompassing eight representative manipulation tasks and multiple AI software controllers. An extensive evaluation is conducted to analyze the performance of AI controllers in solving robotics manipulation tasks, enabling a thorough understanding of their effectiveness. To further demonstrate the applicability of our benchmark, we develop a falsification framework that is compatible with physical simulators and OpenAI Gym environments. This framework bridges the gap between traditional testing methods and modern physics engine-based simulations. The effectiveness of different optimization methods in falsifying AI-enabled robotics manipulation with physical simulators is examined via a falsification test. Our work not only establishes a foundation for the design and development of AI-enabled robotics systems but also provides practical experience and guidance to practitioners in this field, promoting further research in this critical academic and industrial domain.
Data Generation Method for Learning a Low-dimensional Safe Region in Safe Reinforcement Learning
Sep 10, 2021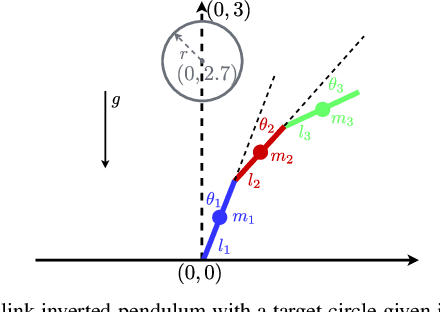
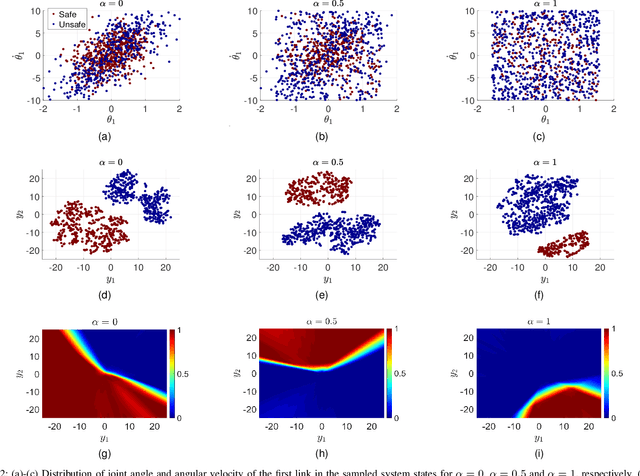
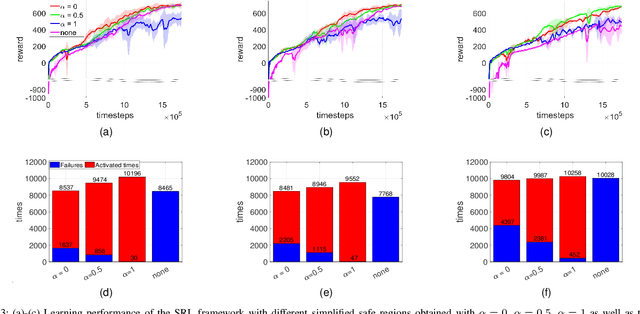
Safe reinforcement learning aims to learn a control policy while ensuring that neither the system nor the environment gets damaged during the learning process. For implementing safe reinforcement learning on highly nonlinear and high-dimensional dynamical systems, one possible approach is to find a low-dimensional safe region via data-driven feature extraction methods, which provides safety estimates to the learning algorithm. As the reliability of the learned safety estimates is data-dependent, we investigate in this work how different training data will affect the safe reinforcement learning approach. By balancing between the learning performance and the risk of being unsafe, a data generation method that combines two sampling methods is proposed to generate representative training data. The performance of the method is demonstrated with a three-link inverted pendulum example.
Learning a Low-dimensional Representation of a Safe Region for Safe Reinforcement Learning on Dynamical Systems
Oct 19, 2020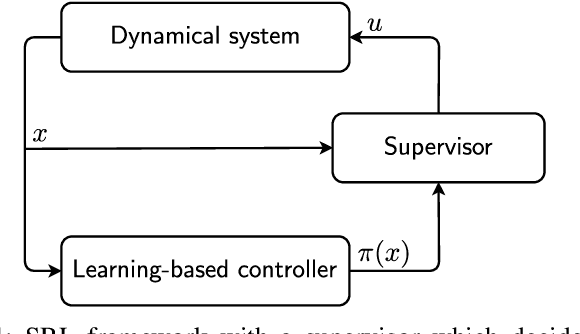
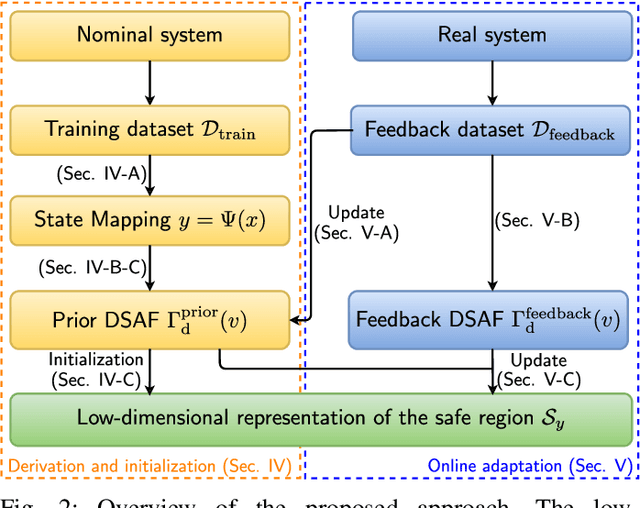
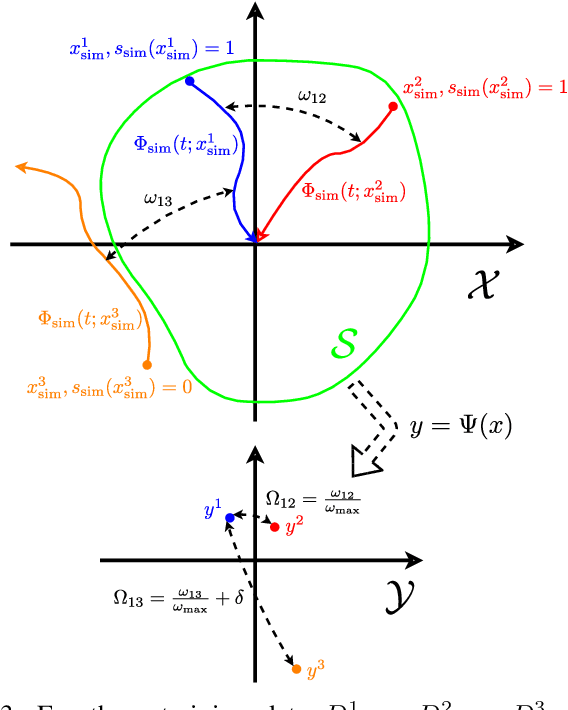
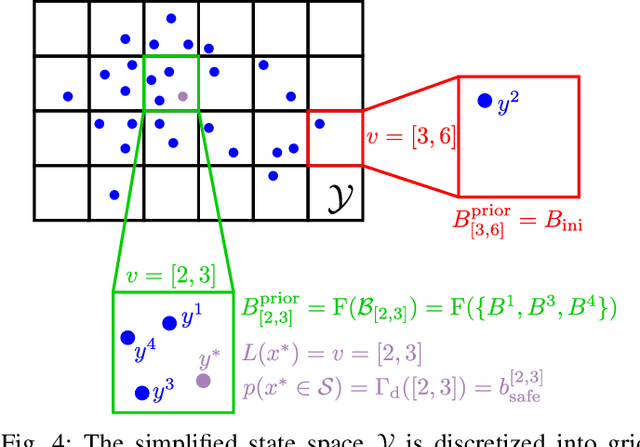
For safely applying reinforcement learning algorithms on high-dimensional nonlinear dynamical systems, a simplified system model is used to formulate a safe reinforcement learning framework. Based on the simplified system model, a low-dimensional representation of the safe region is identified and is used to provide safety estimates for learning algorithms. However, finding a satisfying simplified system model for complex dynamical systems usually requires a considerable amount of effort. To overcome this limitation, we propose in this work a general data-driven approach that is able to efficiently learn a low-dimensional representation of the safe region. Through an online adaptation method, the low-dimensional representation is updated by using the feedback data such that more accurate safety estimates are obtained. The performance of the proposed approach for identifying the low-dimensional representation of the safe region is demonstrated with a quadcopter example. The results show that, compared to previous work, a more reliable and representative low-dimensional representation of the safe region is derived, which then extends the applicability of the safe reinforcement learning framework.