 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeGMM: Single-Pass Probabilistic Forecasting via Adaptive Gaussian Mixture Models with Reversible Normalization
Jan 18, 2026Probabilistic time series forecasting is crucial for quantifying future uncertainty, with significant applications in fields such as energy and finance. However, existing methods often rely on computationally expensive sampling or restrictive parametric assumptions to characterize future distributions, which limits predictive performance and introduces distributional mismatch. To address these challenges, this paper presents TimeGMM, a novel probabilistic forecasting framework based on Gaussian Mixture Models (GMM) that captures complex future distributions in a single forward pass. A key component is GMM-adapted Reversible Instance Normalization (GRIN), a novel module designed to dynamically adapt to temporal-probabilistic distribution shifts. The framework integrates a dedicated Temporal Encoder (TE-Module) with a Conditional Temporal-Probabilistic Decoder (CTPD-Module) to jointly capture temporal dependencies and mixture distribution parameters. Extensive experiments demonstrate that TimeGMM consistently outperforms state-of-the-art methods, achieving maximum improvements of 22.48\% in CRPS and 21.23\% in NMAE.
Service Provisioning and Path Planning with Obstacle Avoidance for Low-Altitude Wireless Networks
Jan 15, 2026This paper investigates the three-dimensional (3D) deployment of uncrewed aerial vehicles (UAVs) as aerial base stations in heterogeneous communication networks under constraints imposed by diverse ground obstacles. Given the diverse data demands of user equipments (UEs), a user satisfaction model is developed to provide personalized services. In particular, when a UE is located within a ground obstacle, the UAV must approach the obstacle boundary to ensure reliable service quality. Considering constraints such as UAV failures due to battery depletion, heterogeneous UEs, and obstacles, we aim to maximize overall user satisfaction by jointly optimizing the 3D trajectories of UAVs, transmit beamforming vectors, and binary association indicators between UAVs and UEs. To address the complexity and dynamics of the problem, a block coordinate descent method is adopted to decompose it into two subproblems. The beamforming subproblem is efficiently addressed via a bisection-based water-filling algorithm. For the trajectory and association subproblem, we design a deep reinforcement learning algorithm based on proximal policy optimization to learn an adaptive control policy. Simulation results demonstrate that the proposed scheme outperforms baseline schemes in terms of convergence speed and overall system performance. Moreover, it achieves efficient association and accurate obstacle avoidance.
Achievable Rate and Coding Principle for MIMO Multicarrier Systems With Cross-Domain MAMP Receiver Over Doubly Selective Channels
Jan 07, 2026The integration of multicarrier modulation and multiple-input-multiple-output (MIMO) is critical for reliable transmission of wireless signals in complex environments, which significantly improve spectrum efficiency. Existing studies have shown that popular orthogonal time frequency space (OTFS) and affine frequency division multiplexing (AFDM) offer significant advantages over orthogonal frequency division multiplexing (OFDM) in uncoded doubly selective channels. However, it remains uncertain whether these benefits extend to coded systems. Meanwhile, the information-theoretic limit analysis of coded MIMO multicarrier systems and the corresponding low-complexity receiver design remain unclear. To overcome these challenges, this paper proposes a multi-slot cross-domain memory approximate message passing (MS-CD-MAMP) receiver as well as develops its information-theoretic (i.e., achievable rate) limit and optimal coding principle for MIMO-multicarrier modulation (e.g., OFDM, OTFS, and AFDM) systems. The proposed MS-CD-MAMP receiver can exploit not only the time domain channel sparsity for low complexity but also the corresponding symbol domain constellation constraints for performance enhancement. Meanwhile, limited by the high-dimensional complex state evolution (SE), a simplified single-input single-output variational SE is proposed to derive the achievable rate of MS-CD-MAMP and the optimal coding principle with the goal of maximizing the achievable rate. Numerical results show that coded MIMO-OFDM/OTFS/AFDM with MS-CD-MAMP achieve the same maximum achievable rate in doubly selective channels, whose finite-length performance with practical optimized low-density parity-check (LDPC) codes is only 0.5 $\sim$ 1.8 dB away from the associated theoretical limit, and has 0.8 $\sim$ 4.4 dB gain over the well-designed point-to-point LDPC codes.
Random Multiplexing
Dec 30, 2025As wireless communication applications evolve from traditional multipath environments to high-mobility scenarios like unmanned aerial vehicles, multiplexing techniques have advanced accordingly. Traditional single-carrier frequency-domain equalization (SC-FDE) and orthogonal frequency-division multiplexing (OFDM) have given way to emerging orthogonal time-frequency space (OTFS) and affine frequency-division multiplexing (AFDM). These approaches exploit specific channel structures to diagonalize or sparsify the effective channel, thereby enabling low-complexity detection. However, their reliance on these structures significantly limits their robustness in dynamic, real-world environments. To address these challenges, this paper studies a random multiplexing technique that is decoupled from the physical channels, enabling its application to arbitrary norm-bounded and spectrally convergent channel matrices. Random multiplexing achieves statistical fading-channel ergodicity for transmitted signals by constructing an equivalent input-isotropic channel matrix in the random transform domain. It guarantees the asymptotic replica MAP bit-error rate (BER) optimality of AMP-type detectors for linear systems with arbitrary norm-bounded, spectrally convergent channel matrices and signaling configurations, under the unique fixed point assumption. A low-complexity cross-domain memory AMP (CD-MAMP) detector is considered, leveraging the sparsity of the time-domain channel and the randomness of the equivalent channel. Optimal power allocations are derived to minimize the replica MAP BER and maximize the replica constrained capacity of random multiplexing systems. The optimal coding principle and replica constrained-capacity optimality of CD-MAMP detector are investigated for random multiplexing systems. Additionally, the versatility of random multiplexing in diverse wireless applications is explored.
Perplexity-Aware Data Scaling Law: Perplexity Landscapes Predict Performance for Continual Pre-training
Dec 25, 2025Continual Pre-training (CPT) serves as a fundamental approach for adapting foundation models to domain-specific applications. Scaling laws for pre-training define a power-law relationship between dataset size and the test loss of an LLM. However, the marginal gains from simply increasing data for CPT diminish rapidly, yielding suboptimal data utilization and inefficient training. To address this challenge, we propose a novel perplexity-aware data scaling law to establish a predictive relationship between the perplexity landscape of domain-specific data and the test loss. Our approach leverages the perplexity derived from the pre-trained model on domain data as a proxy for estimating the knowledge gap, effectively quantifying the informational perplexity landscape of candidate training samples. By fitting this scaling law across diverse perplexity regimes, we enable adaptive selection of high-utility data subsets, prioritizing content that maximizes knowledge absorption while minimizing redundancy and noise. Extensive experiments demonstrate that our method consistently identifies near-optimal training subsets and achieves superior performance on both medical and general-domain benchmarks.
Large Model Enabled Embodied Intelligence for 6G Integrated Perception, Communication, and Computation Network
Dec 22, 2025



The advent of sixth-generation (6G) places intelligence at the core of wireless architecture, fusing perception, communication, and computation into a single closed-loop. This paper argues that large artificial intelligence models (LAMs) can endow base stations with perception, reasoning, and acting capabilities, thus transforming them into intelligent base station agents (IBSAs). We first review the historical evolution of BSs from single-functional analog infrastructure to distributed, software-defined, and finally LAM-empowered IBSA, highlighting the accompanying changes in architecture, hardware platforms, and deployment. We then present an IBSA architecture that couples a perception-cognition-execution pipeline with cloud-edge-end collaboration and parameter-efficient adaptation. Subsequently,we study two representative scenarios: (i) cooperative vehicle-road perception for autonomous driving, and (ii) ubiquitous base station support for low-altitude uncrewed aerial vehicle safety monitoring and response against unauthorized drones. On this basis, we analyze key enabling technologies spanning LAM design and training, efficient edge-cloud inference, multi-modal perception and actuation, as well as trustworthy security and governance. We further propose a holistic evaluation framework and benchmark considerations that jointly cover communication performance, perception accuracy, decision-making reliability, safety, and energy efficiency. Finally, we distill open challenges on benchmarks, continual adaptation, trustworthy decision-making, and standardization. Together, this work positions LAM-enabled IBSAs as a practical path toward integrated perception, communication, and computation native, safety-critical 6G systems.
MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025



In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
Accelerating Data Generation for Nonlinear temporal PDEs via homologous perturbation in solution space
Oct 24, 2025



Data-driven deep learning methods like neural operators have advanced in solving nonlinear temporal partial differential equations (PDEs). However, these methods require large quantities of solution pairs\u2014the solution functions and right-hand sides (RHS) of the equations. These pairs are typically generated via traditional numerical methods, which need thousands of time steps iterations far more than the dozens required for training, creating heavy computational and temporal overheads. To address these challenges, we propose a novel data generation algorithm, called HOmologous Perturbation in Solution Space (HOPSS), which directly generates training datasets with fewer time steps rather than following the traditional approach of generating large time steps datasets. This algorithm simultaneously accelerates dataset generation and preserves the approximate precision required for model training. Specifically, we first obtain a set of base solution functions from a reliable solver, usually with thousands of time steps, and then align them in time steps with training datasets by downsampling. Subsequently, we propose a "homologous perturbation" approach: by combining two solution functions (one as the primary function, the other as a homologous perturbation term scaled by a small scalar) with random noise, we efficiently generate comparable-precision PDE data points. Finally, using these data points, we compute the variation in the original equation's RHS to form new solution pairs. Theoretical and experimental results show HOPSS lowers time complexity. For example, on the Navier-Stokes equation, it generates 10,000 samples in approximately 10% of traditional methods' time, with comparable model training performance.
KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints
Oct 22, 2025Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
4DGS-Craft: Consistent and Interactive 4D Gaussian Splatting Editing
Oct 02, 2025
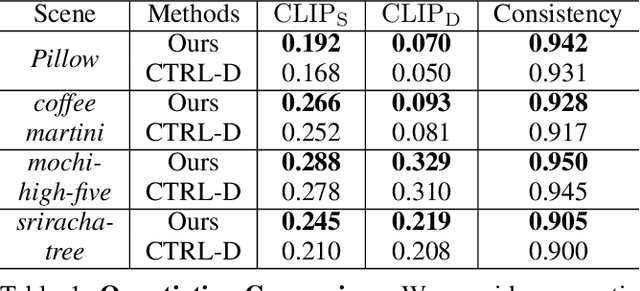
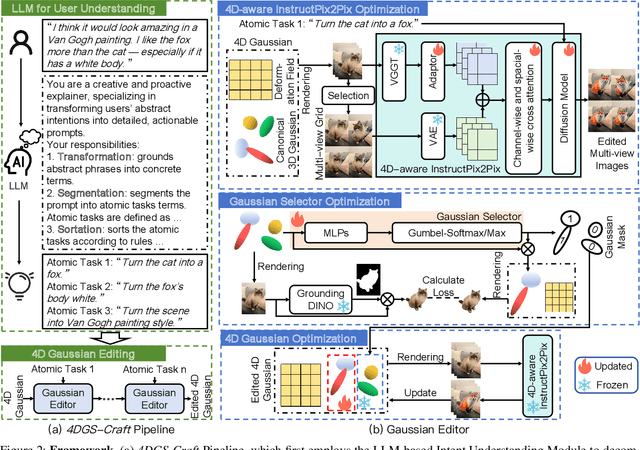
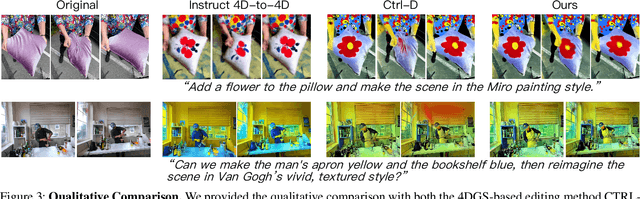
Recent advances in 4D Gaussian Splatting (4DGS) editing still face challenges with view, temporal, and non-editing region consistency, as well as with handling complex text instructions. To address these issues, we propose 4DGS-Craft, a consistent and interactive 4DGS editing framework. We first introduce a 4D-aware InstructPix2Pix model to ensure both view and temporal consistency. This model incorporates 4D VGGT geometry features extracted from the initial scene, enabling it to capture underlying 4D geometric structures during editing. We further enhance this model with a multi-view grid module that enforces consistency by iteratively refining multi-view input images while jointly optimizing the underlying 4D scene. Furthermore, we preserve the consistency of non-edited regions through a novel Gaussian selection mechanism, which identifies and optimizes only the Gaussians within the edited regions. Beyond consistency, facilitating user interaction is also crucial for effective 4DGS editing. Therefore, we design an LLM-based module for user intent understanding. This module employs a user instruction template to define atomic editing operations and leverages an LLM for reasoning. As a result, our framework can interpret user intent and decompose complex instructions into a logical sequence of atomic operations, enabling it to handle intricate user commands and further enhance editing performance. Compared to related works, our approach enables more consistent and controllable 4D scene editing. Our code will be made available upon acceptance.