 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquipping LLM with Directional Multi-Talker Speech Understanding Capabilities
Feb 06, 2026Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech understanding capabilities. However, most speech LLMs are trained on single-channel, single-talker data, which makes it challenging to directly apply them to multi-talker and multi-channel speech understanding task. In this work, we present a comprehensive investigation on how to enable directional multi-talker speech understanding capabilities for LLMs, specifically in smart glasses usecase. We propose two novel approaches to integrate directivity into LLMs: (1) a cascaded system that leverages a source separation front-end module, and (2) an end-to-end system that utilizes serialized output training. All of the approaches utilize a multi-microphone array embedded in smart glasses to optimize directivity interpretation and processing in a streaming manner. Experimental results demonstrate the efficacy of our proposed methods in endowing LLMs with directional speech understanding capabilities, achieving strong performance in both speech recognition and speech translation tasks.
WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Dec 25, 2025Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.
AdapterDistillation: Non-Destructive Task Composition with Knowledge Distillation
Dec 26, 2023



Leveraging knowledge from multiple tasks through introducing a small number of task specific parameters into each transformer layer, also known as adapters, receives much attention recently. However, adding an extra fusion layer to implement knowledge composition not only increases the inference time but also is non-scalable for some applications. To avoid these issues, we propose a two-stage knowledge distillation algorithm called AdapterDistillation. In the first stage, we extract task specific knowledge by using local data to train a student adapter. In the second stage, we distill the knowledge from the existing teacher adapters into the student adapter to help its inference. Extensive experiments on frequently asked question retrieval in task-oriented dialog systems validate the efficiency of AdapterDistillation. We show that AdapterDistillation outperforms existing algorithms in terms of accuracy, resource consumption and inference time.
From Beginner to Expert: Modeling Medical Knowledge into General LLMs
Dec 02, 2023



Recently, large language model (LLM) based artificial intelligence (AI) systems have demonstrated remarkable capabilities in natural language understanding and generation. However, these models face a significant challenge when it comes to sensitive applications, such as reasoning over medical knowledge and answering medical questions in a physician-like manner. Prior studies attempted to overcome this challenge by increasing the model size (>100B) to learn more general medical knowledge, while there is still room for improvement in LLMs with smaller-scale model sizes (<100B). In this work, we start from a pre-trained general LLM model (AntGLM-10B) and fine-tune it from a medical beginner towards a medical expert (called AntGLM-Med-10B), which leverages a 3-stage optimization procedure, \textit{i.e.}, general medical knowledge injection, medical domain instruction tuning, and specific medical task adaptation. Our contributions are threefold: (1) We specifically investigate how to adapt a pre-trained general LLM in medical domain, especially for a specific medical task. (2) We collect and construct large-scale medical datasets for each stage of the optimization process. These datasets encompass various data types and tasks, such as question-answering, medical reasoning, multi-choice questions, and medical conversations. (3) Specifically for multi-choice questions in the medical domain, we propose a novel Verification-of-Choice approach for prompting engineering, which significantly enhances the reasoning ability of LLMs. Remarkably, by combining the above approaches, our AntGLM-Med-10B model can outperform the most of LLMs on PubMedQA, including both general and medical LLMs, even when these LLMs have larger model size.
Reverse Chain: A Generic-Rule for LLMs to Master Multi-API Planning
Oct 10, 2023



While enabling large language models to implement function calling (known as APIs) can greatly enhance the performance of LLMs, function calling is still a challenging task due to the complicated relations between different APIs, especially in a context-learning setting without fine-tuning. This paper proposes a simple yet controllable target-driven approach called Reverse Chain to empower LLMs with capabilities to use external APIs with only prompts. Given that most open-source LLMs have limited tool-use or tool-plan capabilities, LLMs in Reverse Chain are only employed to implement simple tasks, e.g., API selection and argument completion, and a generic rule is employed to implement a controllable multiple functions calling. In this generic rule, after selecting a final API to handle a given task via LLMs, we first ask LLMs to fill the required arguments from user query and context. Some missing arguments could be further completed by letting LLMs select another API based on API description before asking user. This process continues until a given task is completed. Extensive numerical experiments indicate an impressive capability of Reverse Chain on implementing multiple function calling. Interestingly enough, the experiments also reveal that tool-use capabilities of the existing LLMs, e.g., ChatGPT, can be greatly improved via Reverse Chain.
Contextual Font Recommendations based on User Intent
Jun 14, 2023



Adobe Fonts has a rich library of over 20,000 unique fonts that Adobe users utilize for creating graphics, posters, composites etc. Due to the nature of the large library, knowing what font to select can be a daunting task that requires a lot of experience. For most users in Adobe products, especially casual users of Adobe Express, this often means choosing the default font instead of utilizing the rich and diverse fonts available. In this work, we create an intent-driven system to provide contextual font recommendations to users to aid in their creative journey. Our system takes in multilingual text input and recommends suitable fonts based on the user's intent. Based on user entitlements, the mix of free and paid fonts is adjusted. The feature is currently used by millions of Adobe Express users with a CTR of >25%.
R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling
Jul 02, 2021
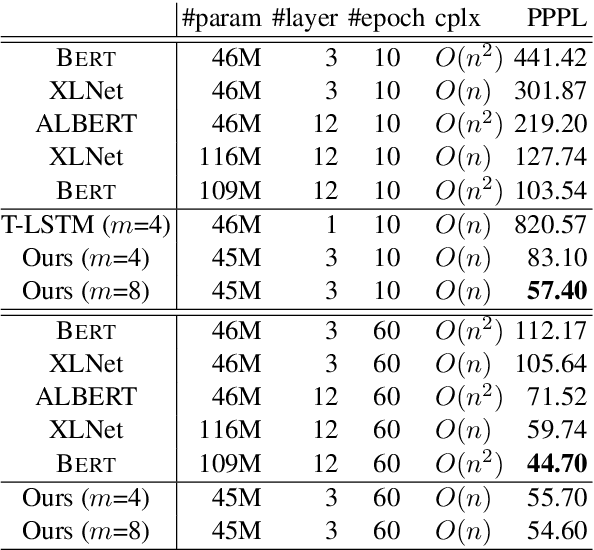
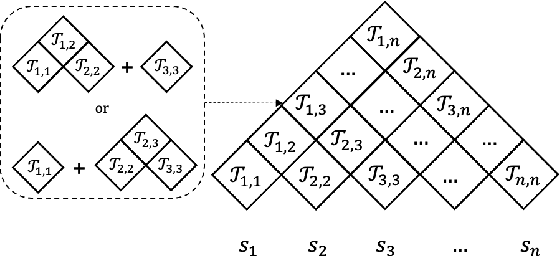
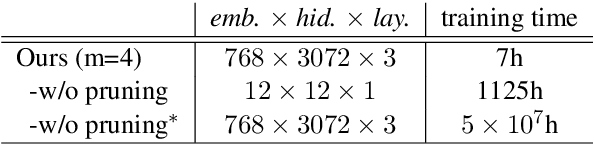
Human language understanding operates at multiple levels of granularity (e.g., words, phrases, and sentences) with increasing levels of abstraction that can be hierarchically combined. However, existing deep models with stacked layers do not explicitly model any sort of hierarchical process. This paper proposes a recursive Transformer model based on differentiable CKY style binary trees to emulate the composition process. We extend the bidirectional language model pre-training objective to this architecture, attempting to predict each word given its left and right abstraction nodes. To scale up our approach, we also introduce an efficient pruned tree induction algorithm to enable encoding in just a linear number of composition steps. Experimental results on language modeling and unsupervised parsing show the effectiveness of our approach.
Reranking Machine Translation Hypotheses with Structured and Web-based Language Models
Apr 25, 2021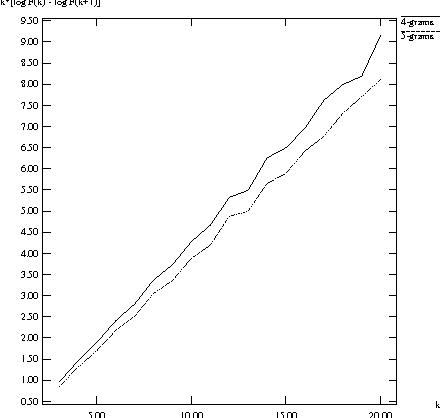
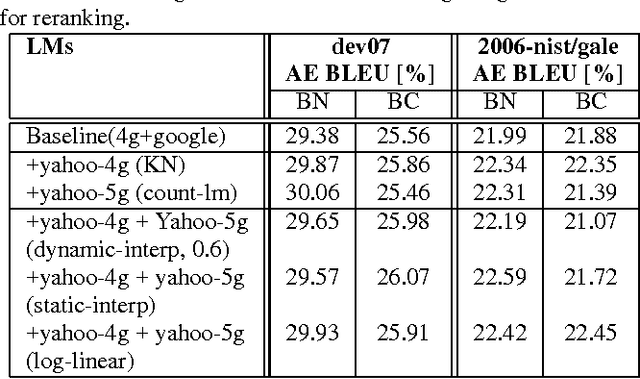
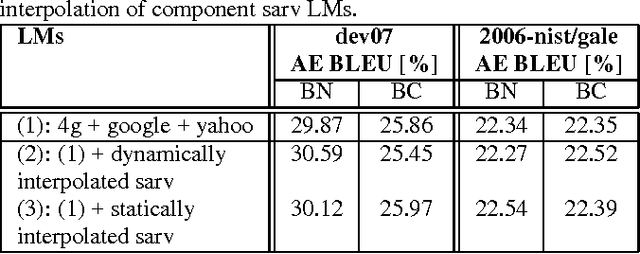
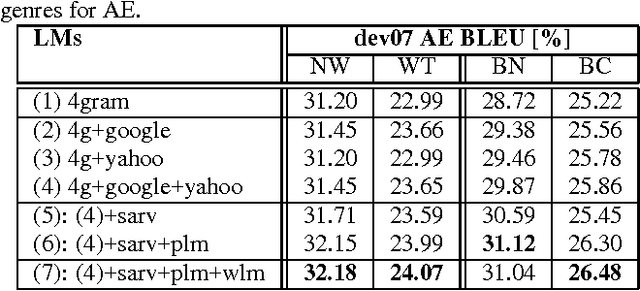
In this paper, we investigate the use of linguistically motivated and computationally efficient structured language models for reranking N-best hypotheses in a statistical machine translation system. These language models, developed from Constraint Dependency Grammar parses, tightly integrate knowledge of words, morphological and lexical features, and syntactic dependency constraints. Two structured language models are applied for N-best rescoring, one is an almost-parsing language model, and the other utilizes more syntactic features by explicitly modeling syntactic dependencies between words. We also investigate effective and efficient language modeling methods to use N-grams extracted from up to 1 teraword of web documents. We apply all these language models for N-best re-ranking on the NIST and DARPA GALE program 2006 and 2007 machine translation evaluation tasks and find that the combination of these language models increases the BLEU score up to 1.6% absolutely on blind test sets.
* With a correction to the math in Figure 1 caption
Graph-based Pyramid Global Context Reasoning with a Saliency-aware Projection for COVID-19 Lung Infections Segmentation
Mar 07, 2021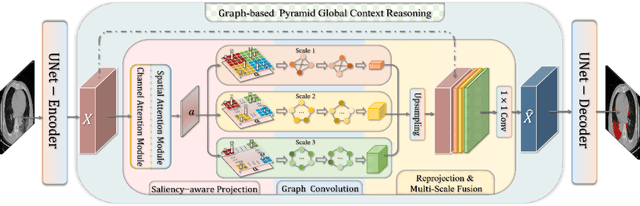
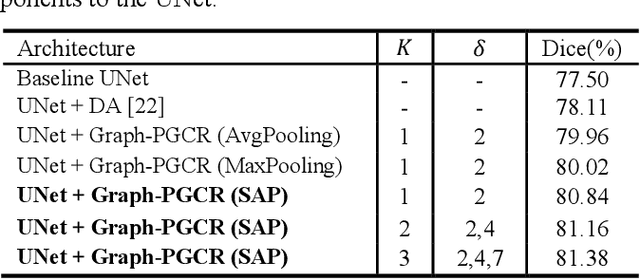
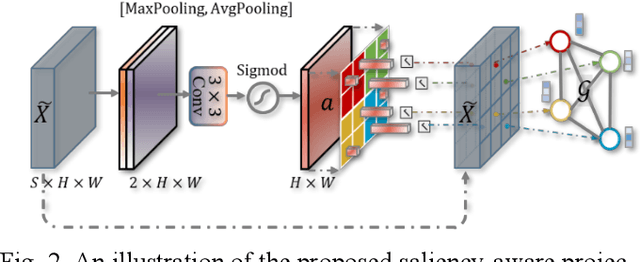
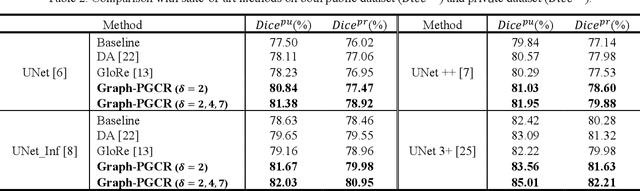
Coronavirus Disease 2019 (COVID-19) has rapidly spread in 2020, emerging a mass of studies for lung infection segmentation from CT images. Though many methods have been proposed for this issue, it is a challenging task because of infections of various size appearing in different lobe zones. To tackle these issues, we propose a Graph-based Pyramid Global Context Reasoning (Graph-PGCR) module, which is capable of modeling long-range dependencies among disjoint infections as well as adapt size variation. We first incorporate graph convolution to exploit long-term contextual information from multiple lobe zones. Different from previous average pooling or maximum object probability, we propose a saliency-aware projection mechanism to pick up infection-related pixels as a set of graph nodes. After graph reasoning, the relation-aware features are reversed back to the original coordinate space for the down-stream tasks. We further construct multiple graphs with different sampling rates to handle the size variation problem. To this end, distinct multi-scale long-range contextual patterns can be captured. Our Graph-PGCR module is plug-and-play, which can be integrated into any architecture to improve its performance. Experiments demonstrated that the proposed method consistently boost the performance of state-of-the-art backbone architectures on both of public and our private COVID-19 datasets.