 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Break-Even Point on Optimization Trajectories of Deep Neural Networks
Feb 21, 2020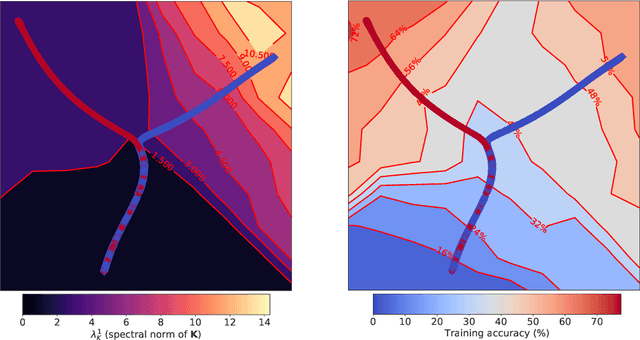
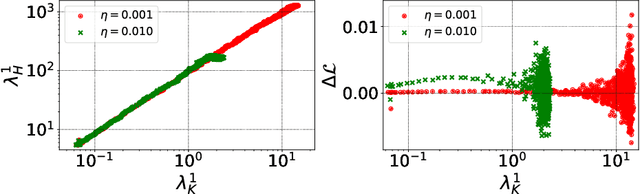

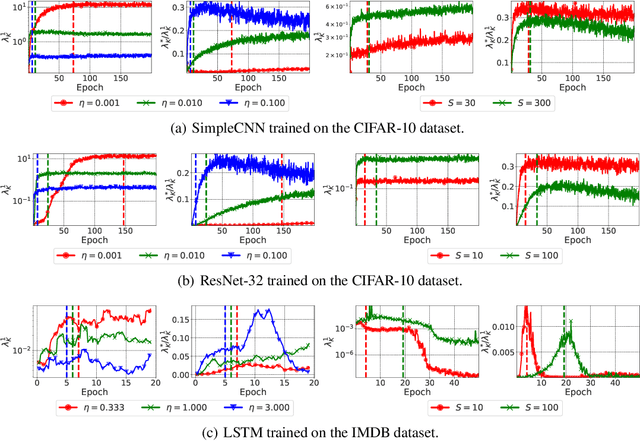
The early phase of training of deep neural networks is critical for their final performance. In this work, we study how the hyperparameters of stochastic gradient descent (SGD) used in the early phase of training affect the rest of the optimization trajectory. We argue for the existence of the "break-even" point on this trajectory, beyond which the curvature of the loss surface and noise in the gradient are implicitly regularized by SGD. In particular, we demonstrate on multiple classification tasks that using a large learning rate in the initial phase of training reduces the variance of the gradient, and improves the conditioning of the covariance of gradients. These effects are beneficial from the optimization perspective and become visible after the break-even point. Complementing prior work, we also show that using a low learning rate results in bad conditioning of the loss surface even for a neural network with batch normalization layers. In short, our work shows that key properties of the loss surface are strongly influenced by SGD in the early phase of training. We argue that studying the impact of the identified effects on generalization is a promising future direction.
On the Discrepancy between Density Estimation and Sequence Generation
Feb 17, 2020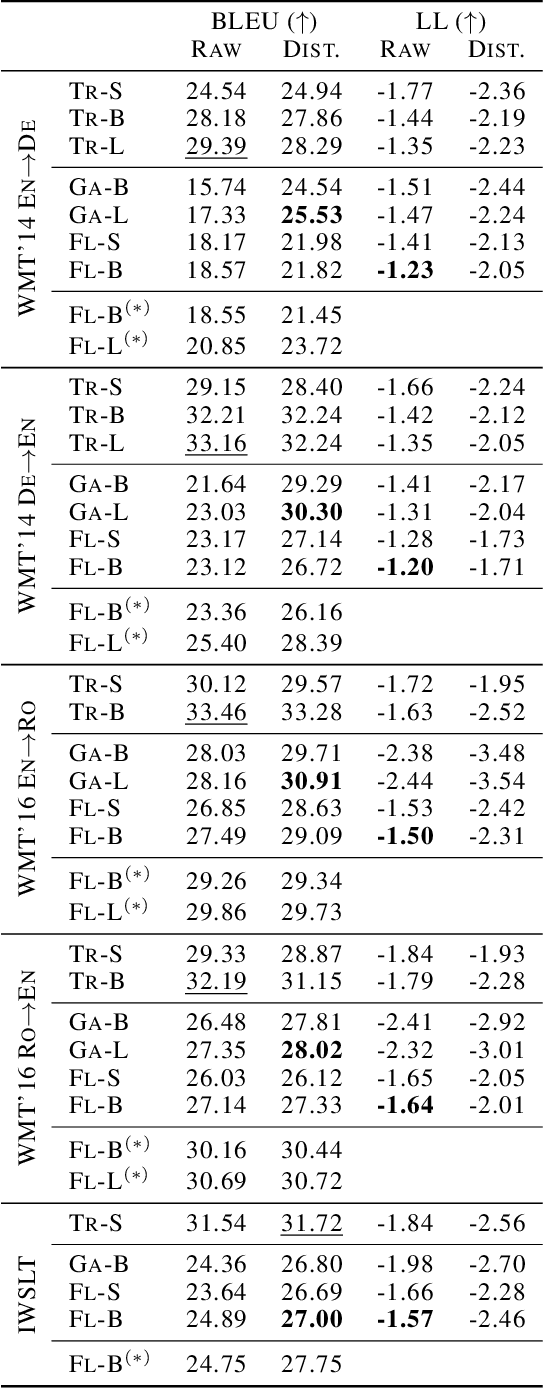
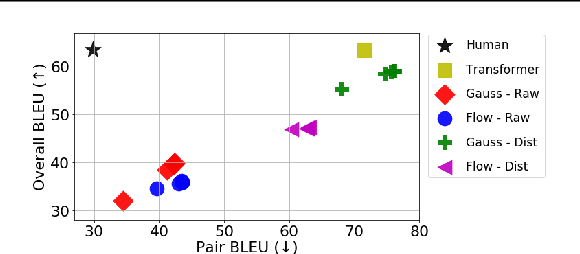

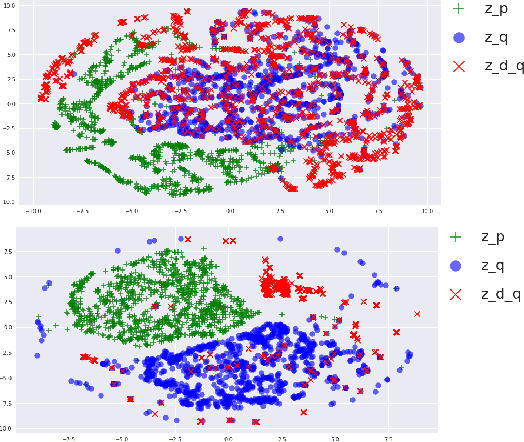
Many sequence-to-sequence generation tasks, including machine translation and text-to-speech, can be posed as estimating the density of the output y given the input x: p(y|x). Given this interpretation, it is natural to evaluate sequence-to-sequence models using conditional log-likelihood on a test set. However, the goal of sequence-to-sequence generation (or structured prediction) is to find the best output y^ given an input x, and each task has its own downstream metric R that scores a model output by comparing against a set of references y*: R(y^, y* | x). While we hope that a model that excels in density estimation also performs well on the downstream metric, the exact correlation has not been studied for sequence generation tasks. In this paper, by comparing several density estimators on five machine translation tasks, we find that the correlation between rankings of models based on log-likelihood and BLEU varies significantly depending on the range of the model families being compared. First, log-likelihood is highly correlated with BLEU when we consider models within the same family (e.g. autoregressive models, or latent variable models with the same parameterization of the prior). However, we observe no correlation between rankings of models across different families: (1) among non-autoregressive latent variable models, a flexible prior distribution is better at density estimation but gives worse generation quality than a simple prior, and (2) autoregressive models offer the best translation performance overall, while latent variable models with a normalizing flow prior give the highest held-out log-likelihood across all datasets. Therefore, we recommend using a simple prior for the latent variable non-autoregressive model when fast generation speed is desired.
An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization
Feb 13, 2020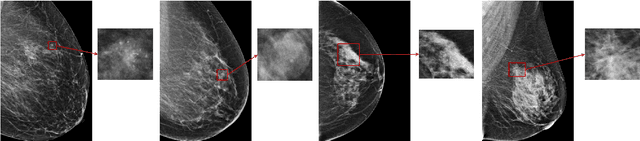
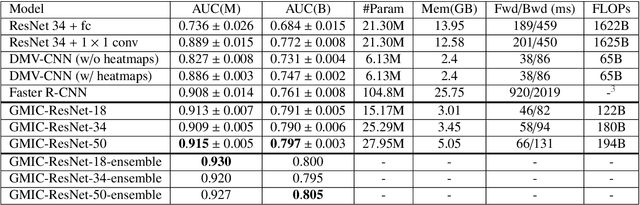
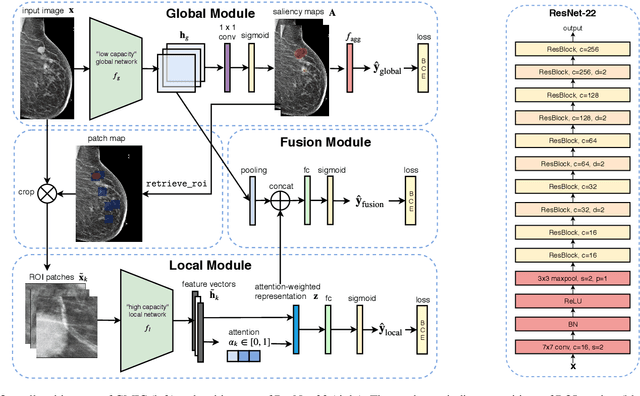
Medical images differ from natural images in significantly higher resolutions and smaller regions of interest. Because of these differences, neural network architectures that work well for natural images might not be applicable to medical image analysis. In this work, we extend the globally-aware multiple instance classifier, a framework we proposed to address these unique properties of medical images. This model first uses a low-capacity, yet memory-efficient, network on the whole image to identify the most informative regions. It then applies another higher-capacity network to collect details from chosen regions. Finally, it employs a fusion module that aggregates global and local information to make a final prediction. While existing methods often require lesion segmentation during training, our model is trained with only image-level labels and can generate pixel-level saliency maps indicating possible malignant findings. We apply the model to screening mammography interpretation: predicting the presence or absence of benign and malignant lesions. On the NYU Breast Cancer Screening Dataset, consisting of more than one million images, our model achieves an AUC of 0.93 in classifying breasts with malignant findings, outperforming ResNet-34 and Faster R-CNN. Compared to ResNet-34, our model is 4.1x faster for inference while using 78.4% less GPU memory. Furthermore, we demonstrate, in a reader study, that our model surpasses radiologist-level AUC by a margin of 0.11. The proposed model is available online: https://github.com/nyukat/GMIC.
Consistency of a Recurrent Language Model With Respect to Incomplete Decoding
Feb 06, 2020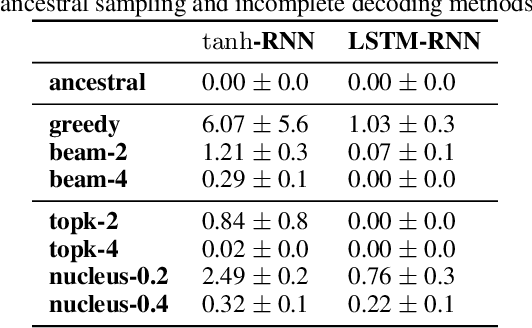
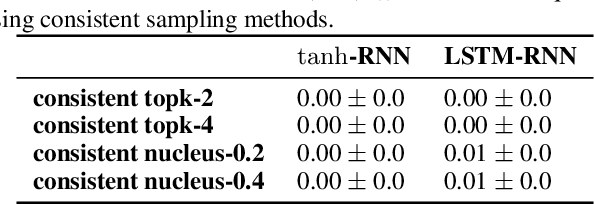


Despite strong performance on a variety of tasks, neural sequence models trained with maximum likelihood have been shown to exhibit issues such as length bias and degenerate repetition. We study the related issue of receiving infinite-length sequences from a recurrent language model when using common decoding algorithms. To analyze this issue, we first define inconsistency of a decoding algorithm, meaning that the algorithm can yield an infinite-length sequence that has zero probability under the model. We prove that commonly used incomplete decoding algorithms - greedy search, beam search, top-k sampling, and nucleus sampling - are inconsistent, despite the fact that recurrent language models are trained to produce sequences of finite length. Based on these insights, we propose two remedies which address inconsistency: consistent variants of top-k and nucleus sampling, and a self-terminating recurrent language model. Empirical results show that inconsistency occurs in practice, and that the proposed methods prevent inconsistency.
Don't Say That! Making Inconsistent Dialogue Unlikely with Unlikelihood Training
Nov 10, 2019
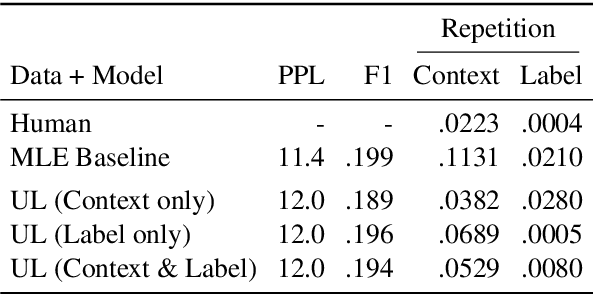
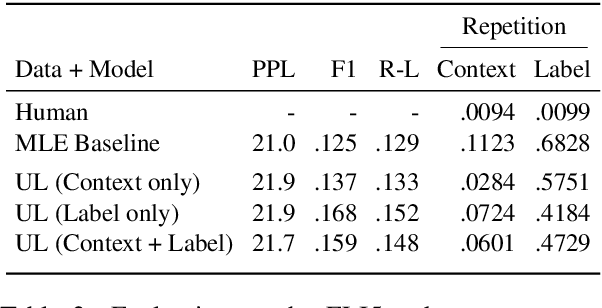
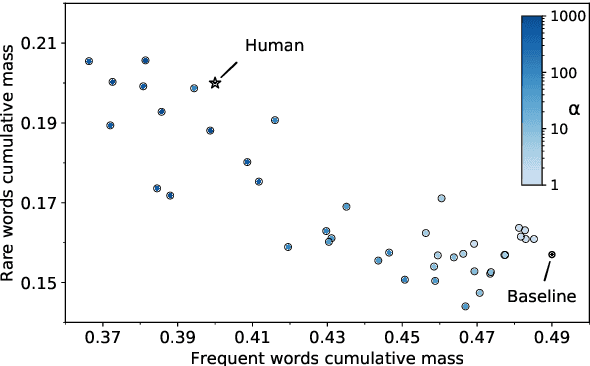
Generative dialogue models currently suffer from a number of problems which standard maximum likelihood training does not address. They tend to produce generations that (i) rely too much on copying from the context, (ii) contain repetitions within utterances, (iii) overuse frequent words, and (iv) at a deeper level, contain logical flaws. In this work we show how all of these problems can be addressed by extending the recently introduced unlikelihood loss (Welleck et al., 2019) to these cases. We show that appropriate loss functions which regularize generated outputs to match human distributions are effective for the first three issues. For the last important general issue, we show applying unlikelihood to collected data of what a model should not do is effective for improving logical consistency, potentially paving the way to generative models with greater reasoning ability. We demonstrate the efficacy of our approach across several dialogue tasks.
Multi-Stage Document Ranking with BERT
Oct 31, 2019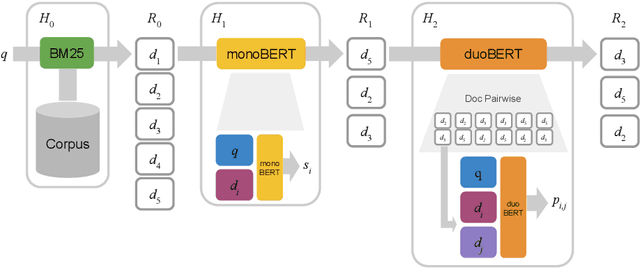
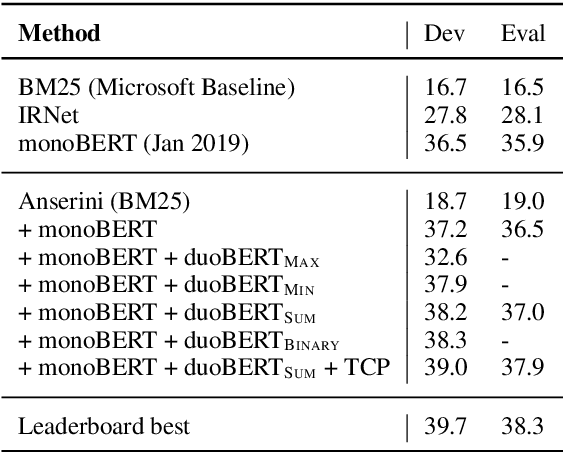

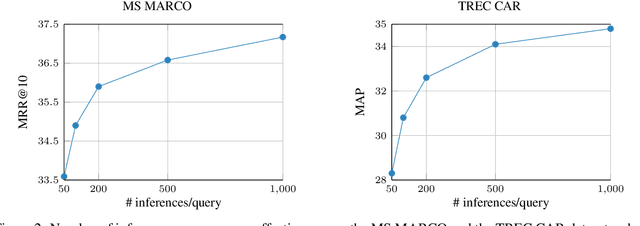
The advent of deep neural networks pre-trained via language modeling tasks has spurred a number of successful applications in natural language processing. This work explores one such popular model, BERT, in the context of document ranking. We propose two variants, called monoBERT and duoBERT, that formulate the ranking problem as pointwise and pairwise classification, respectively. These two models are arranged in a multi-stage ranking architecture to form an end-to-end search system. One major advantage of this design is the ability to trade off quality against latency by controlling the admission of candidates into each pipeline stage, and by doing so, we are able to find operating points that offer a good balance between these two competing metrics. On two large-scale datasets, MS MARCO and TREC CAR, experiments show that our model produces results that are either at or comparable to the state of the art. Ablation studies show the contributions of each component and characterize the latency/quality tradeoff space.
Mix-review: Alleviate Forgetting in the Pretrain-Finetune Framework for Neural Language Generation Models
Oct 29, 2019
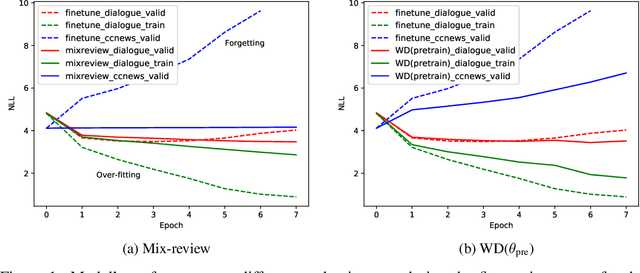
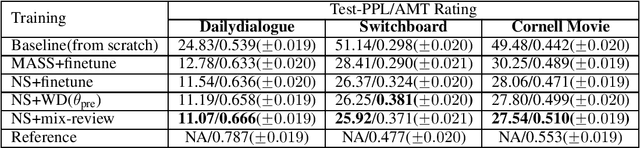
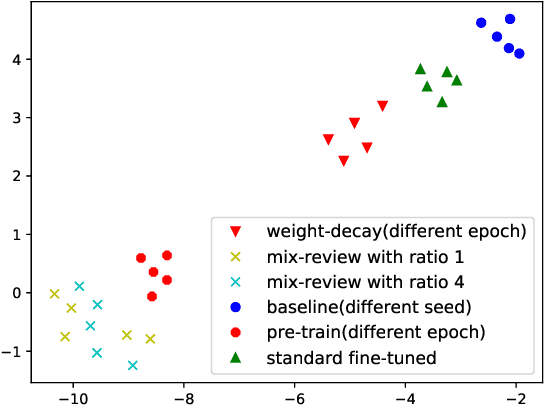
In this work, we study how the large-scale pretrain-finetune framework changes the behavior of a neural language generator. We focus on the transformer encoder-decoder model for the open-domain dialogue response generation task. We find that after standard fine-tuning, the model forgets important language generation skills acquired during large-scale pre-training. We demonstrate the forgetting phenomenon through a detailed behavior analysis from the perspectives of context sensitivity and knowledge transfer. Adopting the concept of data mixing, we propose an intuitive fine-tuning strategy named "mix-review". We find that mix-review effectively regularize the fine-tuning process, and the forgetting problem is largely alleviated. Finally, we discuss interesting behavior of the resulting dialogue model and its implications.
Capacity, Bandwidth, and Compositionality in Emergent Language Learning
Oct 24, 2019
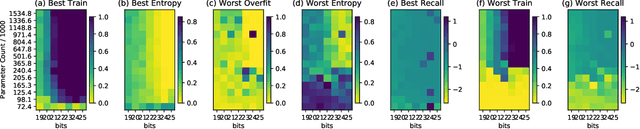
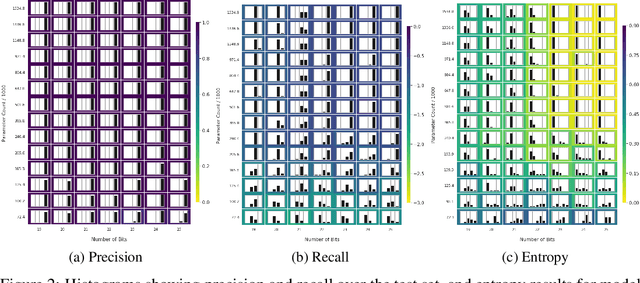
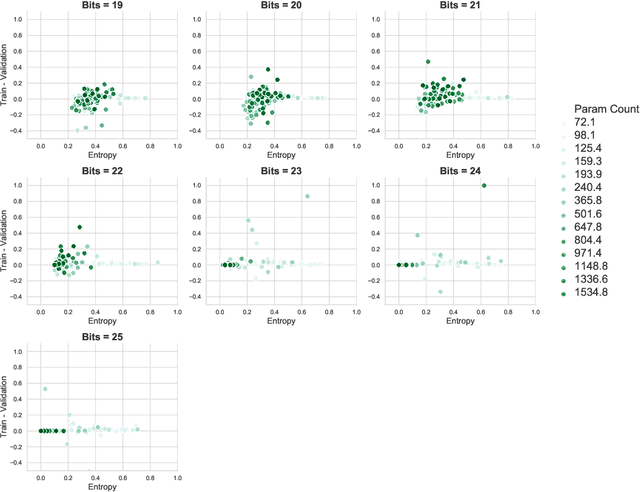
Many recent works have discussed the propensity, or lack thereof, for emergent languages to exhibit properties of natural languages. A favorite in the literature is learning compositionality. We note that most of those works have focused on communicative bandwidth as being of primary importance. While important, it is not the only contributing factor. In this paper, we investigate the learning biases that affect the efficacy and compositionality of emergent languages. Our foremost contribution is to explore how capacity of a neural network impacts its ability to learn a compositional language. We additionally introduce a set of evaluation metrics with which we analyze the learned languages. Our hypothesis is that there should be a specific range of model capacity and channel bandwidth that induces compositional structure in the resulting language and consequently encourages systematic generalization. While we empirically see evidence for the bottom of this range, we curiously do not find evidence for the top part of the range and believe that this is an open question for the community.
Generalized Inner Loop Meta-Learning
Oct 07, 2019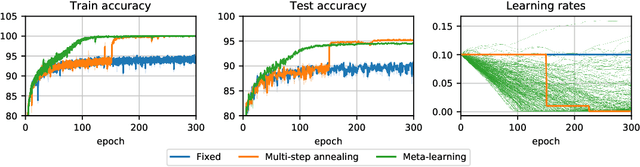

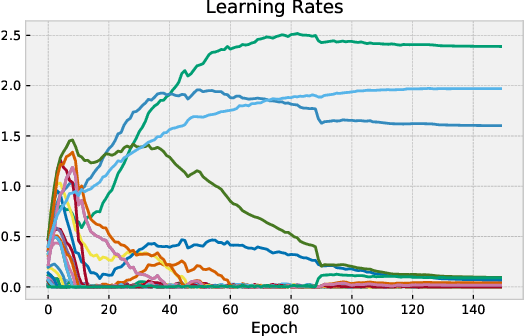
Many (but not all) approaches self-qualifying as "meta-learning" in deep learning and reinforcement learning fit a common pattern of approximating the solution to a nested optimization problem. In this paper, we give a formalization of this shared pattern, which we call GIMLI, prove its general requirements, and derive a general-purpose algorithm for implementing similar approaches. Based on this analysis and algorithm, we describe a library of our design, higher, which we share with the community to assist and enable future research into these kinds of meta-learning approaches. We end the paper by showcasing the practical applications of this framework and library through illustrative experiments and ablation studies which they facilitate.
Mixout: Effective Regularization to Finetune Large-scale Pretrained Language Models
Sep 25, 2019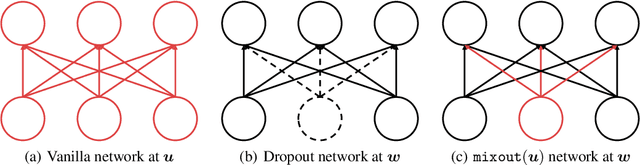
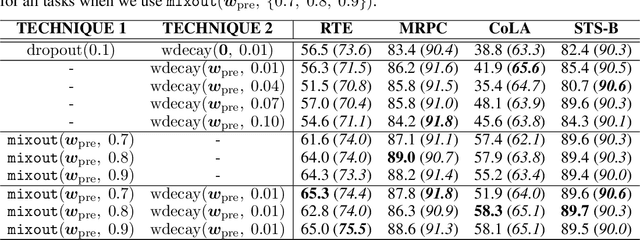
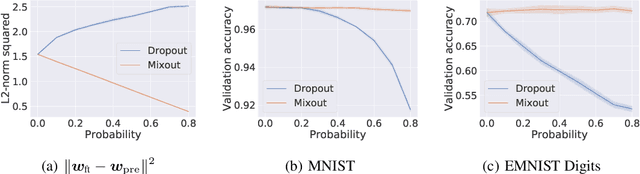
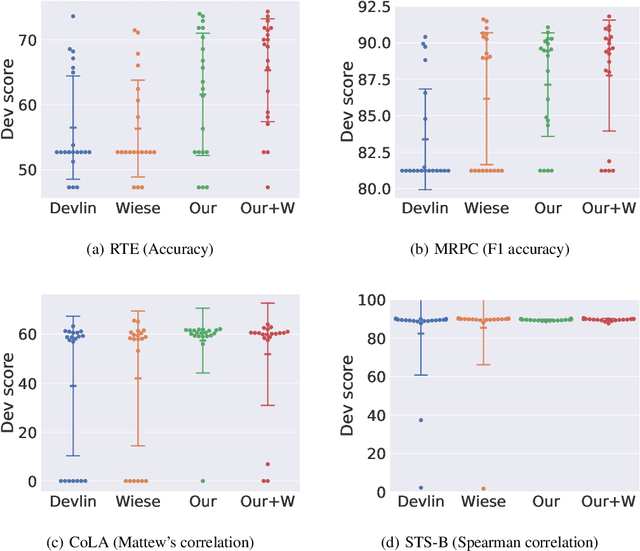
In natural language processing, it has been observed recently that generalization could be greatly improved by finetuning a large-scale language model pretrained on a large unlabeled corpus. Despite its recent success and wide adoption, finetuning a large pretrained language model on a downstream task is prone to degenerate performance when there are only a small number of training instances available. In this paper, we introduce a new regularization technique, to which we refer as "mixout", motivated by dropout. Mixout stochastically mixes the parameters of two models. We show that our mixout technique regularizes learning to minimize the deviation from one of the two models and that the strength of regularization adapts along the optimization trajectory. We empirically evaluate the proposed mixout and its variants on finetuning a pretrained language model on downstream tasks. More specifically, we demonstrate that the stability of finetuning and the average accuracy greatly increase when we use the proposed approach to regularize finetuning of BERT on downstream tasks in GLUE.