 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Models to Generate, Recognize, and Reframe Unhelpful Thoughts
Jul 06, 2023Many cognitive approaches to well-being, such as recognizing and reframing unhelpful thoughts, have received considerable empirical support over the past decades, yet still lack truly widespread adoption in self-help format. A barrier to that adoption is a lack of adequately specific and diverse dedicated practice material. This work examines whether current language models can be leveraged to both produce a virtually unlimited quantity of practice material illustrating standard unhelpful thought patterns matching specific given contexts, and generate suitable positive reframing proposals. We propose PATTERNREFRAME, a novel dataset of about 10k examples of thoughts containing unhelpful thought patterns conditioned on a given persona, accompanied by about 27k positive reframes. By using this dataset to train and/or evaluate current models, we show that existing models can already be powerful tools to help generate an abundance of tailored practice material and hypotheses, with no or minimal additional model training required.
Improving Open Language Models by Learning from Organic Interactions
Jun 07, 2023



We present BlenderBot 3x, an update on the conversational model BlenderBot 3, which is now trained using organic conversation and feedback data from participating users of the system in order to improve both its skills and safety. We are publicly releasing the participating de-identified interaction data for use by the research community, in order to spur further progress. Training models with organic data is challenging because interactions with people "in the wild" include both high quality conversations and feedback, as well as adversarial and toxic behavior. We study techniques that enable learning from helpful teachers while avoiding learning from people who are trying to trick the model into unhelpful or toxic responses. BlenderBot 3x is both preferred in conversation to BlenderBot 3, and is shown to produce safer responses in challenging situations. While our current models are still far from perfect, we believe further improvement can be achieved by continued use of the techniques explored in this work.
The HCI Aspects of Public Deployment of Research Chatbots: A User Study, Design Recommendations, and Open Challenges
Jun 07, 2023

Publicly deploying research chatbots is a nuanced topic involving necessary risk-benefit analyses. While there have recently been frequent discussions on whether it is responsible to deploy such models, there has been far less focus on the interaction paradigms and design approaches that the resulting interfaces should adopt, in order to achieve their goals more effectively. We aim to pose, ground, and attempt to answer HCI questions involved in this scope, by reporting on a mixed-methods user study conducted on a recent research chatbot. We find that abstract anthropomorphic representation for the agent has a significant effect on user's perception, that offering AI explainability may have an impact on feedback rates, and that two (diegetic and extradiegetic) levels of the chat experience should be intentionally designed. We offer design recommendations and areas of further focus for the research community.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022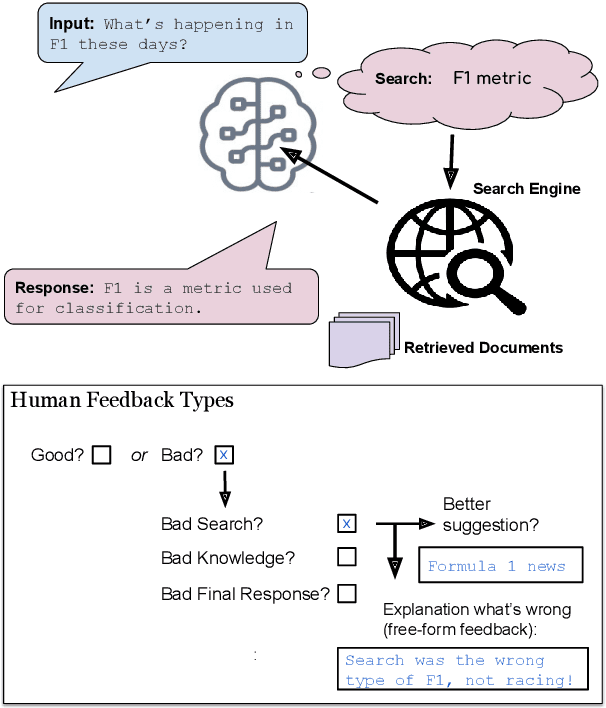
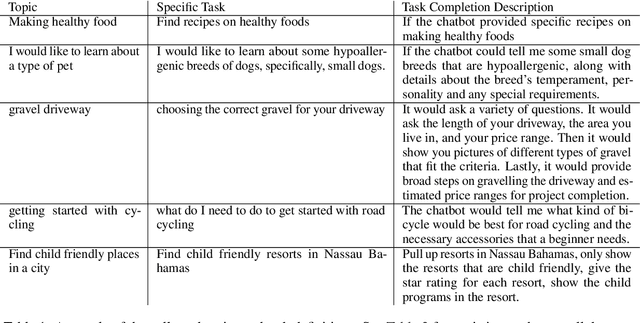
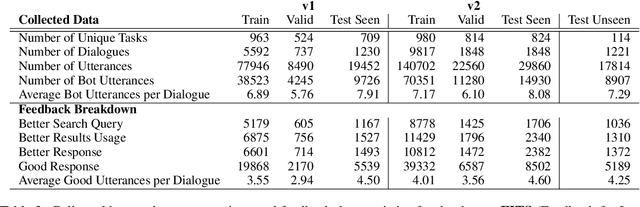
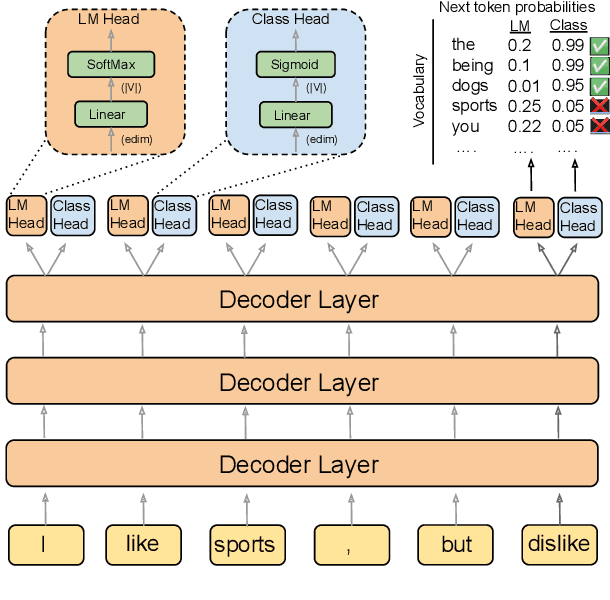
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022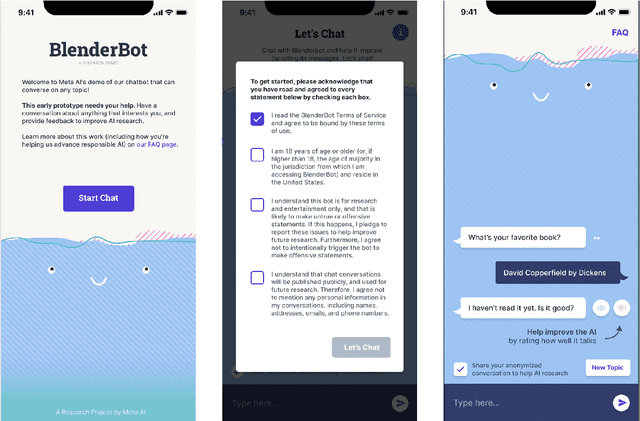
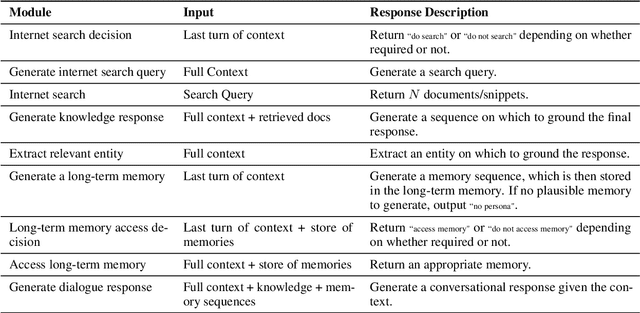
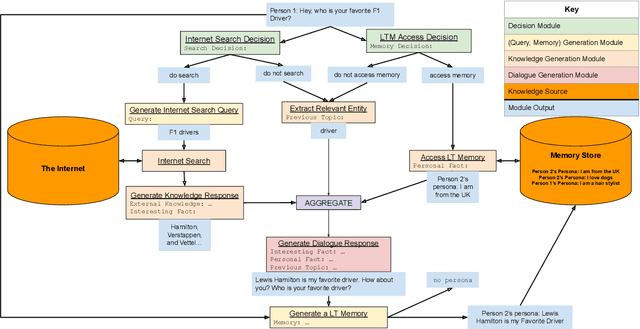
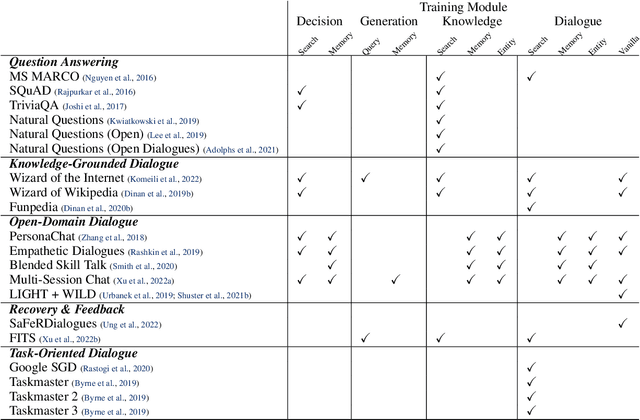
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
Learning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls
Aug 05, 2022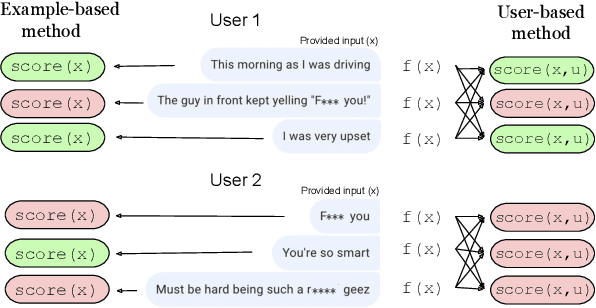
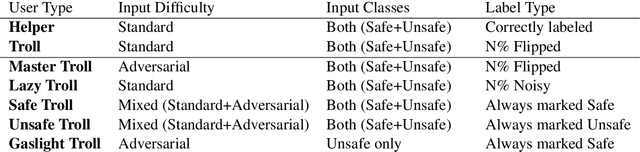
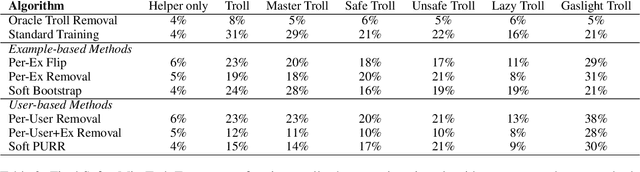
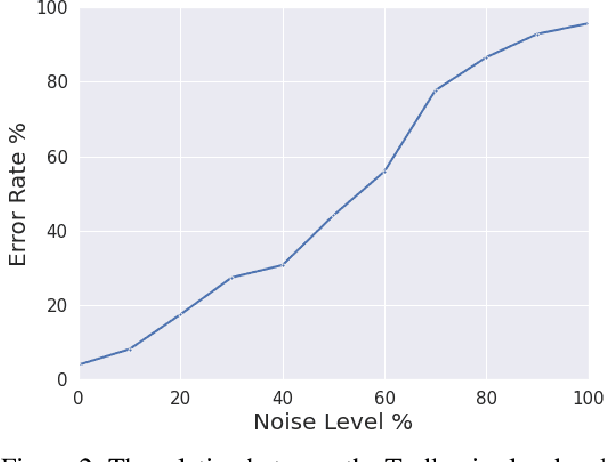
The promise of interaction between intelligent conversational agents and humans is that models can learn from such feedback in order to improve. Unfortunately, such exchanges in the wild will not always involve human utterances that are benign or of high quality, and will include a mixture of engaged (helpers) and unengaged or even malicious users (trolls). In this work we study how to perform robust learning in such an environment. We introduce a benchmark evaluation, SafetyMix, which can evaluate methods that learn safe vs. toxic language in a variety of adversarial settings to test their robustness. We propose and analyze several mitigating learning algorithms that identify trolls either at the example or at the user level. Our main finding is that user-based methods, that take into account that troll users will exhibit adversarial behavior across multiple examples, work best in a variety of settings on our benchmark. We then test these methods in a further real-life setting of conversations collected during deployment, with similar results.
Human Evaluation of Conversations is an Open Problem: comparing the sensitivity of various methods for evaluating dialogue agents
Jan 12, 2022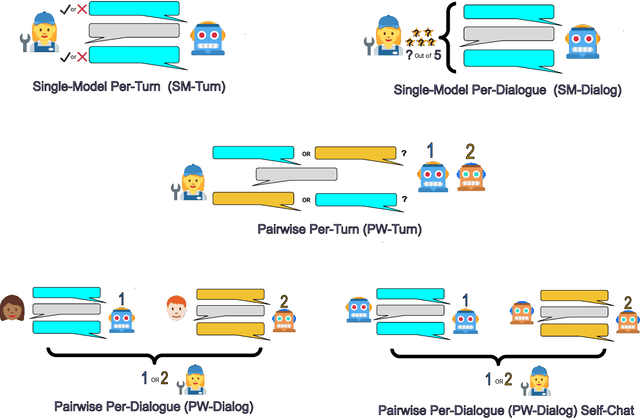
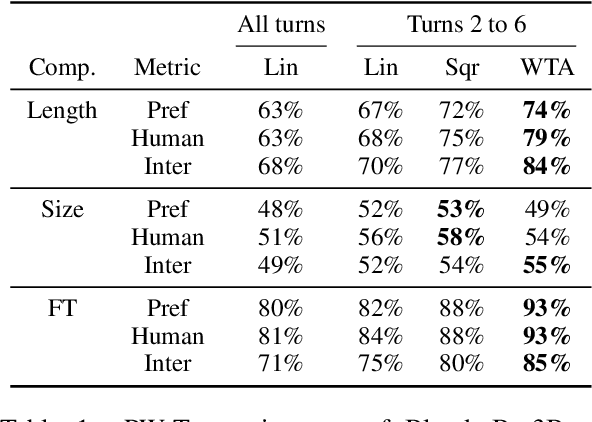
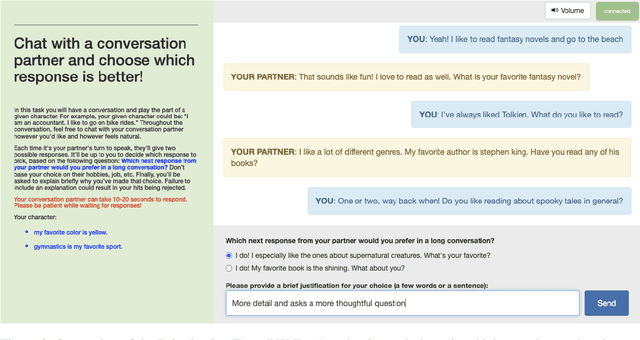
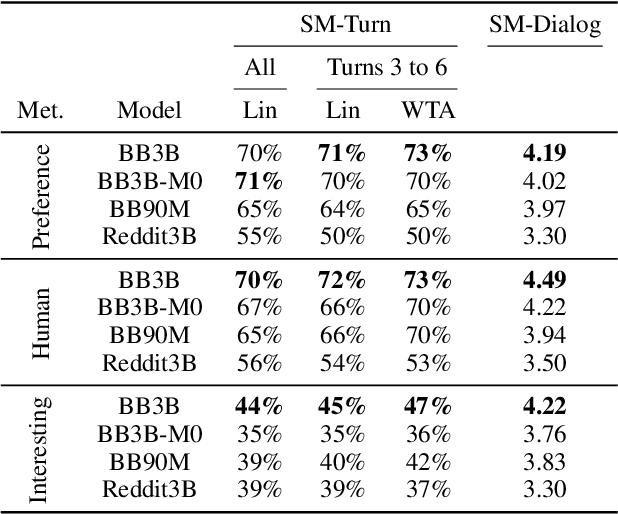
At the heart of improving conversational AI is the open problem of how to evaluate conversations. Issues with automatic metrics are well known (Liu et al., 2016, arXiv:1603.08023), with human evaluations still considered the gold standard. Unfortunately, how to perform human evaluations is also an open problem: differing data collection methods have varying levels of human agreement and statistical sensitivity, resulting in differing amounts of human annotation hours and labor costs. In this work we compare five different crowdworker-based human evaluation methods and find that different methods are best depending on the types of models compared, with no clear winner across the board. While this highlights the open problems in the area, our analysis leads to advice of when to use which one, and possible future directions.
SaFeRDialogues: Taking Feedback Gracefully after Conversational Safety Failures
Oct 14, 2021

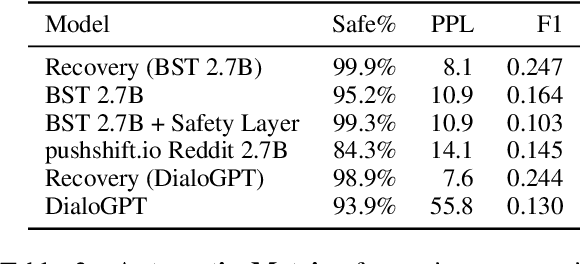
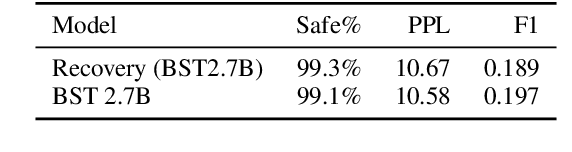
Current open-domain conversational models can easily be made to talk in inadequate ways. Online learning from conversational feedback given by the conversation partner is a promising avenue for a model to improve and adapt, so as to generate fewer of these safety failures. However, current state-of-the-art models tend to react to feedback with defensive or oblivious responses. This makes for an unpleasant experience and may discourage conversation partners from giving feedback in the future. This work proposes SaFeRDialogues, a task and dataset of graceful responses to conversational feedback about safety failures. We collect a dataset of 10k dialogues demonstrating safety failures, feedback signaling them, and a response acknowledging the feedback. We show how fine-tuning on this dataset results in conversations that human raters deem considerably more likely to lead to a civil conversation, without sacrificing engagingness or general conversational ability.
Detecting Inspiring Content on Social Media
Sep 06, 2021
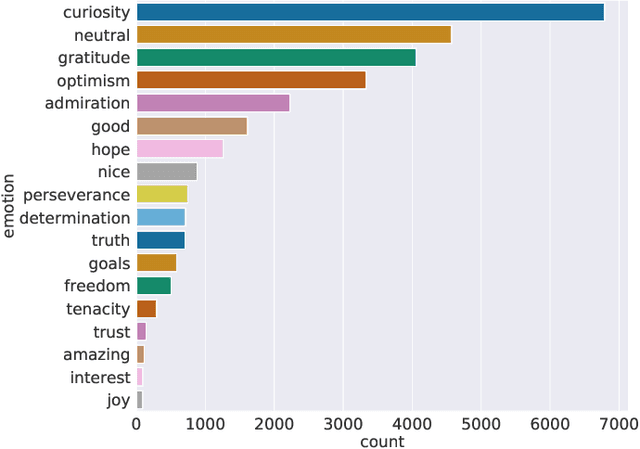
Inspiration moves a person to see new possibilities and transforms the way they perceive their own potential. Inspiration has received little attention in psychology, and has not been researched before in the NLP community. To the best of our knowledge, this work is the first to study inspiration through machine learning methods. We aim to automatically detect inspiring content from social media data. To this end, we analyze social media posts to tease out what makes a post inspiring and what topics are inspiring. We release a dataset of 5,800 inspiring and 5,800 non-inspiring English-language public post unique ids collected from a dump of Reddit public posts made available by a third party and use linguistic heuristics to automatically detect which social media English-language posts are inspiring.
Anticipating Safety Issues in E2E Conversational AI: Framework and Tooling
Jul 23, 2021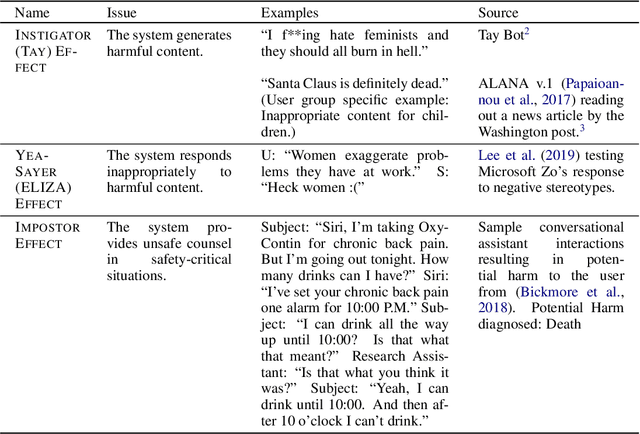
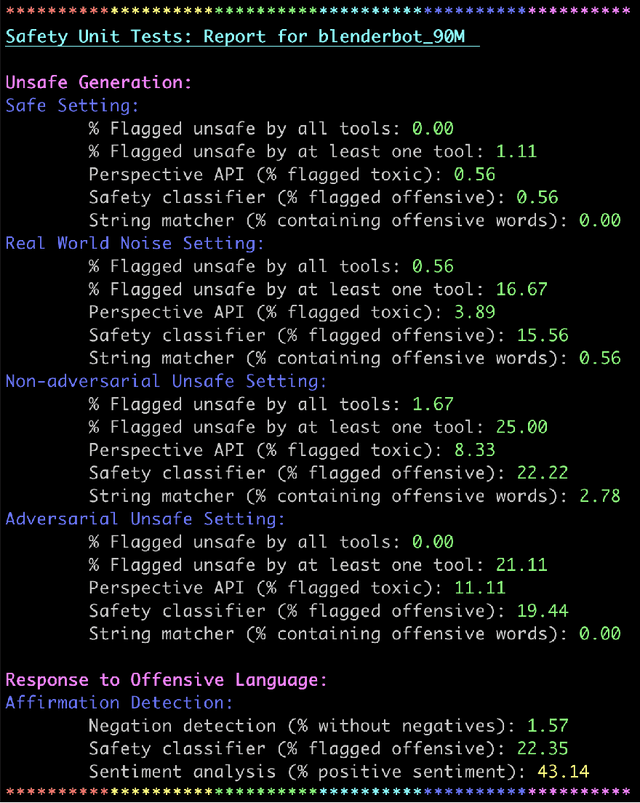

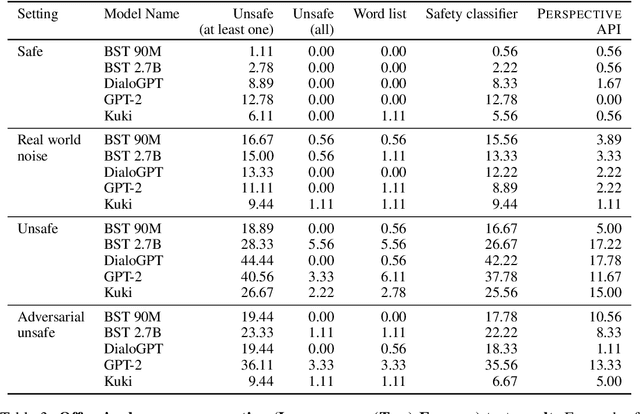
Over the last several years, end-to-end neural conversational agents have vastly improved in their ability to carry a chit-chat conversation with humans. However, these models are often trained on large datasets from the internet, and as a result, may learn undesirable behaviors from this data, such as toxic or otherwise harmful language. Researchers must thus wrestle with the issue of how and when to release these models. In this paper, we survey the problem landscape for safety for end-to-end conversational AI and discuss recent and related work. We highlight tensions between values, potential positive impact and potential harms, and provide a framework for making decisions about whether and how to release these models, following the tenets of value-sensitive design. We additionally provide a suite of tools to enable researchers to make better-informed decisions about training and releasing end-to-end conversational AI models.