 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.
K-Sort Arena: Efficient and Reliable Benchmarking for Generative Models via K-wise Human Preferences
Aug 26, 2024



The rapid advancement of visual generative models necessitates efficient and reliable evaluation methods. Arena platform, which gathers user votes on model comparisons, can rank models with human preferences. However, traditional Arena methods, while established, require an excessive number of comparisons for ranking to converge and are vulnerable to preference noise in voting, suggesting the need for better approaches tailored to contemporary evaluation challenges. In this paper, we introduce K-Sort Arena, an efficient and reliable platform based on a key insight: images and videos possess higher perceptual intuitiveness than texts, enabling rapid evaluation of multiple samples simultaneously. Consequently, K-Sort Arena employs K-wise comparisons, allowing K models to engage in free-for-all competitions, which yield much richer information than pairwise comparisons. To enhance the robustness of the system, we leverage probabilistic modeling and Bayesian updating techniques. We propose an exploration-exploitation-based matchmaking strategy to facilitate more informative comparisons. In our experiments, K-Sort Arena exhibits 16.3x faster convergence compared to the widely used ELO algorithm. To further validate the superiority and obtain a comprehensive leaderboard, we collect human feedback via crowdsourced evaluations of numerous cutting-edge text-to-image and text-to-video models. Thanks to its high efficiency, K-Sort Arena can continuously incorporate emerging models and update the leaderboard with minimal votes. Our project has undergone several months of internal testing and is now available at https://huggingface.co/spaces/ksort/K-Sort-Arena
FactorLLM: Factorizing Knowledge via Mixture of Experts for Large Language Models
Aug 15, 2024



Recent research has demonstrated that Feed-Forward Networks (FFNs) in Large Language Models (LLMs) play a pivotal role in storing diverse linguistic and factual knowledge. Conventional methods frequently face challenges due to knowledge confusion stemming from their monolithic and redundant architectures, which calls for more efficient solutions with minimal computational overhead, particularly for LLMs. In this paper, we explore the FFN computation paradigm in LLMs and introduce FactorLLM, a novel approach that decomposes well-trained dense FFNs into sparse sub-networks without requiring any further modifications, while maintaining the same level of performance. Furthermore, we embed a router from the Mixture-of-Experts (MoE), combined with our devised Prior-Approximate (PA) loss term that facilitates the dynamic activation of experts and knowledge adaptation, thereby accelerating computational processes and enhancing performance using minimal training data and fine-tuning steps. FactorLLM thus enables efficient knowledge factorization and activates select groups of experts specifically tailored to designated tasks, emulating the interactive functional segmentation of the human brain. Extensive experiments across various benchmarks demonstrate the effectiveness of our proposed FactorLLM which achieves comparable performance to the source model securing up to 85% model performance while obtaining over a 30% increase in inference speed. Code: https://github.com/zhenwuweihe/FactorLLM.
Sparse Refinement for Efficient High-Resolution Semantic Segmentation
Jul 26, 2024Semantic segmentation empowers numerous real-world applications, such as autonomous driving and augmented/mixed reality. These applications often operate on high-resolution images (e.g., 8 megapixels) to capture the fine details. However, this comes at the cost of considerable computational complexity, hindering the deployment in latency-sensitive scenarios. In this paper, we introduce SparseRefine, a novel approach that enhances dense low-resolution predictions with sparse high-resolution refinements. Based on coarse low-resolution outputs, SparseRefine first uses an entropy selector to identify a sparse set of pixels with high entropy. It then employs a sparse feature extractor to efficiently generate the refinements for those pixels of interest. Finally, it leverages a gated ensembler to apply these sparse refinements to the initial coarse predictions. SparseRefine can be seamlessly integrated into any existing semantic segmentation model, regardless of CNN- or ViT-based. SparseRefine achieves significant speedup: 1.5 to 3.7 times when applied to HRNet-W48, SegFormer-B5, Mask2Former-T/L and SegNeXt-L on Cityscapes, with negligible to no loss of accuracy. Our "dense+sparse" paradigm paves the way for efficient high-resolution visual computing.
Sharpness-diversity tradeoff: improving flat ensembles with SharpBalance
Jul 17, 2024



Recent studies on deep ensembles have identified the sharpness of the local minima of individual learners and the diversity of the ensemble members as key factors in improving test-time performance. Building on this, our study investigates the interplay between sharpness and diversity within deep ensembles, illustrating their crucial role in robust generalization to both in-distribution (ID) and out-of-distribution (OOD) data. We discover a trade-off between sharpness and diversity: minimizing the sharpness in the loss landscape tends to diminish the diversity of individual members within the ensemble, adversely affecting the ensemble's improvement. The trade-off is justified through our theoretical analysis and verified empirically through extensive experiments. To address the issue of reduced diversity, we introduce SharpBalance, a novel training approach that balances sharpness and diversity within ensembles. Theoretically, we show that our training strategy achieves a better sharpness-diversity trade-off. Empirically, we conducted comprehensive evaluations in various data sets (CIFAR-10, CIFAR-100, TinyImageNet) and showed that SharpBalance not only effectively improves the sharpness-diversity trade-off, but also significantly improves ensemble performance in ID and OOD scenarios.
Characterizing Prompt Compression Methods for Long Context Inference
Jul 11, 2024
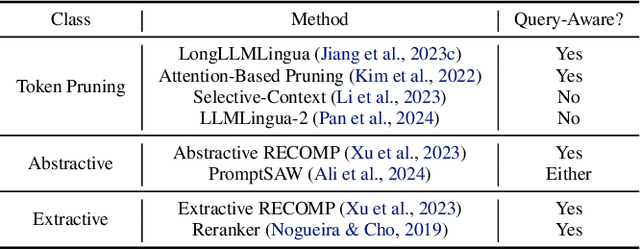
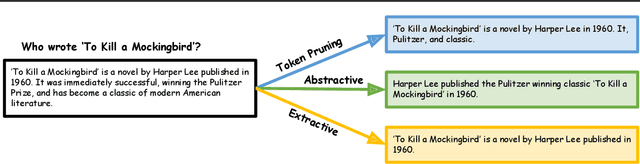

Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.
Fisher-aware Quantization for DETR Detectors with Critical-category Objectives
Jul 03, 2024



The impact of quantization on the overall performance of deep learning models is a well-studied problem. However, understanding and mitigating its effects on a more fine-grained level is still lacking, especially for harder tasks such as object detection with both classification and regression objectives. This work defines the performance for a subset of task-critical categories, i.e. the critical-category performance, as a crucial yet largely overlooked fine-grained objective for detection tasks. We analyze the impact of quantization at the category-level granularity, and propose methods to improve performance for the critical categories. Specifically, we find that certain critical categories have a higher sensitivity to quantization, and are prone to overfitting after quantization-aware training (QAT). To explain this, we provide theoretical and empirical links between their performance gaps and the corresponding loss landscapes with the Fisher information framework. Using this evidence, we apply a Fisher-aware mixed-precision quantization scheme, and a Fisher-trace regularization for the QAT on the critical-category loss landscape. The proposed methods improve critical-category metrics of the quantized transformer-based DETR detectors. They are even more significant in case of larger models and higher number of classes where the overfitting becomes more severe. For example, our methods lead to 10.4% and 14.5% mAP gains for, correspondingly, 4-bit DETR-R50 and Deformable DETR on the most impacted critical classes in the COCO Panoptic dataset.
Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment
Jun 18, 2024In this paper, we point out suboptimal noise-data mapping leads to slow training of diffusion models. During diffusion training, current methods diffuse each image across the entire noise space, resulting in a mixture of all images at every point in the noise layer. We emphasize that this random mixture of noise-data mapping complicates the optimization of the denoising function in diffusion models. Drawing inspiration from the immiscible phenomenon in physics, we propose Immiscible Diffusion, a simple and effective method to improve the random mixture of noise-data mapping. In physics, miscibility can vary according to various intermolecular forces. Thus, immiscibility means that the mixing of the molecular sources is distinguishable. Inspired by this, we propose an assignment-then-diffusion training strategy. Specifically, prior to diffusing the image data into noise, we assign diffusion target noise for the image data by minimizing the total image-noise pair distance in a mini-batch. The assignment functions analogously to external forces to separate the diffuse-able areas of images, thus mitigating the inherent difficulties in diffusion training. Our approach is remarkably simple, requiring only one line of code to restrict the diffuse-able area for each image while preserving the Gaussian distribution of noise. This ensures that each image is projected only to nearby noise. To address the high complexity of the assignment algorithm, we employ a quantized-assignment method to reduce the computational overhead to a negligible level. Experiments demonstrate that our method achieve up to 3x faster training for consistency models and DDIM on the CIFAR dataset, and up to 1.3x faster on CelebA datasets for consistency models. Besides, we conduct thorough analysis about the Immiscible Diffusion, which sheds lights on how it improves diffusion training speed while improving the fidelity.
Instruct Large Language Models to Drive like Humans
Jun 11, 2024



Motion planning in complex scenarios is the core challenge in autonomous driving. Conventional methods apply predefined rules or learn from driving data to plan the future trajectory. Recent methods seek the knowledge preserved in large language models (LLMs) and apply them in the driving scenarios. Despite the promising results, it is still unclear whether the LLM learns the underlying human logic to drive. In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. We derive driving instruction data based on human logic (e.g., do not cause collisions) and traffic rules (e.g., proceed only when green lights). We then employ an interpretable InstructChain module to further reason the final planning reflecting the instructions. Our InstructDriver allows the injection of human rules and learning from driving data, enabling both interpretability and data scalability. Different from existing methods that experimented on closed-loop or simulated settings, we adopt the real-world closed-loop motion planning nuPlan benchmark for better evaluation. InstructDriver demonstrates the effectiveness of the LLM planner in a real-world closed-loop setting. Our code is publicly available at https://github.com/bonbon-rj/InstructDriver.
$\textit{S}^3$Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
May 30, 2024



Photorealistic 3D reconstruction of street scenes is a critical technique for developing real-world simulators for autonomous driving. Despite the efficacy of Neural Radiance Fields (NeRF) for driving scenes, 3D Gaussian Splatting (3DGS) emerges as a promising direction due to its faster speed and more explicit representation. However, most existing street 3DGS methods require tracked 3D vehicle bounding boxes to decompose the static and dynamic elements for effective reconstruction, limiting their applications for in-the-wild scenarios. To facilitate efficient 3D scene reconstruction without costly annotations, we propose a self-supervised street Gaussian ($\textit{S}^3$Gaussian) method to decompose dynamic and static elements from 4D consistency. We represent each scene with 3D Gaussians to preserve the explicitness and further accompany them with a spatial-temporal field network to compactly model the 4D dynamics. We conduct extensive experiments on the challenging Waymo-Open dataset to evaluate the effectiveness of our method. Our $\textit{S}^3$Gaussian demonstrates the ability to decompose static and dynamic scenes and achieves the best performance without using 3D annotations. Code is available at: https://github.com/nnanhuang/S3Gaussian/.