 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
Nov 10, 2025



Generative models are reshaping the live-streaming industry by redefining how content is created, styled, and delivered. Previous image-based streaming diffusion models have powered efficient and creative live streaming products but have hit limits on temporal consistency due to the foundation of image-based designs. Recent advances in video diffusion have markedly improved temporal consistency and sampling efficiency for offline generation. However, offline generation systems primarily optimize throughput by batching large workloads. In contrast, live online streaming operates under strict service-level objectives (SLOs): time-to-first-frame must be minimal, and every frame must meet a per-frame deadline with low jitter. Besides, scalable multi-GPU serving for real-time streams remains largely unresolved so far. To address this, we present StreamDiffusionV2, a training-free pipeline for interactive live streaming with video diffusion models. StreamDiffusionV2 integrates an SLO-aware batching scheduler and a block scheduler, together with a sink-token--guided rolling KV cache, a motion-aware noise controller, and other system-level optimizations. Moreover, we introduce a scalable pipeline orchestration that parallelizes the diffusion process across denoising steps and network layers, achieving near-linear FPS scaling without violating latency guarantees. The system scales seamlessly across heterogeneous GPU environments and supports flexible denoising steps (e.g., 1--4), enabling both ultra-low-latency and higher-quality modes. Without TensorRT or quantization, StreamDiffusionV2 renders the first frame within 0.5s and attains 58.28 FPS with a 14B-parameter model and 64.52 FPS with a 1.3B-parameter model on four H100 GPUs, making state-of-the-art generative live streaming practical and accessible--from individual creators to enterprise-scale platforms.
Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment
Jun 18, 2024In this paper, we point out suboptimal noise-data mapping leads to slow training of diffusion models. During diffusion training, current methods diffuse each image across the entire noise space, resulting in a mixture of all images at every point in the noise layer. We emphasize that this random mixture of noise-data mapping complicates the optimization of the denoising function in diffusion models. Drawing inspiration from the immiscible phenomenon in physics, we propose Immiscible Diffusion, a simple and effective method to improve the random mixture of noise-data mapping. In physics, miscibility can vary according to various intermolecular forces. Thus, immiscibility means that the mixing of the molecular sources is distinguishable. Inspired by this, we propose an assignment-then-diffusion training strategy. Specifically, prior to diffusing the image data into noise, we assign diffusion target noise for the image data by minimizing the total image-noise pair distance in a mini-batch. The assignment functions analogously to external forces to separate the diffuse-able areas of images, thus mitigating the inherent difficulties in diffusion training. Our approach is remarkably simple, requiring only one line of code to restrict the diffuse-able area for each image while preserving the Gaussian distribution of noise. This ensures that each image is projected only to nearby noise. To address the high complexity of the assignment algorithm, we employ a quantized-assignment method to reduce the computational overhead to a negligible level. Experiments demonstrate that our method achieve up to 3x faster training for consistency models and DDIM on the CIFAR dataset, and up to 1.3x faster on CelebA datasets for consistency models. Besides, we conduct thorough analysis about the Immiscible Diffusion, which sheds lights on how it improves diffusion training speed while improving the fidelity.
Looking Backward: Streaming Video-to-Video Translation with Feature Banks
May 24, 2024



This paper introduces StreamV2V, a diffusion model that achieves real-time streaming video-to-video (V2V) translation with user prompts. Unlike prior V2V methods using batches to process limited frames, we opt to process frames in a streaming fashion, to support unlimited frames. At the heart of StreamV2V lies a backward-looking principle that relates the present to the past. This is realized by maintaining a feature bank, which archives information from past frames. For incoming frames, StreamV2V extends self-attention to include banked keys and values and directly fuses similar past features into the output. The feature bank is continually updated by merging stored and new features, making it compact but informative. StreamV2V stands out for its adaptability and efficiency, seamlessly integrating with image diffusion models without fine-tuning. It can run 20 FPS on one A100 GPU, being 15x, 46x, 108x, and 158x faster than FlowVid, CoDeF, Rerender, and TokenFlow, respectively. Quantitative metrics and user studies confirm StreamV2V's exceptional ability to maintain temporal consistency.
StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
Dec 19, 2023We introduce StreamDiffusion, a real-time diffusion pipeline designed for interactive image generation. Existing diffusion models are adept at creating images from text or image prompts, yet they often fall short in real-time interaction. This limitation becomes particularly evident in scenarios involving continuous input, such as Metaverse, live video streaming, and broadcasting, where high throughput is imperative. To address this, we present a novel approach that transforms the original sequential denoising into the batching denoising process. Stream Batch eliminates the conventional wait-and-interact approach and enables fluid and high throughput streams. To handle the frequency disparity between data input and model throughput, we design a novel input-output queue for parallelizing the streaming process. Moreover, the existing diffusion pipeline uses classifier-free guidance(CFG), which requires additional U-Net computation. To mitigate the redundant computations, we propose a novel residual classifier-free guidance (RCFG) algorithm that reduces the number of negative conditional denoising steps to only one or even zero. Besides, we introduce a stochastic similarity filter(SSF) to optimize power consumption. Our Stream Batch achieves around 1.5x speedup compared to the sequential denoising method at different denoising levels. The proposed RCFG leads to speeds up to 2.05x higher than the conventional CFG. Combining the proposed strategies and existing mature acceleration tools makes the image-to-image generation achieve up-to 91.07fps on one RTX4090, improving the throughputs of AutoPipline developed by Diffusers over 59.56x. Furthermore, our proposed StreamDiffusion also significantly reduces the energy consumption by 2.39x on one RTX3060 and 1.99x on one RTX4090, respectively.
SST-Calib: Simultaneous Spatial-Temporal Parameter Calibration between LIDAR and Camera
Jul 08, 2022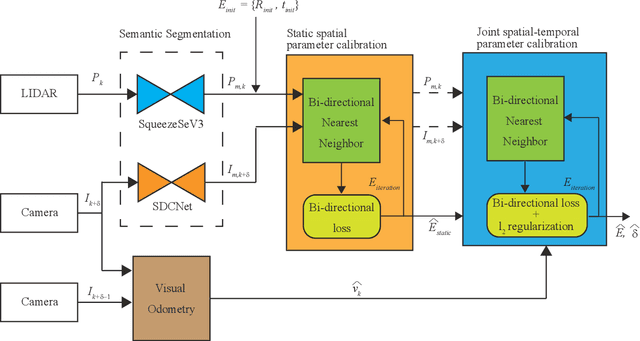
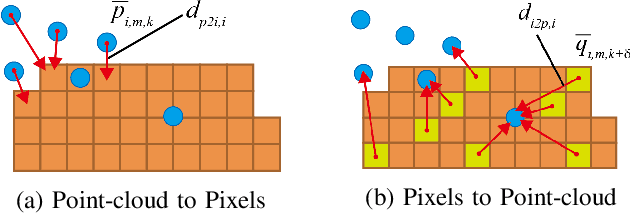

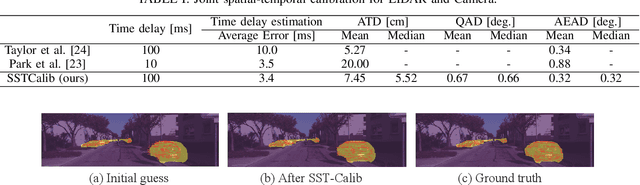
With information from multiple input modalities, sensor fusion-based algorithms usually out-perform their single-modality counterparts in robotics. Camera and LIDAR, with complementary semantic and depth information, are the typical choices for detection tasks in complicated driving environments. For most camera-LIDAR fusion algorithms, however, the calibration of the sensor suite will greatly impact the performance. More specifically, the detection algorithm usually requires an accurate geometric relationship among multiple sensors as the input, and it is often assumed that the contents from these sensors are captured at the same time. Preparing such sensor suites involves carefully designed calibration rigs and accurate synchronization mechanisms, and the preparation process is usually done offline. In this work, a segmentation-based framework is proposed to jointly estimate the geometrical and temporal parameters in the calibration of a camera-LIDAR suite. A semantic segmentation mask is first applied to both sensor modalities, and the calibration parameters are optimized through pixel-wise bidirectional loss. We specifically incorporated the velocity information from optical flow for temporal parameters. Since supervision is only performed at the segmentation level, no calibration label is needed within the framework. The proposed algorithm is tested on the KITTI dataset, and the result shows an accurate real-time calibration of both geometric and temporal parameters.