 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePONI: Potential Functions for ObjectGoal Navigation with Interaction-free Learning
Jan 25, 2022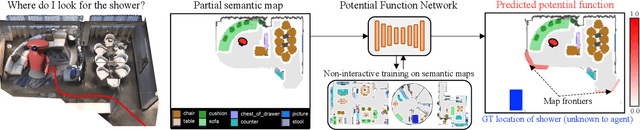
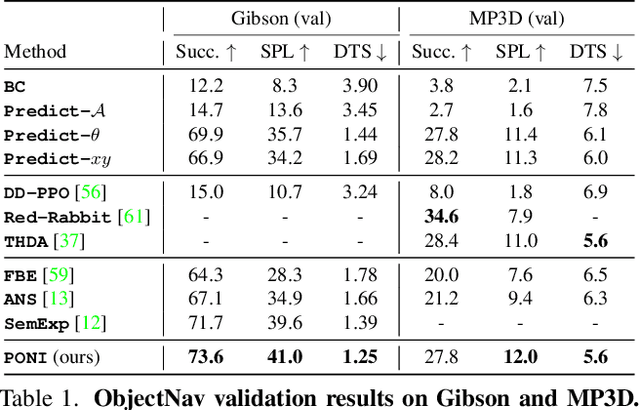
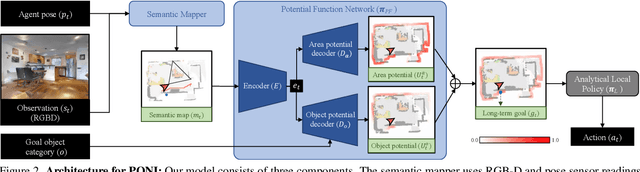
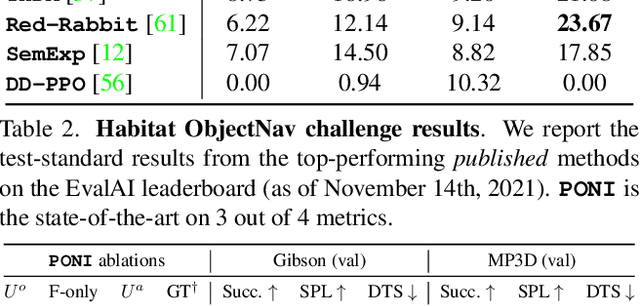
State-of-the-art approaches to ObjectGoal navigation rely on reinforcement learning and typically require significant computational resources and time for learning. We propose Potential functions for ObjectGoal Navigation with Interaction-free learning (PONI), a modular approach that disentangles the skills of `where to look?' for an object and `how to navigate to (x, y)?'. Our key insight is that `where to look?' can be treated purely as a perception problem, and learned without environment interactions. To address this, we propose a network that predicts two complementary potential functions conditioned on a semantic map and uses them to decide where to look for an unseen object. We train the potential function network using supervised learning on a passive dataset of top-down semantic maps, and integrate it into a modular framework to perform ObjectGoal navigation. Experiments on Gibson and Matterport3D demonstrate that our method achieves the state-of-the-art for ObjectGoal navigation while incurring up to 1,600x less computational cost for training.
Geometry-Aware Multi-Task Learning for Binaural Audio Generation from Video
Nov 21, 2021
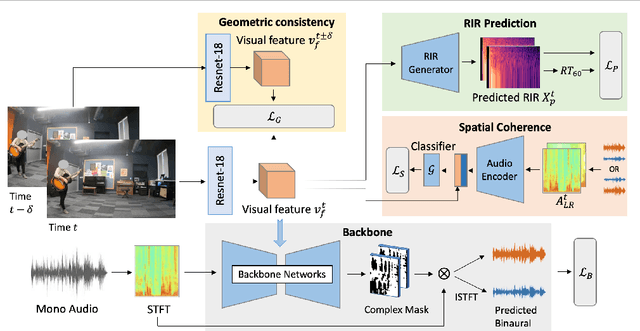
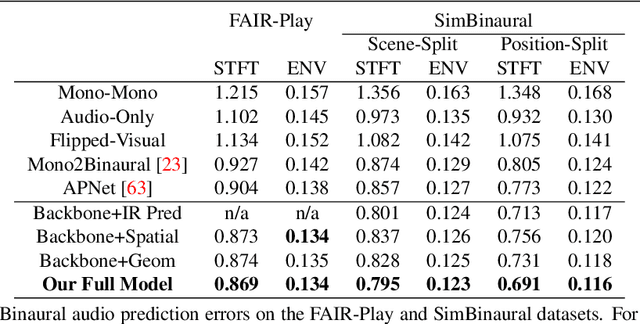

Binaural audio provides human listeners with an immersive spatial sound experience, but most existing videos lack binaural audio recordings. We propose an audio spatialization method that draws on visual information in videos to convert their monaural (single-channel) audio to binaural audio. Whereas existing approaches leverage visual features extracted directly from video frames, our approach explicitly disentangles the geometric cues present in the visual stream to guide the learning process. In particular, we develop a multi-task framework that learns geometry-aware features for binaural audio generation by accounting for the underlying room impulse response, the visual stream's coherence with the sound source(s) positions, and the consistency in geometry of the sounding objects over time. Furthermore, we introduce a new large video dataset with realistic binaural audio simulated for real-world scanned environments. On two datasets, we demonstrate the efficacy of our method, which achieves state-of-the-art results.
Shaping embodied agent behavior with activity-context priors from egocentric video
Oct 14, 2021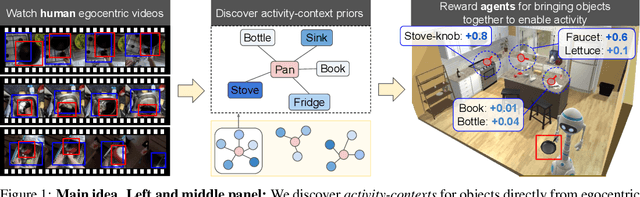


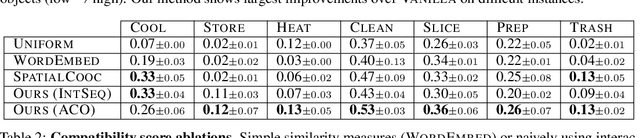
Complex physical tasks entail a sequence of object interactions, each with its own preconditions -- which can be difficult for robotic agents to learn efficiently solely through their own experience. We introduce an approach to discover activity-context priors from in-the-wild egocentric video captured with human worn cameras. For a given object, an activity-context prior represents the set of other compatible objects that are required for activities to succeed (e.g., a knife and cutting board brought together with a tomato are conducive to cutting). We encode our video-based prior as an auxiliary reward function that encourages an agent to bring compatible objects together before attempting an interaction. In this way, our model translates everyday human experience into embodied agent skills. We demonstrate our idea using egocentric EPIC-Kitchens video of people performing unscripted kitchen activities to benefit virtual household robotic agents performing various complex tasks in AI2-iTHOR, significantly accelerating agent learning. Project page: http://vision.cs.utexas.edu/projects/ego-rewards/
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Shapes as Product Differentiation: Neural Network Embedding in the Analysis of Markets for Fonts
Jul 06, 2021


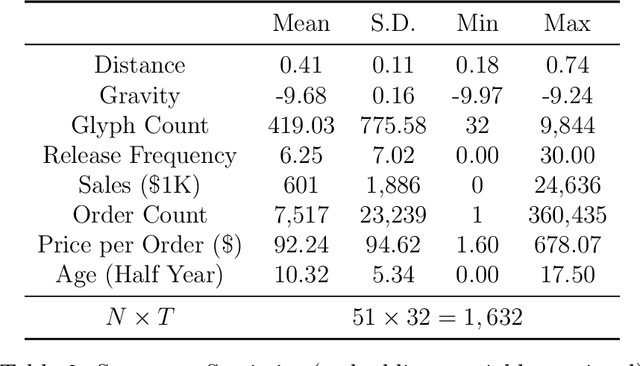
Many differentiated products have key attributes that are unstructured and thus high-dimensional (e.g., design, text). Instead of treating unstructured attributes as unobservables in economic models, quantifying them can be important to answer interesting economic questions. To propose an analytical framework for this type of products, this paper considers one of the simplest design products -- fonts -- and investigates merger and product differentiation using an original dataset from the world's largest online marketplace for fonts. We quantify font shapes by constructing embeddings from a deep convolutional neural network. Each embedding maps a font's shape onto a low-dimensional vector. In the resulting product space, designers are assumed to engage in Hotelling-type spatial competition. From the image embeddings, we construct two alternative measures that capture the degree of design differentiation. We then study the causal effects of a merger on the merging firm's creative decisions using the constructed measures in a synthetic control method. We find that the merger causes the merging firm to increase the visual variety of font design. Notably, such effects are not captured when using traditional measures for product offerings (e.g., specifications and the number of products) constructed from structured data.
Learning Audio-Visual Dereverberation
Jun 14, 2021
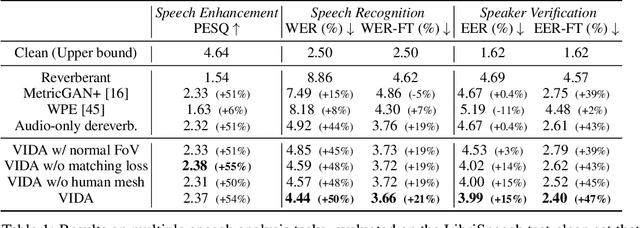

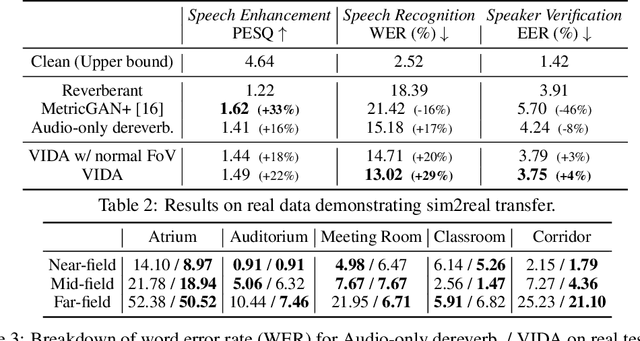
Reverberation from audio reflecting off surfaces and objects in the environment not only degrades the quality of speech for human perception, but also severely impacts the accuracy of automatic speech recognition. Prior work attempts to remove reverberation based on the audio modality only. Our idea is to learn to dereverberate speech from audio-visual observations. The visual environment surrounding a human speaker reveals important cues about the room geometry, materials, and speaker location, all of which influence the precise reverberation effects in the audio stream. We introduce Visually-Informed Dereverberation of Audio (VIDA), an end-to-end approach that learns to remove reverberation based on both the observed sounds and visual scene. In support of this new task, we develop a large-scale dataset that uses realistic acoustic renderings of speech in real-world 3D scans of homes offering a variety of room acoustics. Demonstrating our approach on both simulated and real imagery for speech enhancement, speech recognition, and speaker identification, we show it achieves state-of-the-art performance and substantially improves over traditional audio-only methods. Project page: http://vision.cs.utexas.edu/projects/learning-audio-visual-dereverberation.
Anticipative Video Transformer
Jun 03, 2021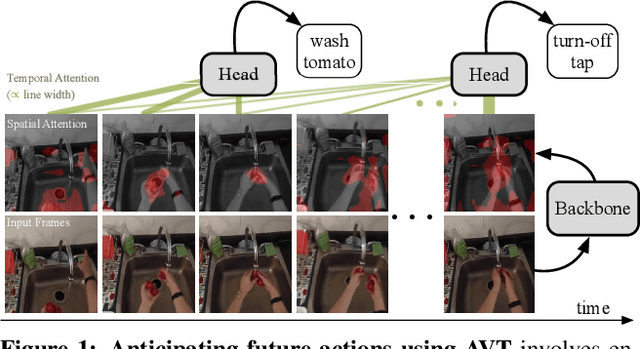
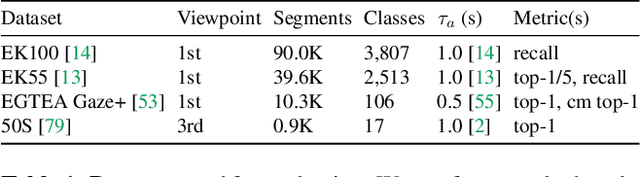

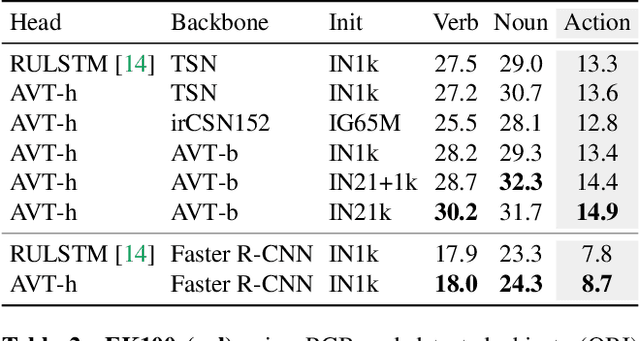
We propose Anticipative Video Transformer (AVT), an end-to-end attention-based video modeling architecture that attends to the previously observed video in order to anticipate future actions. We train the model jointly to predict the next action in a video sequence, while also learning frame feature encoders that are predictive of successive future frames' features. Compared to existing temporal aggregation strategies, AVT has the advantage of both maintaining the sequential progression of observed actions while still capturing long-range dependencies--both critical for the anticipation task. Through extensive experiments, we show that AVT obtains the best reported performance on four popular action anticipation benchmarks: EpicKitchens-55, EpicKitchens-100, EGTEA Gaze+, and 50-Salads, including outperforming all submissions to the EpicKitchens-100 CVPR'21 challenge.
Egocentric Activity Recognition and Localization on a 3D Map
May 27, 2021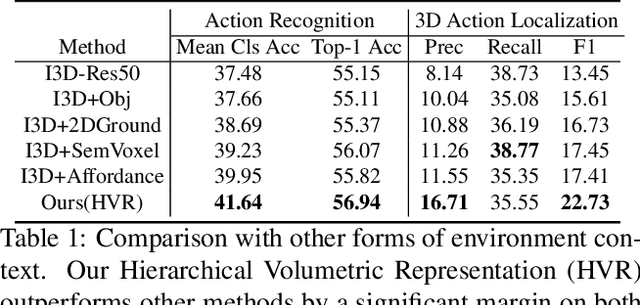
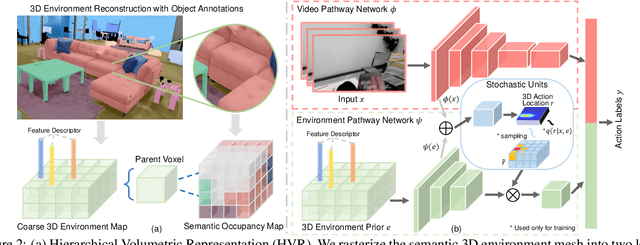
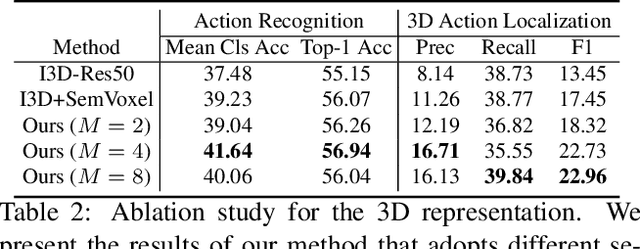
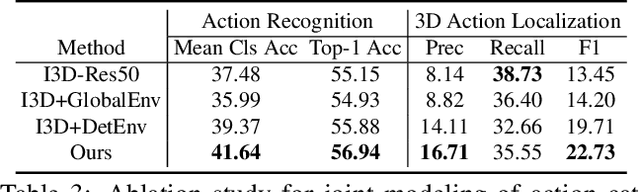
Given a video captured from a first person perspective and recorded in a familiar environment, can we recognize what the person is doing and identify where the action occurs in the 3D space? We address this challenging problem of jointly recognizing and localizing actions of a mobile user on a known 3D map from egocentric videos. To this end, we propose a novel deep probabilistic model. Our model takes the inputs of a Hierarchical Volumetric Representation (HVR) of the environment and an egocentric video, infers the 3D action location as a latent variable, and recognizes the action based on the video and contextual cues surrounding its potential locations. To evaluate our model, we conduct extensive experiments on a newly collected egocentric video dataset, in which both human naturalistic actions and photo-realistic 3D environment reconstructions are captured. Our method demonstrates strong results on both action recognition and 3D action localization across seen and unseen environments. We believe our work points to an exciting research direction in the intersection of egocentric vision, and 3D scene understanding.
Move2Hear: Active Audio-Visual Source Separation
May 15, 2021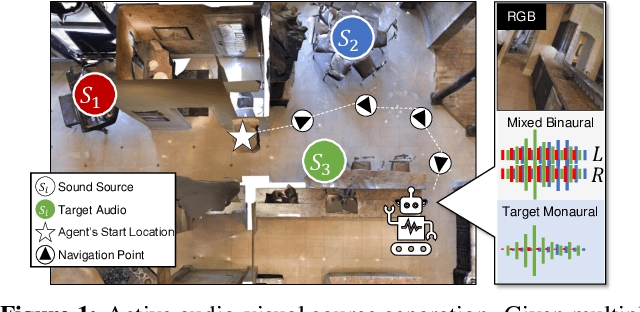
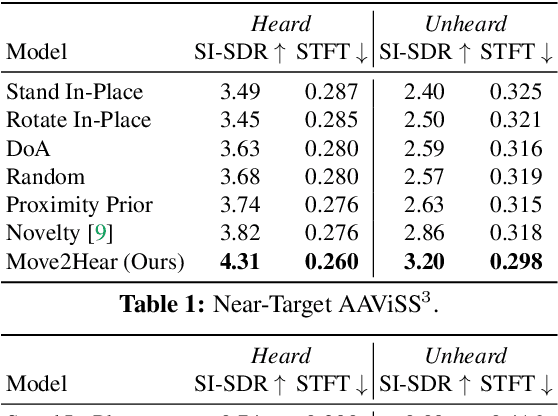
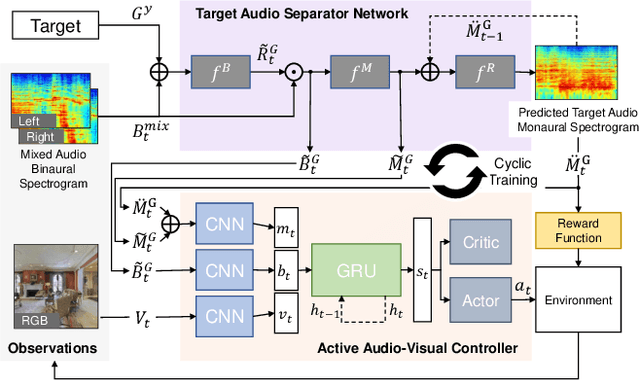
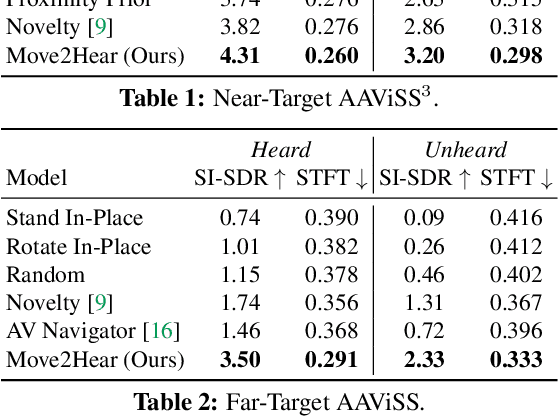
We introduce the active audio-visual source separation problem, where an agent must move intelligently in order to better isolate the sounds coming from an object of interest in its environment. The agent hears multiple audio sources simultaneously (e.g., a person speaking down the hall in a noisy household) and must use its eyes and ears to automatically separate out the sounds originating from the target object within a limited time budget. Towards this goal, we introduce a reinforcement learning approach that trains movement policies controlling the agent's camera and microphone placement over time, guided by the improvement in predicted audio separation quality. We demonstrate our approach in scenarios motivated by both augmented reality (system is already co-located with the target object) and mobile robotics (agent begins arbitrarily far from the target object). Using state-of-the-art realistic audio-visual simulations in 3D environments, we demonstrate our model's ability to find minimal movement sequences with maximal payoff for audio source separation. Project: http://vision.cs.utexas.edu/projects/move2hear.
Ego-Exo: Transferring Visual Representations from Third-person to First-person Videos
Apr 16, 2021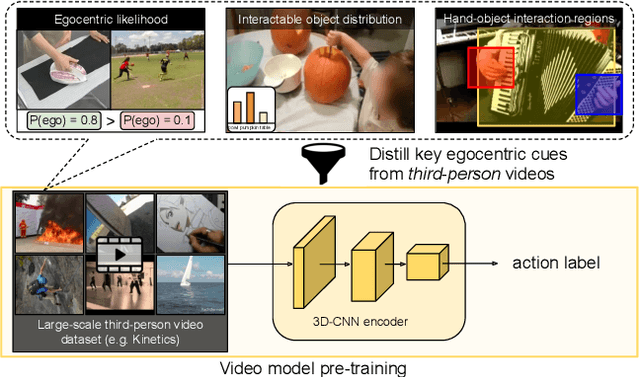
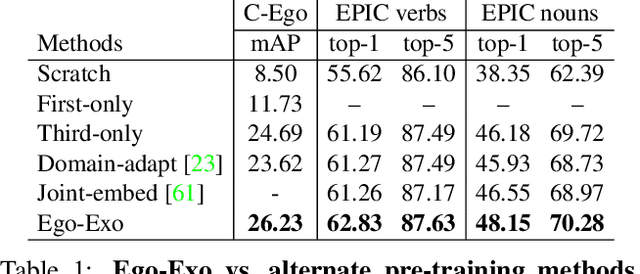
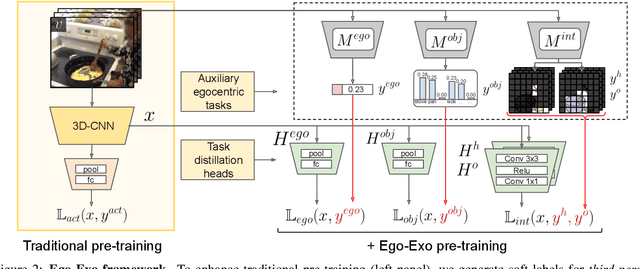
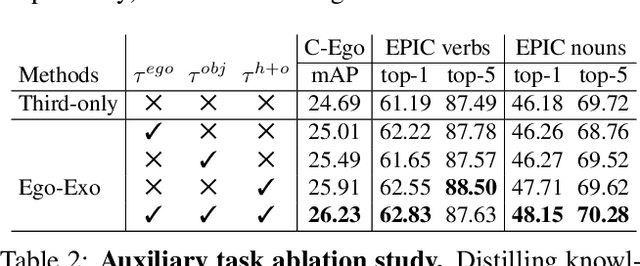
We introduce an approach for pre-training egocentric video models using large-scale third-person video datasets. Learning from purely egocentric data is limited by low dataset scale and diversity, while using purely exocentric (third-person) data introduces a large domain mismatch. Our idea is to discover latent signals in third-person video that are predictive of key egocentric-specific properties. Incorporating these signals as knowledge distillation losses during pre-training results in models that benefit from both the scale and diversity of third-person video data, as well as representations that capture salient egocentric properties. Our experiments show that our Ego-Exo framework can be seamlessly integrated into standard video models; it outperforms all baselines when fine-tuned for egocentric activity recognition, achieving state-of-the-art results on Charades-Ego and EPIC-Kitchens-100.