 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLAMR: Global Occlusion-Aware Human Mesh Recovery with Dynamic Cameras
Dec 02, 2021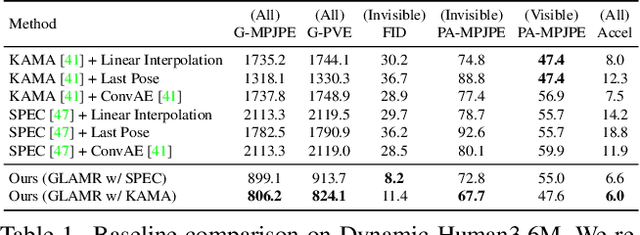
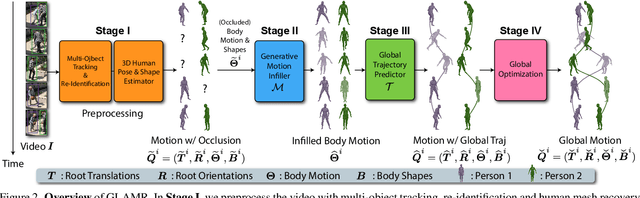
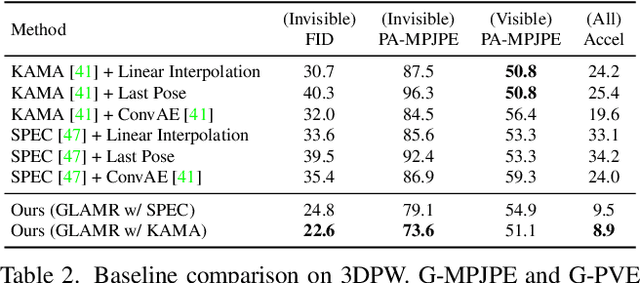
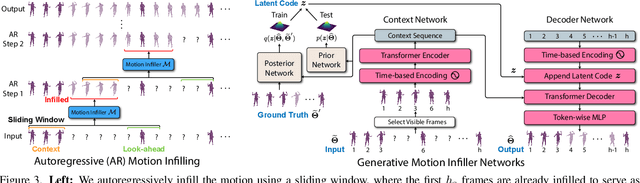
We present an approach for 3D global human mesh recovery from monocular videos recorded with dynamic cameras. Our approach is robust to severe and long-term occlusions and tracks human bodies even when they go outside the camera's field of view. To achieve this, we first propose a deep generative motion infiller, which autoregressively infills the body motions of occluded humans based on visible motions. Additionally, in contrast to prior work, our approach reconstructs human meshes in consistent global coordinates even with dynamic cameras. Since the joint reconstruction of human motions and camera poses is underconstrained, we propose a global trajectory predictor that generates global human trajectories based on local body movements. Using the predicted trajectories as anchors, we present a global optimization framework that refines the predicted trajectories and optimizes the camera poses to match the video evidence such as 2D keypoints. Experiments on challenging indoor and in-the-wild datasets with dynamic cameras demonstrate that the proposed approach outperforms prior methods significantly in terms of motion infilling and global mesh recovery.
DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
Nov 29, 2021



A typical pipeline for multi-object tracking (MOT) is to use a detector for object localization, and following re-identification (re-ID) for object association. This pipeline is partially motivated by recent progress in both object detection and re-ID, and partially motivated by biases in existing tracking datasets, where most objects tend to have distinguishing appearance and re-ID models are sufficient for establishing associations. In response to such bias, we would like to re-emphasize that methods for multi-object tracking should also work when object appearance is not sufficiently discriminative. To this end, we propose a large-scale dataset for multi-human tracking, where humans have similar appearance, diverse motion and extreme articulation. As the dataset contains mostly group dancing videos, we name it "DanceTrack". We expect DanceTrack to provide a better platform to develop more MOT algorithms that rely less on visual discrimination and depend more on motion analysis. We benchmark several state-of-the-art trackers on our dataset and observe a significant performance drop on DanceTrack when compared against existing benchmarks. The dataset, project code and competition server are released at: \url{https://github.com/DanceTrack}.
Cross-Domain Object Detection via Adaptive Self-Training
Nov 25, 2021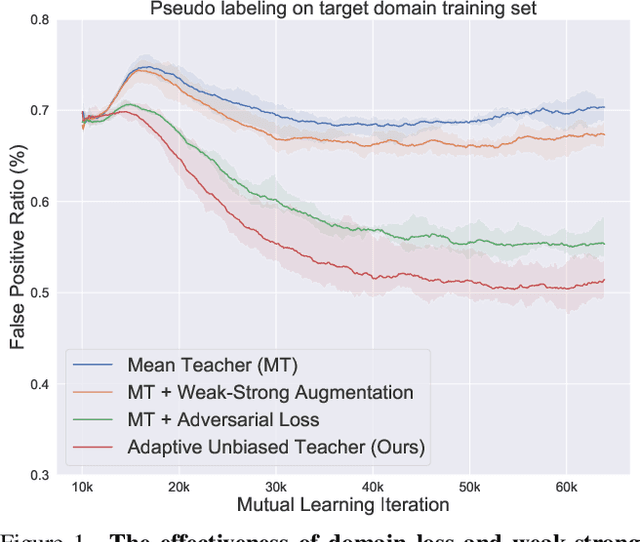
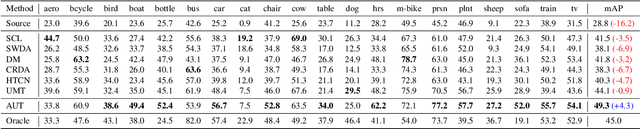
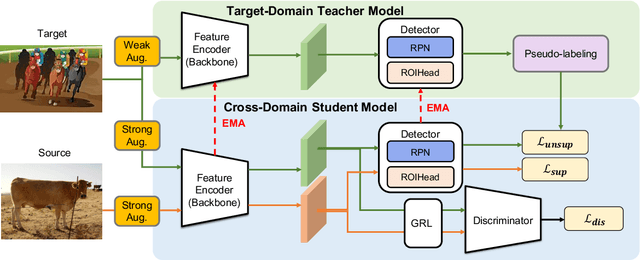
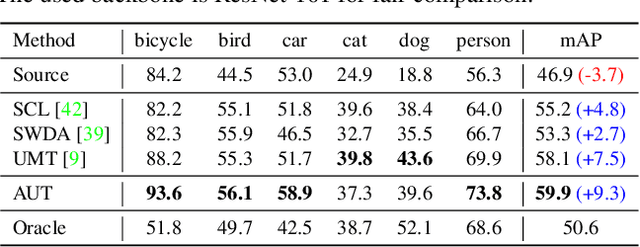
We tackle the problem of domain adaptation in object detection, where there is a significant domain shift between a source (a domain with supervision) and a target domain (a domain of interest without supervision). As a widely adopted domain adaptation method, the self-training teacher-student framework (a student model learns from pseudo labels generated from a teacher model) has yielded remarkable accuracy gain on the target domain. However, it still suffers from the large amount of low-quality pseudo labels (e.g., false positives) generated from the teacher due to its bias toward the source domain. To address this issue, we propose a self-training framework called Adaptive Unbiased Teacher (AUT) leveraging adversarial learning and weak-strong data augmentation during mutual learning to address domain shift. Specifically, we employ feature-level adversarial training in the student model, ensuring features extracted from the source and target domains share similar statistics. This enables the student model to capture domain-invariant features. Furthermore, we apply weak-strong augmentation and mutual learning between the teacher model on the target domain and the student model on both domains. This enables the teacher model to gradually benefit from the student model without suffering domain shift. We show that AUT demonstrates superiority over all existing approaches and even Oracle (fully supervised) models by a large margin. For example, we achieve 50.9% (49.3%) mAP on Foggy Cityscape (Clipart1K), which is 9.2% (5.2%) and 8.2% (11.0%) higher than previous state-of-the-art and Oracle, respectively
AEI: Actors-Environment Interaction with Adaptive Attention for Temporal Action Proposals Generation
Oct 25, 2021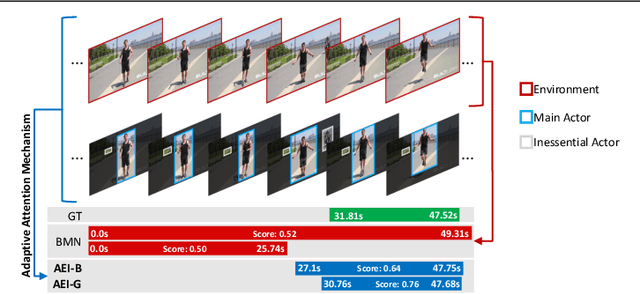
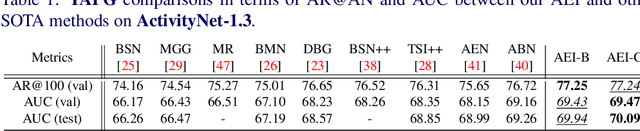
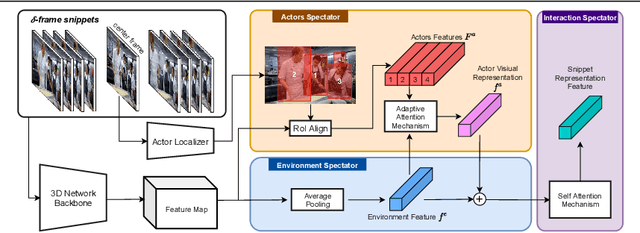
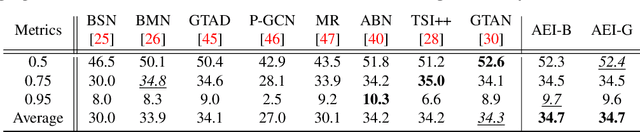
Humans typically perceive the establishment of an action in a video through the interaction between an actor and the surrounding environment. An action only starts when the main actor in the video begins to interact with the environment, while it ends when the main actor stops the interaction. Despite the great progress in temporal action proposal generation, most existing works ignore the aforementioned fact and leave their model learning to propose actions as a black-box. In this paper, we make an attempt to simulate that ability of a human by proposing Actor Environment Interaction (AEI) network to improve the video representation for temporal action proposals generation. AEI contains two modules, i.e., perception-based visual representation (PVR) and boundary-matching module (BMM). PVR represents each video snippet by taking human-human relations and humans-environment relations into consideration using the proposed adaptive attention mechanism. Then, the video representation is taken by BMM to generate action proposals. AEI is comprehensively evaluated in ActivityNet-1.3 and THUMOS-14 datasets, on temporal action proposal and detection tasks, with two boundary-matching architectures (i.e., CNN-based and GCN-based) and two classifiers (i.e., Unet and P-GCN). Our AEI robustly outperforms the state-of-the-art methods with remarkable performance and generalization for both temporal action proposal generation and temporal action detection.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Transform2Act: Learning a Transform-and-Control Policy for Efficient Agent Design
Oct 07, 2021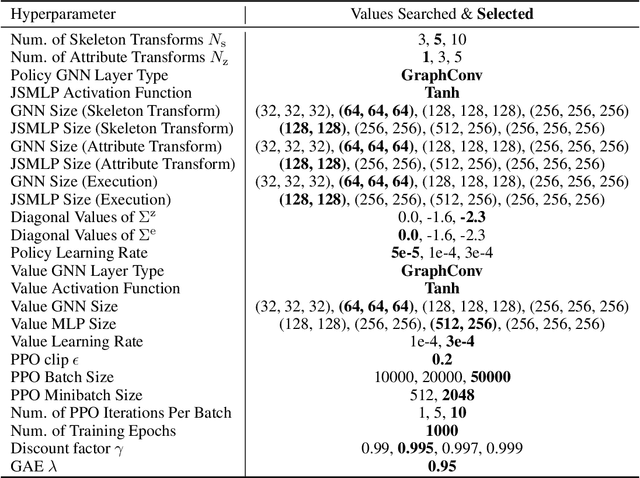
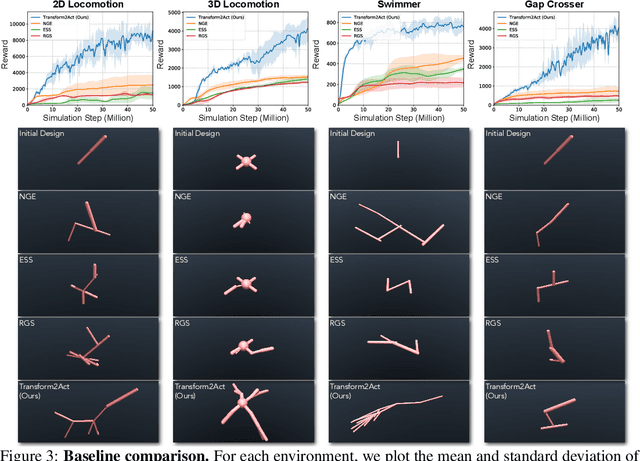
An agent's functionality is largely determined by its design, i.e., skeletal structure and joint attributes (e.g., length, size, strength). However, finding the optimal agent design for a given function is extremely challenging since the problem is inherently combinatorial and the design space is prohibitively large. Additionally, it can be costly to evaluate each candidate design which requires solving for its optimal controller. To tackle these problems, our key idea is to incorporate the design procedure of an agent into its decision-making process. Specifically, we learn a conditional policy that, in an episode, first applies a sequence of transform actions to modify an agent's skeletal structure and joint attributes, and then applies control actions under the new design. To handle a variable number of joints across designs, we use a graph-based policy where each graph node represents a joint and uses message passing with its neighbors to output joint-specific actions. Using policy gradient methods, our approach enables first-order optimization of agent design and control as well as experience sharing across different designs, which improves sample efficiency tremendously. Experiments show that our approach, Transform2Act, outperforms prior methods significantly in terms of convergence speed and final performance. Notably, Transform2Act can automatically discover plausible designs similar to giraffes, squids, and spiders. Our project website is at https://sites.google.com/view/transform2act.
Multi-Echo LiDAR for 3D Object Detection
Jul 23, 2021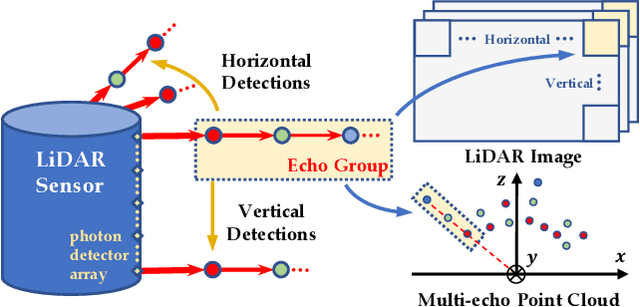
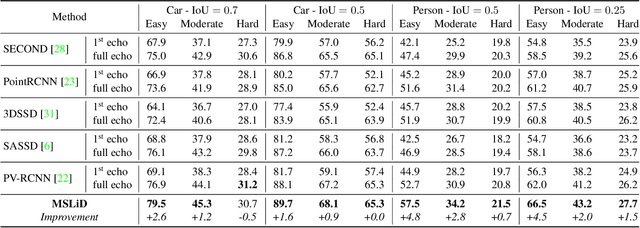
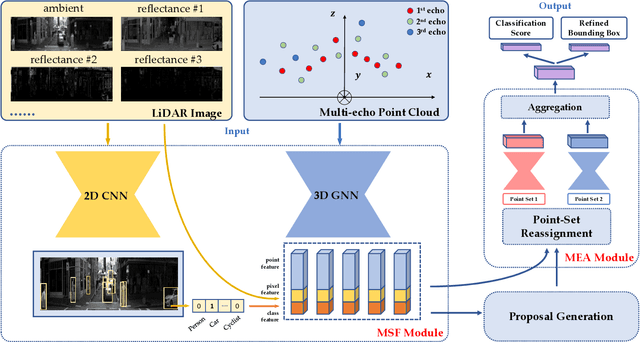
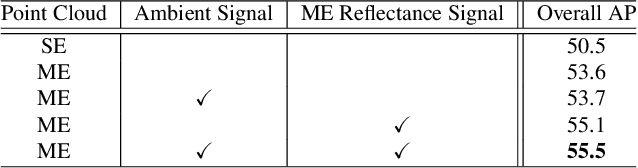
LiDAR sensors can be used to obtain a wide range of measurement signals other than a simple 3D point cloud, and those signals can be leveraged to improve perception tasks like 3D object detection. A single laser pulse can be partially reflected by multiple objects along its path, resulting in multiple measurements called echoes. Multi-echo measurement can provide information about object contours and semi-transparent surfaces which can be used to better identify and locate objects. LiDAR can also measure surface reflectance (intensity of laser pulse return), as well as ambient light of the scene (sunlight reflected by objects). These signals are already available in commercial LiDAR devices but have not been used in most LiDAR-based detection models. We present a 3D object detection model which leverages the full spectrum of measurement signals provided by LiDAR. First, we propose a multi-signal fusion (MSF) module to combine (1) the reflectance and ambient features extracted with a 2D CNN, and (2) point cloud features extracted using a 3D graph neural network (GNN). Second, we propose a multi-echo aggregation (MEA) module to combine the information encoded in different set of echo points. Compared with traditional single echo point cloud methods, our proposed Multi-Signal LiDAR Detector (MSLiD) extracts richer context information from a wider range of sensing measurements and achieves more accurate 3D object detection. Experiments show that by incorporating the multi-modality of LiDAR, our method outperforms the state-of-the-art by up to 9.1%.
Multi-Modality Task Cascade for 3D Object Detection
Jul 08, 2021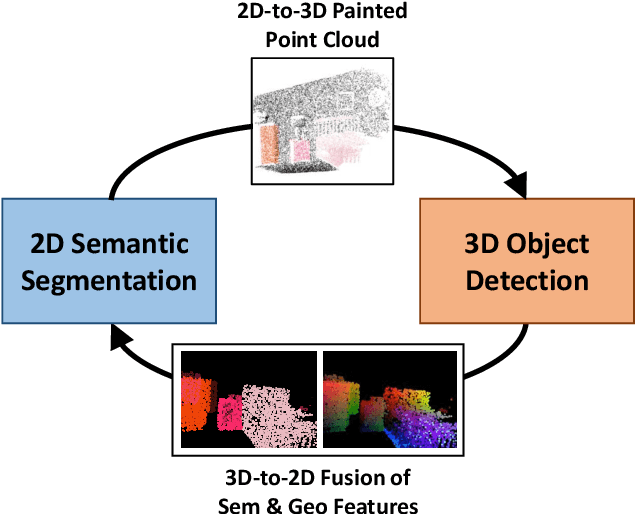
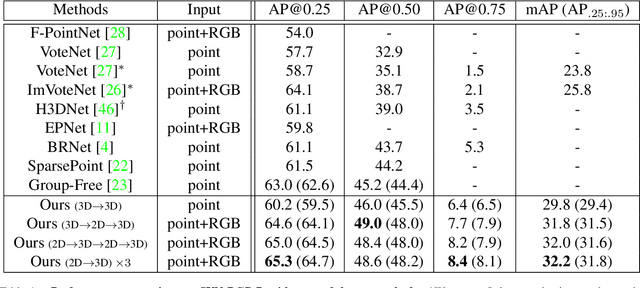
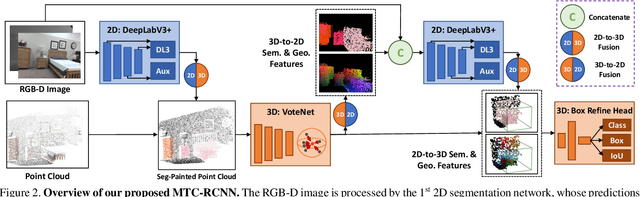
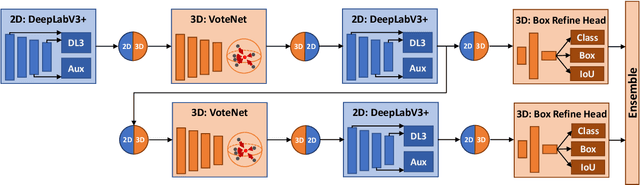
Point clouds and RGB images are naturally complementary modalities for 3D visual understanding - the former provides sparse but accurate locations of points on objects, while the latter contains dense color and texture information. Despite this potential for close sensor fusion, many methods train two models in isolation and use simple feature concatenation to represent 3D sensor data. This separated training scheme results in potentially sub-optimal performance and prevents 3D tasks from being used to benefit 2D tasks that are often useful on their own. To provide a more integrated approach, we propose a novel Multi-Modality Task Cascade network (MTC-RCNN) that leverages 3D box proposals to improve 2D segmentation predictions, which are then used to further refine the 3D boxes. We show that including a 2D network between two stages of 3D modules significantly improves both 2D and 3D task performance. Moreover, to prevent the 3D module from over-relying on the overfitted 2D predictions, we propose a dual-head 2D segmentation training and inference scheme, allowing the 2nd 3D module to learn to interpret imperfect 2D segmentation predictions. Evaluating our model on the challenging SUN RGB-D dataset, we improve upon state-of-the-art results of both single modality and fusion networks by a large margin ($\textbf{+3.8}$ mAP@0.5). Code will be released $\href{https://github.com/Divadi/MTC_RCNN}{\text{here.}}$
Dynamics-Regulated Kinematic Policy for Egocentric Pose Estimation
Jun 10, 2021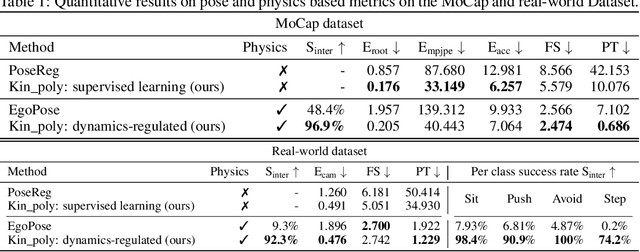
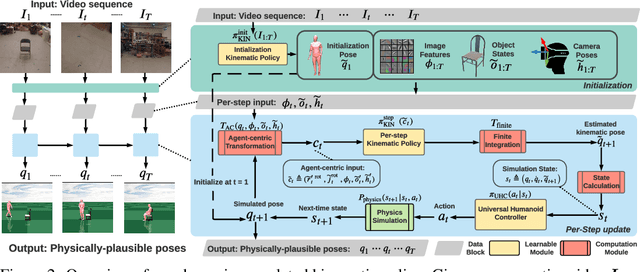
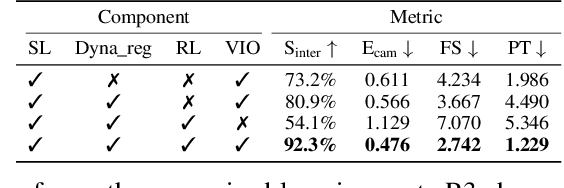
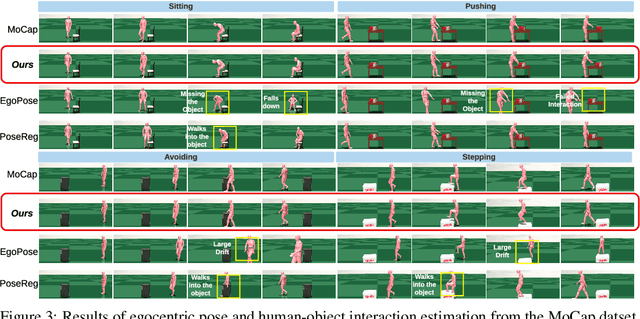
We propose a method for object-aware 3D egocentric pose estimation that tightly integrates kinematics modeling, dynamics modeling, and scene object information. Unlike prior kinematics or dynamics-based approaches where the two components are used disjointly, we synergize the two approaches via dynamics-regulated training. At each timestep, a kinematic model is used to provide a target pose using video evidence and simulation state. Then, a prelearned dynamics model attempts to mimic the kinematic pose in a physics simulator. By comparing the pose instructed by the kinematic model against the pose generated by the dynamics model, we can use their misalignment to further improve the kinematic model. By factoring in the 6DoF pose of objects (e.g., chairs, boxes) in the scene, we demonstrate for the first time, the ability to estimate physically-plausible 3D human-object interactions using a single wearable camera. We evaluate our egocentric pose estimation method in both controlled laboratory settings and real-world scenarios.
Wide-Baseline Multi-Camera Calibration using Person Re-Identification
Apr 17, 2021
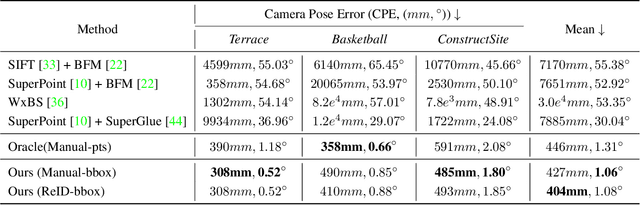
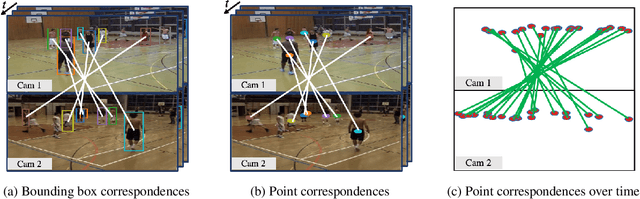
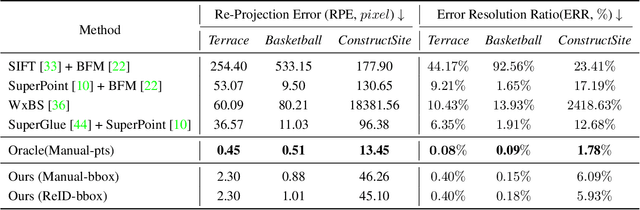
We address the problem of estimating the 3D pose of a network of cameras for large-environment wide-baseline scenarios, e.g., cameras for construction sites, sports stadiums, and public spaces. This task is challenging since detecting and matching the same 3D keypoint observed from two very different camera views is difficult, making standard structure-from-motion (SfM) pipelines inapplicable. In such circumstances, treating people in the scene as "keypoints" and associating them across different camera views can be an alternative method for obtaining correspondences. Based on this intuition, we propose a method that uses ideas from person re-identification (re-ID) for wide-baseline camera calibration. Our method first employs a re-ID method to associate human bounding boxes across cameras, then converts bounding box correspondences to point correspondences, and finally solves for camera pose using multi-view geometry and bundle adjustment. Since our method does not require specialized calibration targets except for visible people, it applies to situations where frequent calibration updates are required. We perform extensive experiments on datasets captured from scenes of different sizes, camera settings (indoor and outdoor), and human activities (walking, playing basketball, construction). Experiment results show that our method achieves similar performance to standard SfM methods relying on manually labeled point correspondences.