 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Action-Free Pre-Training from Videos
Mar 25, 2022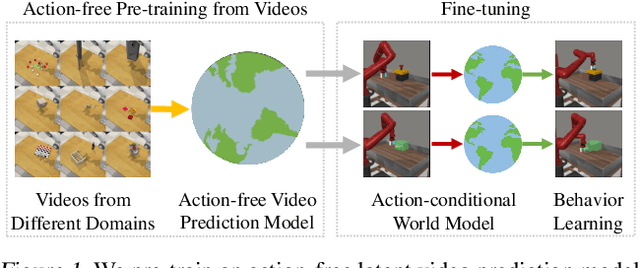
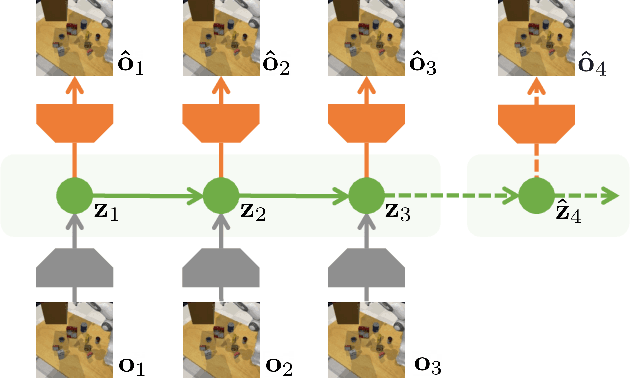
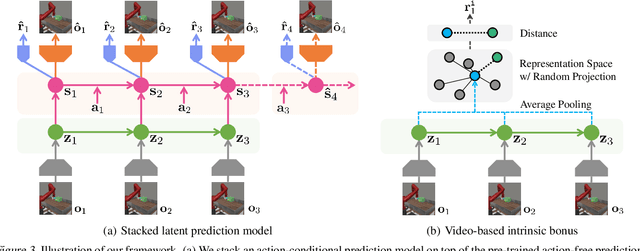
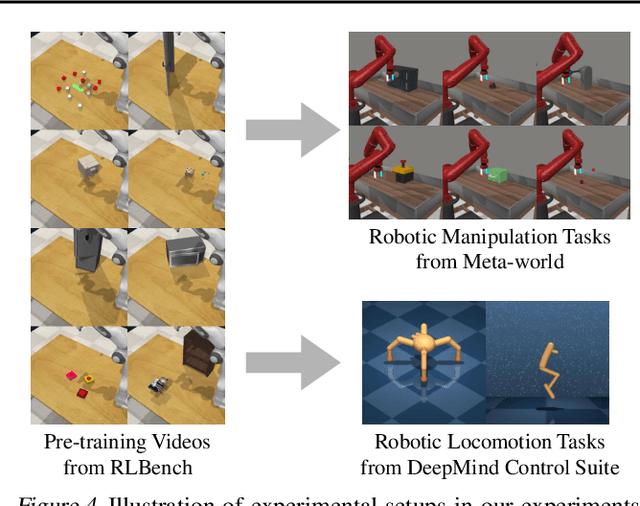
Recent unsupervised pre-training methods have shown to be effective on language and vision domains by learning useful representations for multiple downstream tasks. In this paper, we investigate if such unsupervised pre-training methods can also be effective for vision-based reinforcement learning (RL). To this end, we introduce a framework that learns representations useful for understanding the dynamics via generative pre-training on videos. Our framework consists of two phases: we pre-train an action-free latent video prediction model, and then utilize the pre-trained representations for efficiently learning action-conditional world models on unseen environments. To incorporate additional action inputs during fine-tuning, we introduce a new architecture that stacks an action-conditional latent prediction model on top of the pre-trained action-free prediction model. Moreover, for better exploration, we propose a video-based intrinsic bonus that leverages pre-trained representations. We demonstrate that our framework significantly improves both final performances and sample-efficiency of vision-based RL in a variety of manipulation and locomotion tasks. Code is available at https://github.com/younggyoseo/apv.
SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning
Mar 18, 2022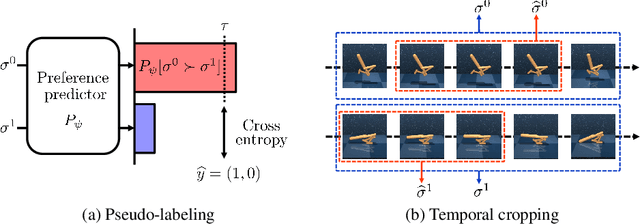

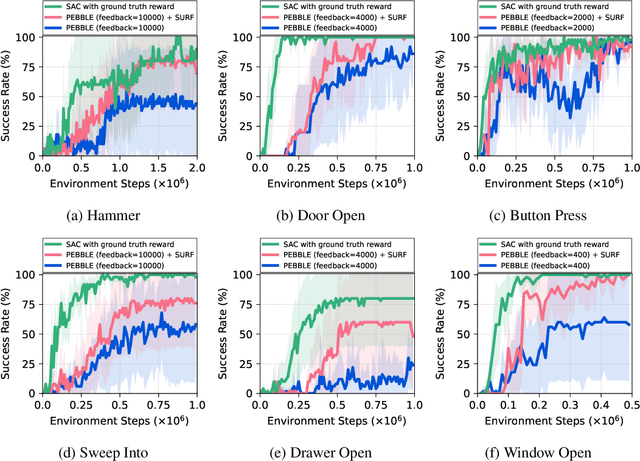

Preference-based reinforcement learning (RL) has shown potential for teaching agents to perform the target tasks without a costly, pre-defined reward function by learning the reward with a supervisor's preference between the two agent behaviors. However, preference-based learning often requires a large amount of human feedback, making it difficult to apply this approach to various applications. This data-efficiency problem, on the other hand, has been typically addressed by using unlabeled samples or data augmentation techniques in the context of supervised learning. Motivated by the recent success of these approaches, we present SURF, a semi-supervised reward learning framework that utilizes a large amount of unlabeled samples with data augmentation. In order to leverage unlabeled samples for reward learning, we infer pseudo-labels of the unlabeled samples based on the confidence of the preference predictor. To further improve the label-efficiency of reward learning, we introduce a new data augmentation that temporally crops consecutive subsequences from the original behaviors. Our experiments demonstrate that our approach significantly improves the feedback-efficiency of the state-of-the-art preference-based method on a variety of locomotion and robotic manipulation tasks.
Improving Transferability of Representations via Augmentation-Aware Self-Supervision
Nov 18, 2021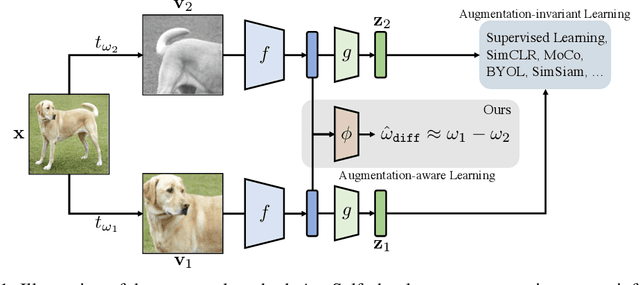
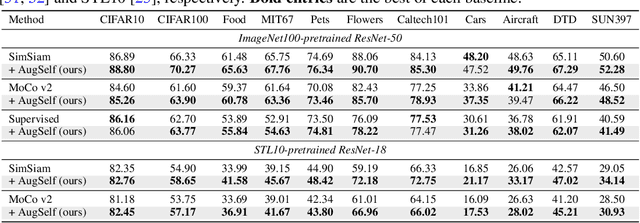
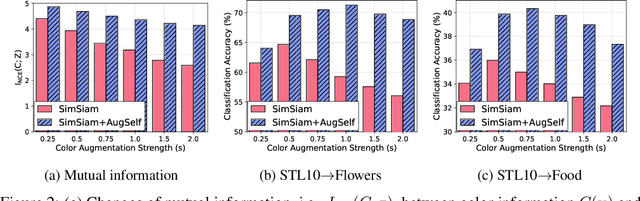
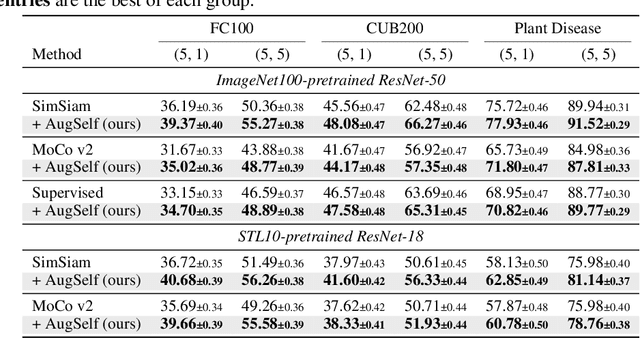
Recent unsupervised representation learning methods have shown to be effective in a range of vision tasks by learning representations invariant to data augmentations such as random cropping and color jittering. However, such invariance could be harmful to downstream tasks if they rely on the characteristics of the data augmentations, e.g., location- or color-sensitive. This is not an issue just for unsupervised learning; we found that this occurs even in supervised learning because it also learns to predict the same label for all augmented samples of an instance. To avoid such failures and obtain more generalizable representations, we suggest to optimize an auxiliary self-supervised loss, coined AugSelf, that learns the difference of augmentation parameters (e.g., cropping positions, color adjustment intensities) between two randomly augmented samples. Our intuition is that AugSelf encourages to preserve augmentation-aware information in learned representations, which could be beneficial for their transferability. Furthermore, AugSelf can easily be incorporated into recent state-of-the-art representation learning methods with a negligible additional training cost. Extensive experiments demonstrate that our simple idea consistently improves the transferability of representations learned by supervised and unsupervised methods in various transfer learning scenarios. The code is available at https://github.com/hankook/AugSelf.
B-Pref: Benchmarking Preference-Based Reinforcement Learning
Nov 04, 2021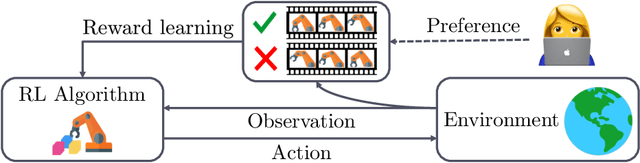
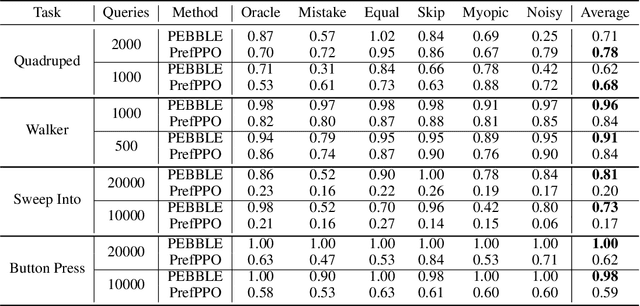
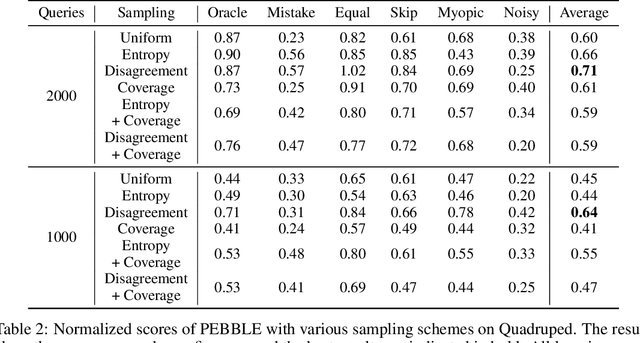
Reinforcement learning (RL) requires access to a reward function that incentivizes the right behavior, but these are notoriously hard to specify for complex tasks. Preference-based RL provides an alternative: learning policies using a teacher's preferences without pre-defined rewards, thus overcoming concerns associated with reward engineering. However, it is difficult to quantify the progress in preference-based RL due to the lack of a commonly adopted benchmark. In this paper, we introduce B-Pref: a benchmark specially designed for preference-based RL. A key challenge with such a benchmark is providing the ability to evaluate candidate algorithms quickly, which makes relying on real human input for evaluation prohibitive. At the same time, simulating human input as giving perfect preferences for the ground truth reward function is unrealistic. B-Pref alleviates this by simulating teachers with a wide array of irrationalities, and proposes metrics not solely for performance but also for robustness to these potential irrationalities. We showcase the utility of B-Pref by using it to analyze algorithmic design choices, such as selecting informative queries, for state-of-the-art preference-based RL algorithms. We hope that B-Pref can serve as a common starting point to study preference-based RL more systematically. Source code is available at https://github.com/rll-research/B-Pref.
URLB: Unsupervised Reinforcement Learning Benchmark
Oct 28, 2021
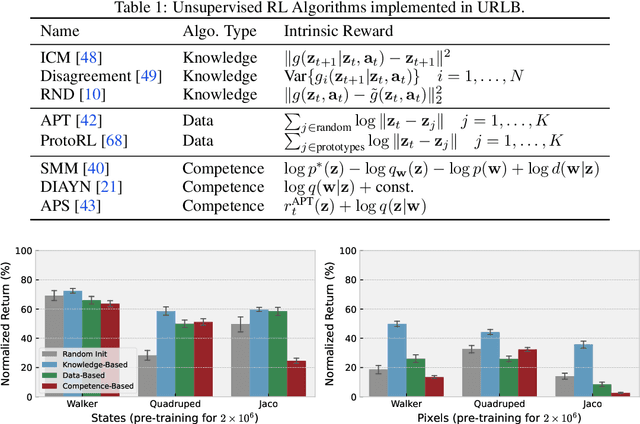
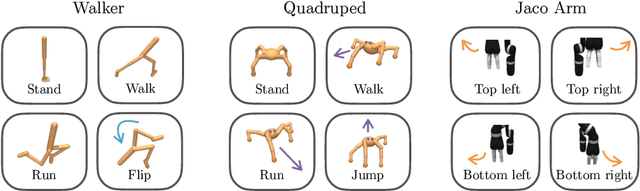

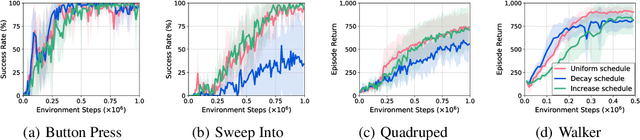
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm to solve a range of complex yet specific control tasks. Yet training generalist agents that can quickly adapt to new tasks remains an outstanding challenge. Recent advances in unsupervised RL have shown that pre-training RL agents with self-supervised intrinsic rewards can result in efficient adaptation. However, these algorithms have been hard to compare and develop due to the lack of a unified benchmark. To this end, we introduce the Unsupervised Reinforcement Learning Benchmark (URLB). URLB consists of two phases: reward-free pre-training and downstream task adaptation with extrinsic rewards. Building on the DeepMind Control Suite, we provide twelve continuous control tasks from three domains for evaluation and open-source code for eight leading unsupervised RL methods. We find that the implemented baselines make progress but are not able to solve URLB and propose directions for future research.
Towards More Generalizable One-shot Visual Imitation Learning
Oct 26, 2021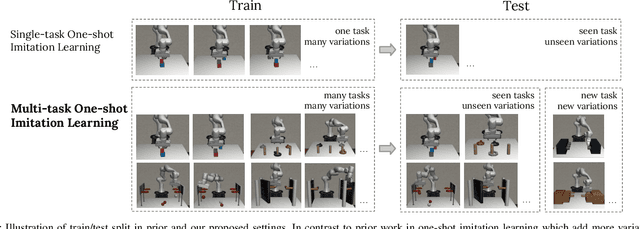

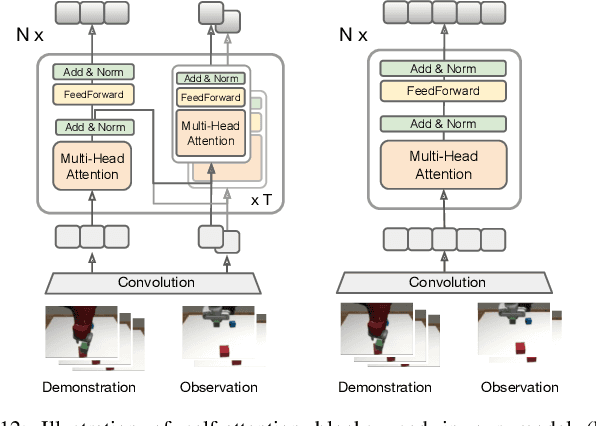
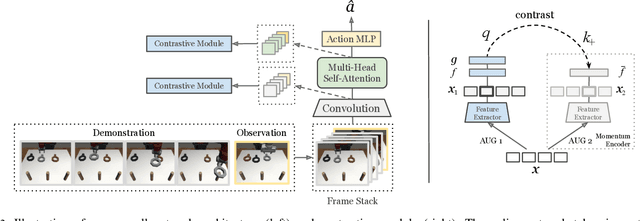
A general-purpose robot should be able to master a wide range of tasks and quickly learn a novel one by leveraging past experiences. One-shot imitation learning (OSIL) approaches this goal by training an agent with (pairs of) expert demonstrations, such that at test time, it can directly execute a new task from just one demonstration. However, so far this framework has been limited to training on many variations of one task, and testing on other unseen but similar variations of the same task. In this work, we push for a higher level of generalization ability by investigating a more ambitious multi-task setup. We introduce a diverse suite of vision-based robot manipulation tasks, consisting of 7 tasks, a total of 61 variations, and a continuum of instances within each variation. For consistency and comparison purposes, we first train and evaluate single-task agents (as done in prior few-shot imitation work). We then study the multi-task setting, where multi-task training is followed by (i) one-shot imitation on variations within the training tasks, (ii) one-shot imitation on new tasks, and (iii) fine-tuning on new tasks. Prior state-of-the-art, while performing well within some single tasks, struggles in these harder multi-task settings. To address these limitations, we propose MOSAIC (Multi-task One-Shot Imitation with self-Attention and Contrastive learning), which integrates a self-attention model architecture and a temporal contrastive module to enable better task disambiguation and more robust representation learning. Our experiments show that MOSAIC outperforms prior state of the art in learning efficiency, final performance, and learns a multi-task policy with promising generalization ability via fine-tuning on novel tasks.
Skill Preferences: Learning to Extract and Execute Robotic Skills from Human Feedback
Aug 11, 2021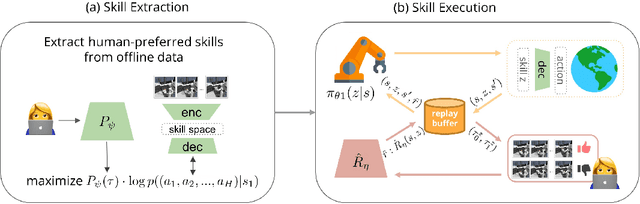
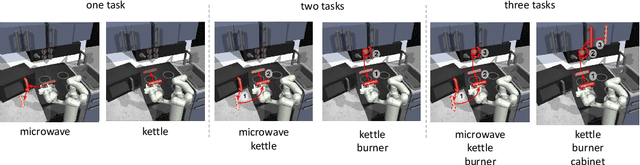
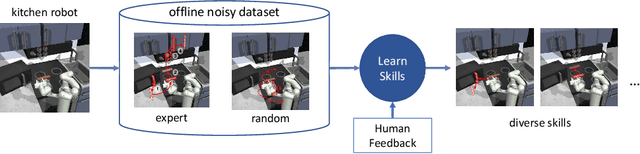
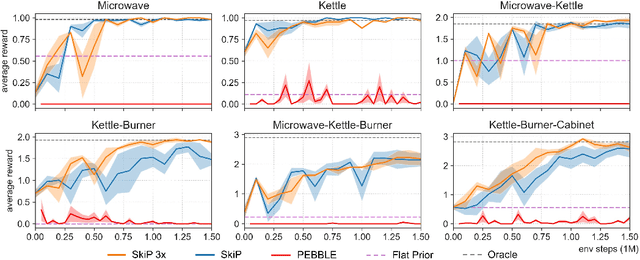
A promising approach to solving challenging long-horizon tasks has been to extract behavior priors (skills) by fitting generative models to large offline datasets of demonstrations. However, such generative models inherit the biases of the underlying data and result in poor and unusable skills when trained on imperfect demonstration data. To better align skill extraction with human intent we present Skill Preferences (SkiP), an algorithm that learns a model over human preferences and uses it to extract human-aligned skills from offline data. After extracting human-preferred skills, SkiP also utilizes human feedback to solve down-stream tasks with RL. We show that SkiP enables a simulated kitchen robot to solve complex multi-step manipulation tasks and substantially outperforms prior leading RL algorithms with human preferences as well as leading skill extraction algorithms without human preferences.
Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble
Jul 01, 2021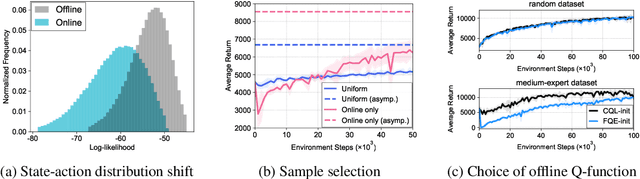
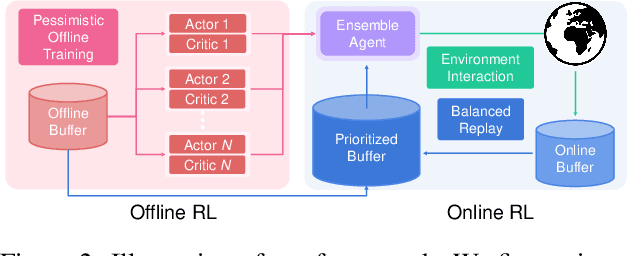
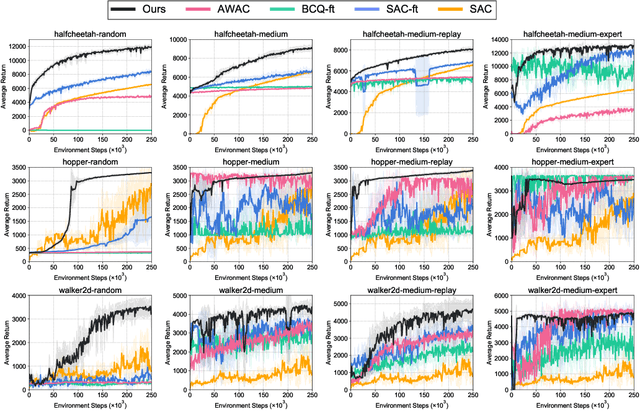
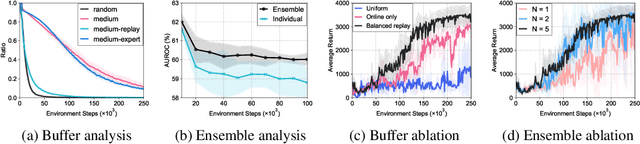
Recent advance in deep offline reinforcement learning (RL) has made it possible to train strong robotic agents from offline datasets. However, depending on the quality of the trained agents and the application being considered, it is often desirable to fine-tune such agents via further online interactions. In this paper, we observe that state-action distribution shift may lead to severe bootstrap error during fine-tuning, which destroys the good initial policy obtained via offline RL. To address this issue, we first propose a balanced replay scheme that prioritizes samples encountered online while also encouraging the use of near-on-policy samples from the offline dataset. Furthermore, we leverage multiple Q-functions trained pessimistically offline, thereby preventing overoptimism concerning unfamiliar actions at novel states during the initial training phase. We show that the proposed method improves sample-efficiency and final performance of the fine-tuned robotic agents on various locomotion and manipulation tasks. Our code is available at: https://github.com/shlee94/Off2OnRL.
Decision Transformer: Reinforcement Learning via Sequence Modeling
Jun 24, 2021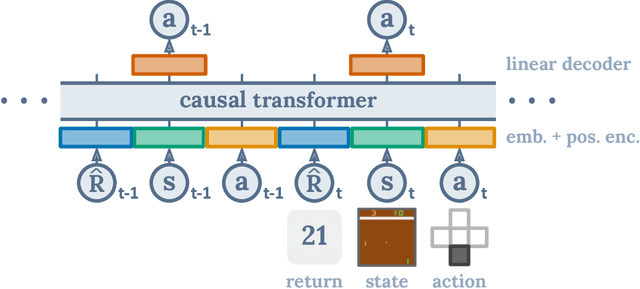
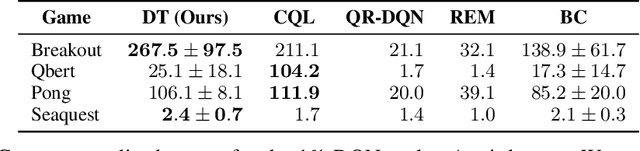

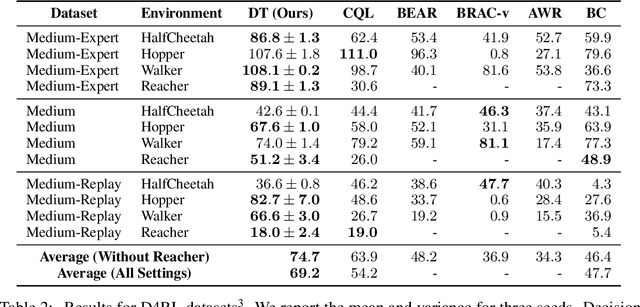
We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks.
Scenic4RL: Programmatic Modeling and Generation of Reinforcement Learning Environments
Jun 18, 2021

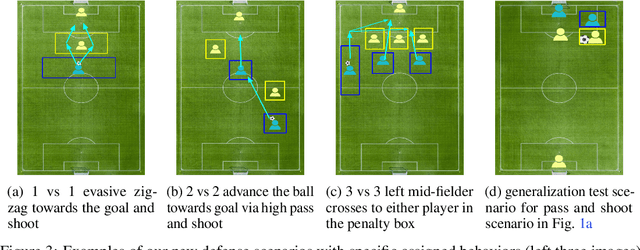
The capability of reinforcement learning (RL) agent directly depends on the diversity of learning scenarios the environment generates and how closely it captures real-world situations. However, existing environments/simulators lack the support to systematically model distributions over initial states and transition dynamics. Furthermore, in complex domains such as soccer, the space of possible scenarios is infinite, which makes it impossible for one research group to provide a comprehensive set of scenarios to train, test, and benchmark RL algorithms. To address this issue, for the first time, we adopt an existing formal scenario specification language, SCENIC, to intuitively model and generate interactive scenarios. We interfaced SCENIC to Google Research Soccer environment to create a platform called SCENIC4RL. Using this platform, we provide a dataset consisting of 36 scenario programs encoded in SCENIC and demonstration data generated from a subset of them. We share our experimental results to show the effectiveness of our dataset and the platform to train, test, and benchmark RL algorithms. More importantly, we open-source our platform to enable RL community to collectively contribute to constructing a comprehensive set of scenarios.