 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrimlock: Guarding High-Agency Systems with eBPF and Attested Channels
May 26, 2026Agentic systems increasingly run user-authored orchestration code that invokes tools, spawns subtasks, and delegates work across machines and clouds. Although this high agency is productive, it creates a security problem: identity, authorization, provenance, and delegation are often pushed into application code, where they become difficult to enforce consistently and difficult to audit. We present \emph{Grimlock}, an \emph{Agent Guard} that restores separation of concerns by moving trust enforcement into the sandbox substrate while leaving agent code unchanged. Grimlock uses \emph{eBPF-enforced traffic interception} to ensure that sandbox communication passes through a guard, and combines it with \emph{post-handshake attestation} bound to standard TLS~1.3 channel bindings. After a channel is established, the guard authorizes communication and mints short-lived, channel-bound \emph{scope tokens} that capture least-privilege delegation. At the receiving side, the destination guard re-validates identity, scope, and channel binding, terminates TLS, and releases plaintext to the destination sandbox only after policy checks succeed. kTLS provides an efficient dataplane for protected communication. As a result, Grimlock offers a path toward transparent, auditable, and scope-bound agent-to-agent communication across heterogeneous multi-cloud environments, using commodity Linux primitives and without requiring changes to user-layer orchestration code.
Scenic4RL: Programmatic Modeling and Generation of Reinforcement Learning Environments
Jun 18, 2021
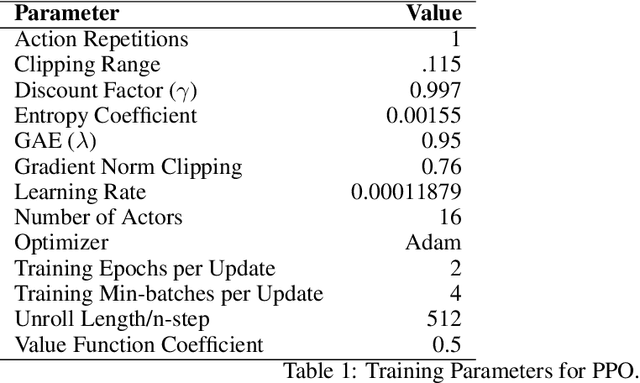

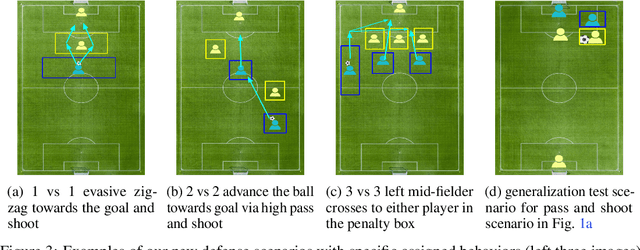
The capability of reinforcement learning (RL) agent directly depends on the diversity of learning scenarios the environment generates and how closely it captures real-world situations. However, existing environments/simulators lack the support to systematically model distributions over initial states and transition dynamics. Furthermore, in complex domains such as soccer, the space of possible scenarios is infinite, which makes it impossible for one research group to provide a comprehensive set of scenarios to train, test, and benchmark RL algorithms. To address this issue, for the first time, we adopt an existing formal scenario specification language, SCENIC, to intuitively model and generate interactive scenarios. We interfaced SCENIC to Google Research Soccer environment to create a platform called SCENIC4RL. Using this platform, we provide a dataset consisting of 36 scenario programs encoded in SCENIC and demonstration data generated from a subset of them. We share our experimental results to show the effectiveness of our dataset and the platform to train, test, and benchmark RL algorithms. More importantly, we open-source our platform to enable RL community to collectively contribute to constructing a comprehensive set of scenarios.
SegAttnGAN: Text to Image Generation with Segmentation Attention
May 25, 2020
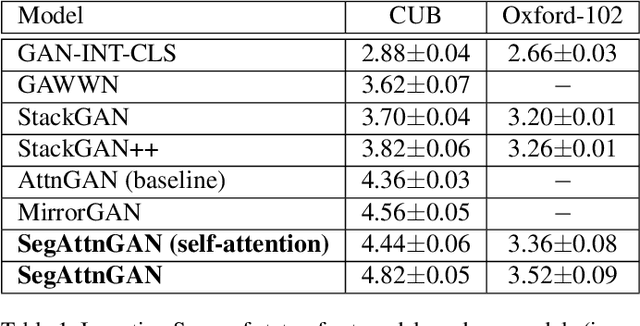
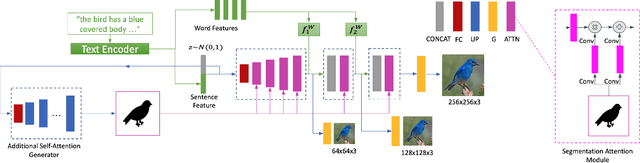

In this paper, we propose a novel generative network (SegAttnGAN) that utilizes additional segmentation information for the text-to-image synthesis task. As the segmentation data introduced to the model provides useful guidance on the generator training, the proposed model can generate images with better realism quality and higher quantitative measures compared with the previous state-of-art methods. We achieved Inception Score of 4.84 on the CUB dataset and 3.52 on the Oxford-102 dataset. Besides, we tested the self-attention SegAttnGAN which uses generated segmentation data instead of masks from datasets for attention and achieved similar high-quality results, suggesting that our model can be adapted for the text-to-image synthesis task.