 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelodyGLM: Multi-task Pre-training for Symbolic Melody Generation
Sep 20, 2023



Pre-trained language models have achieved impressive results in various music understanding and generation tasks. However, existing pre-training methods for symbolic melody generation struggle to capture multi-scale, multi-dimensional structural information in note sequences, due to the domain knowledge discrepancy between text and music. Moreover, the lack of available large-scale symbolic melody datasets limits the pre-training improvement. In this paper, we propose MelodyGLM, a multi-task pre-training framework for generating melodies with long-term structure. We design the melodic n-gram and long span sampling strategies to create local and global blank infilling tasks for modeling the local and global structures in melodies. Specifically, we incorporate pitch n-grams, rhythm n-grams, and their combined n-grams into the melodic n-gram blank infilling tasks for modeling the multi-dimensional structures in melodies. To this end, we have constructed a large-scale symbolic melody dataset, MelodyNet, containing more than 0.4 million melody pieces. MelodyNet is utilized for large-scale pre-training and domain-specific n-gram lexicon construction. Both subjective and objective evaluations demonstrate that MelodyGLM surpasses the standard and previous pre-training methods. In particular, subjective evaluations show that, on the melody continuation task, MelodyGLM gains average improvements of 0.82, 0.87, 0.78, and 0.94 in consistency, rhythmicity, structure, and overall quality, respectively. Notably, MelodyGLM nearly matches the quality of human-composed melodies on the melody inpainting task.
SongDriver2: Real-time Emotion-based Music Arrangement with Soft Transition
May 14, 2023Real-time emotion-based music arrangement, which aims to transform a given music piece into another one that evokes specific emotional resonance with the user in real-time, holds significant application value in various scenarios, e.g., music therapy, video game soundtracks, and movie scores. However, balancing emotion real-time fit with soft emotion transition is a challenge due to the fine-grained and mutable nature of the target emotion. Existing studies mainly focus on achieving emotion real-time fit, while the issue of soft transition remains understudied, affecting the overall emotional coherence of the music. In this paper, we propose SongDriver2 to address this balance. Specifically, we first recognize the last timestep's music emotion and then fuse it with the current timestep's target input emotion. The fused emotion then serves as the guidance for SongDriver2 to generate the upcoming music based on the input melody data. To adjust music similarity and emotion real-time fit flexibly, we downsample the original melody and feed it into the generation model. Furthermore, we design four music theory features to leverage domain knowledge to enhance emotion information and employ semi-supervised learning to mitigate the subjective bias introduced by manual dataset annotation. According to the evaluation results, SongDriver2 surpasses the state-of-the-art methods in both objective and subjective metrics. These results demonstrate that SongDriver2 achieves real-time fit and soft transitions simultaneously, enhancing the coherence of the generated music.
WuYun: Exploring hierarchical skeleton-guided melody generation using knowledge-enhanced deep learning
Jan 11, 2023Although deep learning has revolutionized music generation, existing methods for structured melody generation follow an end-to-end left-to-right note-by-note generative paradigm and treat each note equally. Here, we present WuYun, a knowledge-enhanced deep learning architecture for improving the structure of generated melodies, which first generates the most structurally important notes to construct a melodic skeleton and subsequently infills it with dynamically decorative notes into a full-fledged melody. Specifically, we use music domain knowledge to extract melodic skeletons and employ sequence learning to reconstruct them, which serve as additional knowledge to provide auxiliary guidance for the melody generation process. We demonstrate that WuYun can generate melodies with better long-term structure and musicality and outperforms other state-of-the-art methods by 0.51 on average on all subjective evaluation metrics. Our study provides a multidisciplinary lens to design melodic hierarchical structures and bridge the gap between data-driven and knowledge-based approaches for numerous music generation tasks.
SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
Nov 02, 2022While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified Stochastic Differential Music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. The proposed SDMuse follows a two-stage pipeline to achieve music generation and editing on top of a hybrid representation including pianoroll and MIDI-event. In particular, SDMuse first generates/edits pianoroll by iteratively denoising through a stochastic differential equation (SDE) based on a diffusion model generative prior, and then refines the generated pianoroll and predicts MIDI-event tokens auto-regressively. We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022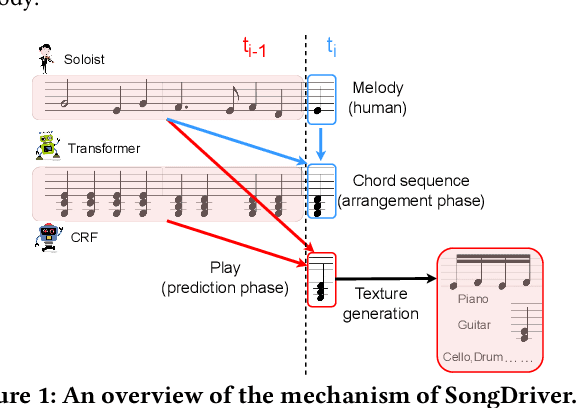
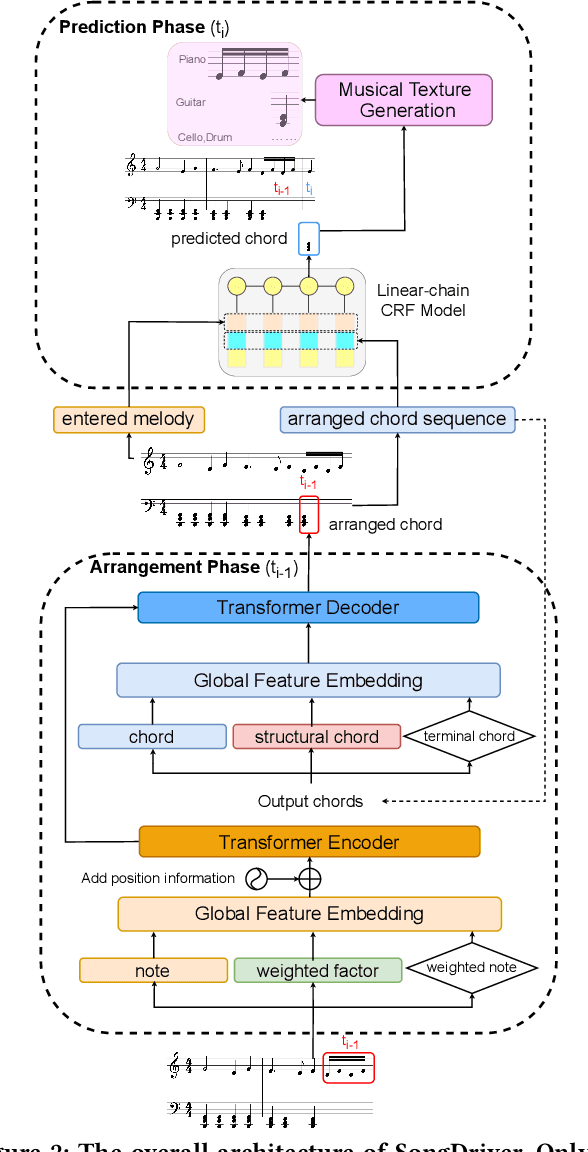
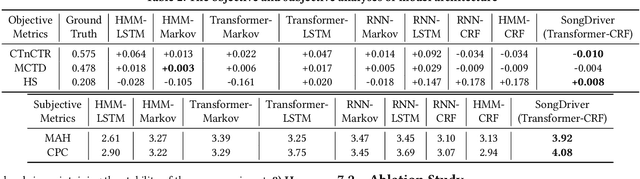
Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.
ReLyMe: Improving Lyric-to-Melody Generation by Incorporating Lyric-Melody Relationships
Jul 12, 2022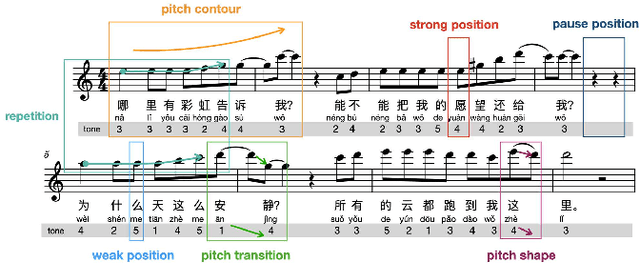
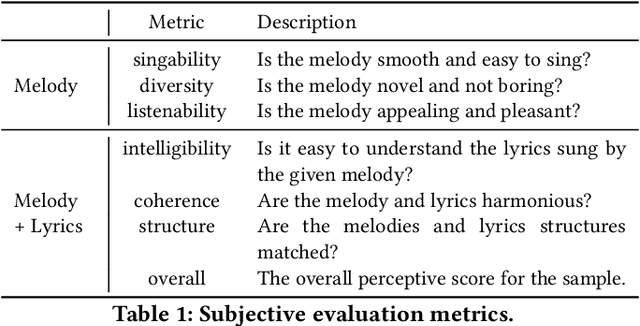
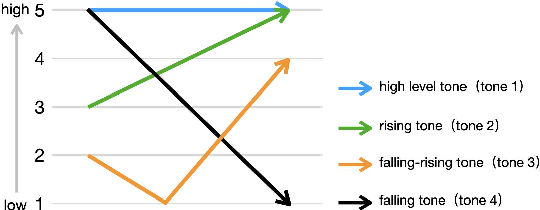
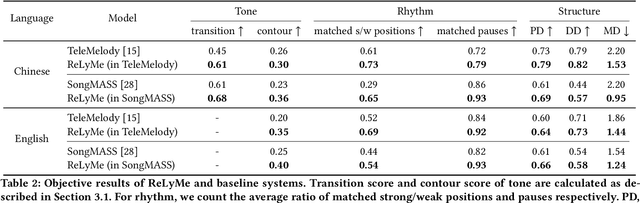
Lyric-to-melody generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies. Specifically, we first introduce several principles that lyrics and melodies should follow in terms of tone, rhythm, and structure relationships. These principles are then integrated into neural network lyric-to-melody models by adding corresponding constraints during the decoding process to improve the harmony between lyrics and melodies. We use a series of objective and subjective metrics to evaluate the generated melodies. Experiments on both English and Chinese song datasets show the effectiveness of ReLyMe, demonstrating the superiority of incorporating lyric-melody relationships from the music domain into neural lyric-to-melody generation.
Automatic Song Translation for Tonal Languages
Mar 25, 2022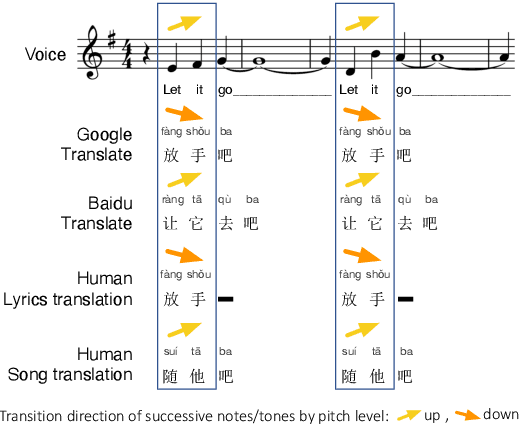
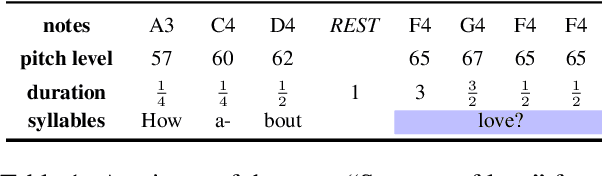
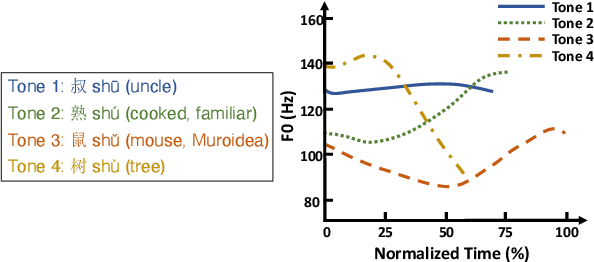
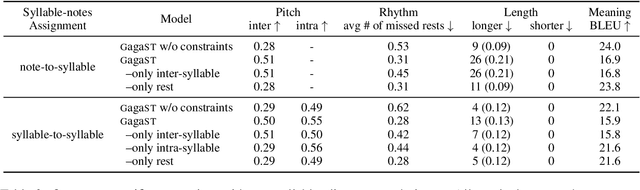
This paper develops automatic song translation (AST) for tonal languages and addresses the unique challenge of aligning words' tones with melody of a song in addition to conveying the original meaning. We propose three criteria for effective AST -- preserving meaning, singability and intelligibility -- and design metrics for these criteria. We develop a new benchmark for English--Mandarin song translation and develop an unsupervised AST system, Guided AliGnment for Automatic Song Translation (GagaST), which combines pre-training with three decoding constraints. Both automatic and human evaluations show GagaST successfully balances semantics and singability.
S3T: Self-Supervised Pre-training with Swin Transformer for Music Classification
Feb 21, 2022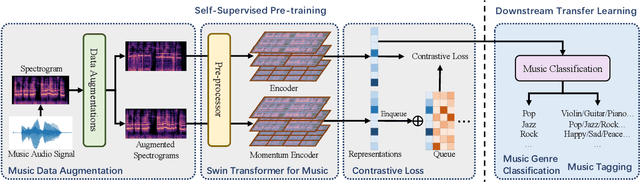
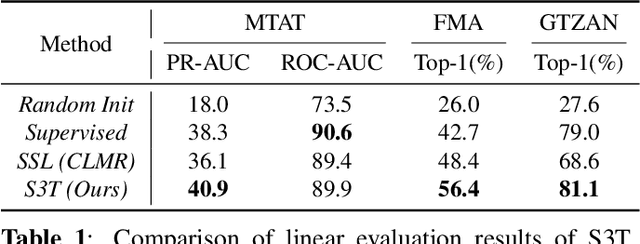
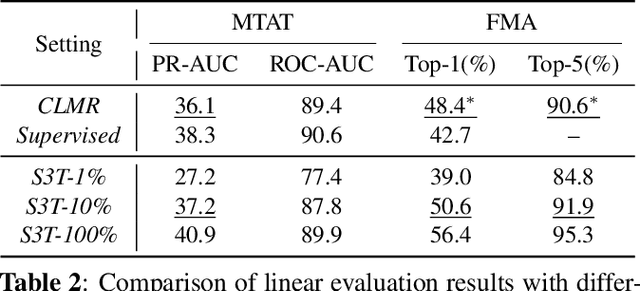
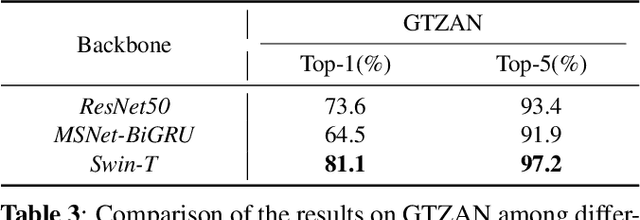
In this paper, we propose S3T, a self-supervised pre-training method with Swin Transformer for music classification, aiming to learn meaningful music representations from massive easily accessible unlabeled music data. S3T introduces a momentum-based paradigm, MoCo, with Swin Transformer as its feature extractor to music time-frequency domain. For better music representations learning, S3T contributes a music data augmentation pipeline and two specially designed pre-processors. To our knowledge, S3T is the first method combining the Swin Transformer with a self-supervised learning method for music classification. We evaluate S3T on music genre classification and music tagging tasks with linear classifiers trained on learned representations. Experimental results show that S3T outperforms the previous self-supervised method (CLMR) by 12.5 percents top-1 accuracy and 4.8 percents PR-AUC on two tasks respectively, and also surpasses the task-specific state-of-the-art supervised methods. Besides, S3T shows advances in label efficiency using only 10% labeled data exceeding CLMR on both tasks with 100% labeled data.
TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method
Sep 20, 2021
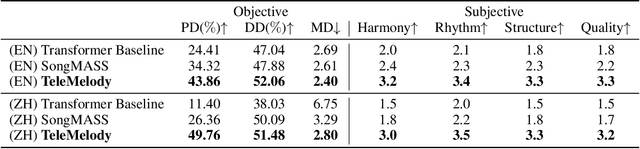
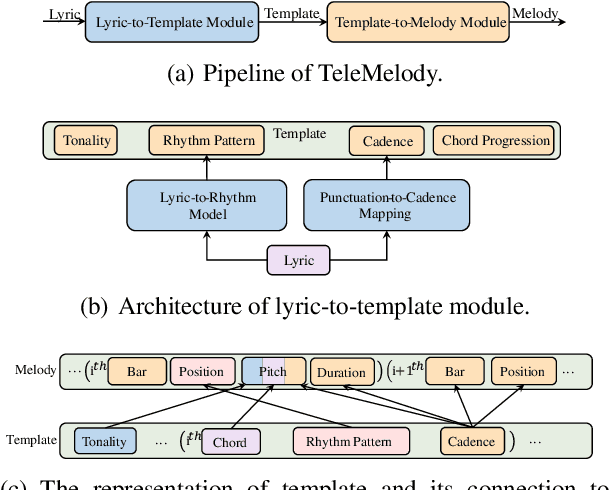
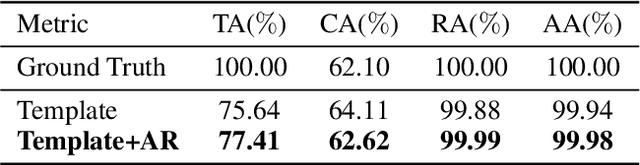
Lyric-to-melody generation is an important task in automatic songwriting. Previous lyric-to-melody generation systems usually adopt end-to-end models that directly generate melodies from lyrics, which suffer from several issues: 1) lack of paired lyric-melody training data; 2) lack of control on generated melodies. In this paper, we develop TeleMelody, a two-stage lyric-to-melody generation system with music template (e.g., tonality, chord progression, rhythm pattern, and cadence) to bridge the gap between lyrics and melodies (i.e., the system consists of a lyric-to-template module and a template-to-melody module). TeleMelody has two advantages. First, it is data efficient. The template-to-melody module is trained in a self-supervised way (i.e., the source template is extracted from the target melody) that does not need any lyric-melody paired data. The lyric-to-template module is made up of some rules and a lyric-to-rhythm model, which is trained with paired lyric-rhythm data that is easier to obtain than paired lyric-melody data. Second, it is controllable. The design of template ensures that the generated melodies can be controlled by adjusting the musical elements in template. Both subjective and objective experimental evaluations demonstrate that TeleMelody generates melodies with higher quality, better controllability, and less requirement on paired lyric-melody data than previous generation systems.
PDAugment: Data Augmentation by Pitch and Duration Adjustments for Automatic Lyrics Transcription
Sep 17, 2021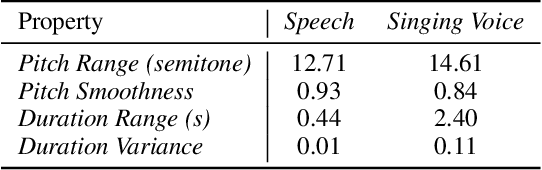
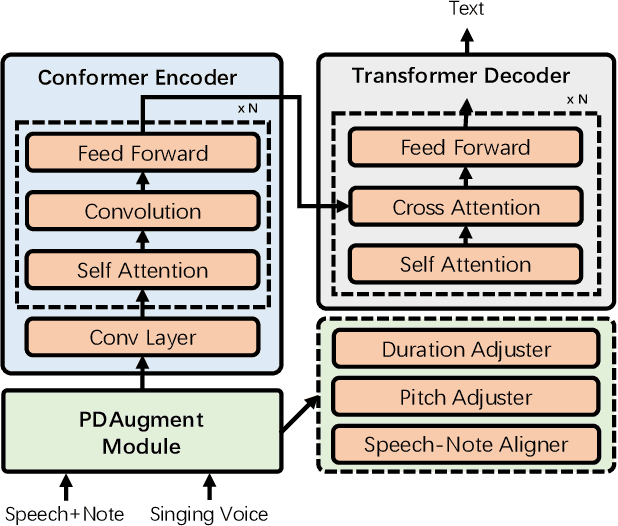
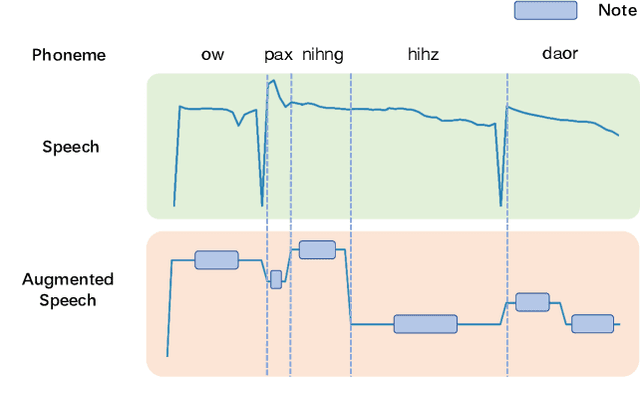

Automatic lyrics transcription (ALT), which can be regarded as automatic speech recognition (ASR) on singing voice, is an interesting and practical topic in academia and industry. ALT has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. Considering that there is a large amount of ASR training data, a straightforward method is to leverage ASR data to enhance ALT training. However, the improvement is marginal when training the ALT system directly with ASR data, because of the gap between the singing voice and standard speech data which is rooted in music-specific acoustic characteristics in singing voice. In this paper, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice. Experiments on DSing30 and Dali corpus show that the ALT system equipped with our PDAugment outperforms previous state-of-the-art systems by 5.9% and 18.1% WERs respectively, demonstrating the effectiveness of PDAugment for ALT.