 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Mismatch Risk: A Prototype-Based Routing Framework for Zero-shot LLM-generated Text Detection
Feb 01, 2026Zero-shot methods detect LLM-generated text by computing statistical signatures using a surrogate model. Existing approaches typically employ a fixed surrogate for all inputs regardless of the unknown source. We systematically examine this design and find that detection performance varies substantially depending on surrogate-source alignment. We observe that while no single surrogate achieves optimal performance universally, a well-matched surrogate typically exists within a diverse pool for any given input. This finding transforms robust detection into a routing problem: selecting the most appropriate surrogate for each input. We propose DetectRouter, a prototype-based framework that learns text-detector affinity through two-stage training. The first stage constructs discriminative prototypes from white-box models; the second generalizes to black-box sources by aligning geometric distances with observed detection scores. Experiments on EvoBench and MAGE benchmarks demonstrate consistent improvements across multiple detection criteria and model families.
Zenith: Scaling up Ranking Models for Billion-scale Livestreaming Recommendation
Jan 29, 2026Accurately capturing feature interactions is essential in recommender systems, and recent trends show that scaling up model capacity could be a key driver for next-level predictive performance. While prior work has explored various model architectures to capture multi-granularity feature interactions, relatively little attention has been paid to efficient feature handling and scaling model capacity without incurring excessive inference latency. In this paper, we address this by presenting Zenith, a scalable and efficient ranking architecture that learns complex feature interactions with minimal runtime overhead. Zenith is designed to handle a few high-dimensional Prime Tokens with Token Fusion and Token Boost modules, which exhibits superior scaling laws compared to other state-of-the-art ranking methods, thanks to its improved token heterogeneity. Its real-world effectiveness is demonstrated by deploying the architecture to TikTok Live, a leading online livestreaming platform that attracts billions of users globally. Our A/B test shows that Zenith achieves +1.05%/-1.10% in online CTR AUC and Logloss, and realizes +9.93% gains in Quality Watch Session / User and +8.11% in Quality Watch Duration / User.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
When AI Settles Down: Late-Stage Stability as a Signature of AI-Generated Text Detection
Jan 08, 2026Zero-shot detection methods for AI-generated text typically aggregate token-level statistics across entire sequences, overlooking the temporal dynamics inherent to autoregressive generation. We analyze over 120k text samples and reveal Late-Stage Volatility Decay: AI-generated text exhibits rapidly stabilizing log probability fluctuations as generation progresses, while human writing maintains higher variability throughout. This divergence peaks in the second half of sequences, where AI-generated text shows 24--32\% lower volatility. Based on this finding, we propose two simple features: Derivative Dispersion and Local Volatility, which computed exclusively from late-stage statistics. Without perturbation sampling or additional model access, our method achieves state-of-the-art performance on EvoBench and MAGE benchmarks and demonstrates strong complementarity with existing global methods.
Memory Bear AI A Breakthrough from Memory to Cognition Toward Artificial General Intelligence
Dec 17, 2025Large language models (LLMs) face inherent limitations in memory, including restricted context windows, long-term knowledge forgetting, redundant information accumulation, and hallucination generation. These issues severely constrain sustained dialogue and personalized services. This paper proposes the Memory Bear system, which constructs a human-like memory architecture grounded in cognitive science principles. By integrating multimodal information perception, dynamic memory maintenance, and adaptive cognitive services, Memory Bear achieves a full-chain reconstruction of LLM memory mechanisms. Across domains such as healthcare, enterprise operations, and education, Memory Bear demonstrates substantial engineering innovation and performance breakthroughs. It significantly improves knowledge fidelity and retrieval efficiency in long-term conversations, reduces hallucination rates, and enhances contextual adaptability and reasoning capability through memory-cognition integration. Experimental results show that, compared with existing solutions (e.g., Mem0, MemGPT, Graphiti), Memory Bear outperforms them across key metrics, including accuracy, token efficiency, and response latency. This marks a crucial step forward in advancing AI from "memory" to "cognition".
Towards Robust Protective Perturbation against DeepFake Face Swapping
Dec 08, 2025DeepFake face swapping enables highly realistic identity forgeries, posing serious privacy and security risks. A common defence embeds invisible perturbations into images, but these are fragile and often destroyed by basic transformations such as compression or resizing. In this paper, we first conduct a systematic analysis of 30 transformations across six categories and show that protection robustness is highly sensitive to the choice of training transformations, making the standard Expectation over Transformation (EOT) with uniform sampling fundamentally suboptimal. Motivated by this, we propose Expectation Over Learned distribution of Transformation (EOLT), the framework to treat transformation distribution as a learnable component rather than a fixed design choice. Specifically, EOLT employs a policy network that learns to automatically prioritize critical transformations and adaptively generate instance-specific perturbations via reinforcement learning, enabling explicit modeling of defensive bottlenecks while maintaining broad transferability. Extensive experiments demonstrate that our method achieves substantial improvements over state-of-the-art approaches, with 26% higher average robustness and up to 30% gains on challenging transformation categories.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025



We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Unbiased Online Curvature Approximation for Regularized Graph Continual Learning
Sep 16, 2025



Graph continual learning (GCL) aims to learn from a continuous sequence of graph-based tasks. Regularization methods are vital for preventing catastrophic forgetting in GCL, particularly in the challenging replay-free, class-incremental setting, where each task consists of a set of unique classes. In this work, we first establish a general regularization framework for GCL based on the curved parameter space induced by the Fisher information matrix (FIM). We show that the dominant Elastic Weight Consolidation (EWC) and its variants are a special case within this framework, using a diagonal approximation of the empirical FIM based on parameters from previous tasks. To overcome their limitations, we propose a new unbiased online curvature approximation of the full FIM based on the model's current learning state. Our method directly estimates the regularization term in an online manner without explicitly evaluating and storing the FIM itself. This enables the model to better capture the loss landscape during learning new tasks while retaining the knowledge learned from previous tasks. Extensive experiments on three graph datasets demonstrate that our method significantly outperforms existing regularization-based methods, achieving a superior trade-off between stability (retaining old knowledge) and plasticity (acquiring new knowledge).
Knowledge Graph Tokenization for Behavior-Aware Generative Next POI Recommendation
Sep 15, 2025



Generative paradigm, especially powered by Large Language Models (LLMs), has emerged as a new solution to the next point-of-interest (POI) recommendation. Pioneering studies usually adopt a two-stage pipeline, starting with a tokenizer converting POIs into discrete identifiers that can be processed by LLMs, followed by POI behavior prediction tasks to instruction-tune LLM for next POI recommendation. Despite of remarkable progress, they still face two limitations: (1) existing tokenizers struggle to encode heterogeneous signals in the recommendation data, suffering from information loss issue, and (2) previous instruction-tuning tasks only focus on users' POI visit behavior while ignore other behavior types, resulting in insufficient understanding of mobility. To address these limitations, we propose KGTB (Knowledge Graph Tokenization for Behavior-aware generative next POI recommendation). Specifically, KGTB organizes the recommendation data in a knowledge graph (KG) format, of which the structure can seamlessly preserve the heterogeneous information. Then, a KG-based tokenizer is developed to quantize each node into an individual structural ID. This process is supervised by the KG's structure, thus reducing the loss of heterogeneous information. Using generated IDs, KGTB proposes multi-behavior learning that introduces multiple behavior-specific prediction tasks for LLM fine-tuning, e.g., POI, category, and region visit behaviors. Learning on these behavior tasks provides LLMs with comprehensive insights on the target POI visit behavior. Experiments on four real-world city datasets demonstrate the superior performance of KGTB.
AIGI-Holmes: Towards Explainable and Generalizable AI-Generated Image Detection via Multimodal Large Language Models
Jul 03, 2025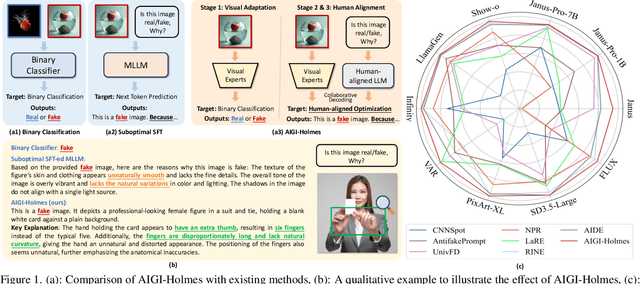
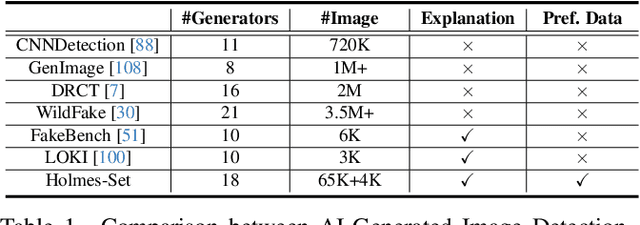
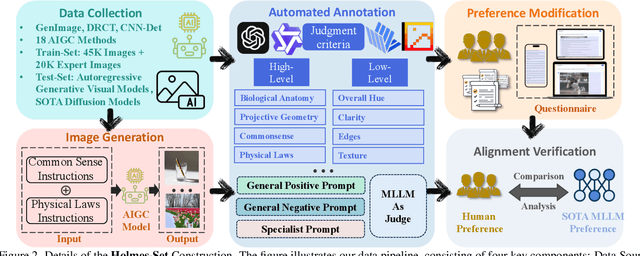
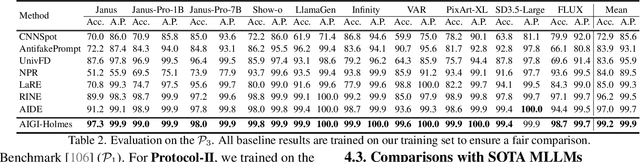
The rapid development of AI-generated content (AIGC) technology has led to the misuse of highly realistic AI-generated images (AIGI) in spreading misinformation, posing a threat to public information security. Although existing AIGI detection techniques are generally effective, they face two issues: 1) a lack of human-verifiable explanations, and 2) a lack of generalization in the latest generation technology. To address these issues, we introduce a large-scale and comprehensive dataset, Holmes-Set, which includes the Holmes-SFTSet, an instruction-tuning dataset with explanations on whether images are AI-generated, and the Holmes-DPOSet, a human-aligned preference dataset. Our work introduces an efficient data annotation method called the Multi-Expert Jury, enhancing data generation through structured MLLM explanations and quality control via cross-model evaluation, expert defect filtering, and human preference modification. In addition, we propose Holmes Pipeline, a meticulously designed three-stage training framework comprising visual expert pre-training, supervised fine-tuning, and direct preference optimization. Holmes Pipeline adapts multimodal large language models (MLLMs) for AIGI detection while generating human-verifiable and human-aligned explanations, ultimately yielding our model AIGI-Holmes. During the inference stage, we introduce a collaborative decoding strategy that integrates the model perception of the visual expert with the semantic reasoning of MLLMs, further enhancing the generalization capabilities. Extensive experiments on three benchmarks validate the effectiveness of our AIGI-Holmes.