 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull end-to-end diagnostic workflow automation of 3D OCT via foundation model-driven AI for retinal diseases
Feb 03, 2026Optical coherence tomography (OCT) has revolutionized retinal disease diagnosis with its high-resolution and three-dimensional imaging nature, yet its full diagnostic automation in clinical practices remains constrained by multi-stage workflows and conventional single-slice single-task AI models. We present Full-process OCT-based Clinical Utility System (FOCUS), a foundation model-driven framework enabling end-to-end automation of 3D OCT retinal disease diagnosis. FOCUS sequentially performs image quality assessment with EfficientNetV2-S, followed by abnormality detection and multi-disease classification using a fine-tuned Vision Foundation Model. Crucially, FOCUS leverages a unified adaptive aggregation method to intelligently integrate 2D slices-level predictions into comprehensive 3D patient-level diagnosis. Trained and tested on 3,300 patients (40,672 slices), and externally validated on 1,345 patients (18,498 slices) across four different-tier centers and diverse OCT devices, FOCUS achieved high F1 scores for quality assessment (99.01%), abnormally detection (97.46%), and patient-level diagnosis (94.39%). Real-world validation across centers also showed stable performance (F1: 90.22%-95.24%). In human-machine comparisons, FOCUS matched expert performance in abnormality detection (F1: 95.47% vs 90.91%) and multi-disease diagnosis (F1: 93.49% vs 91.35%), while demonstrating better efficiency. FOCUS automates the image-to-diagnosis pipeline, representing a critical advance towards unmanned ophthalmology with a validated blueprint for autonomous screening to enhance population scale retinal care accessibility and efficiency.
CoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Jan 16, 2026Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.
SimRPD: Optimizing Recruitment Proactive Dialogue Agents through Simulator-Based Data Evaluation and Selection
Jan 08, 2026Task-oriented proactive dialogue agents play a pivotal role in recruitment, particularly for steering conversations towards specific business outcomes, such as acquiring social-media contacts for private-channel conversion. Although supervised fine-tuning and reinforcement learning have proven effective for training such agents, their performance is heavily constrained by the scarcity of high-quality, goal-oriented domain-specific training data. To address this challenge, we propose SimRPD, a three-stage framework for training recruitment proactive dialogue agents. First, we develop a high-fidelity user simulator to synthesize large-scale conversational data through multi-turn online dialogue. Then we introduce a multi-dimensional evaluation framework based on Chain-of-Intention (CoI) to comprehensively assess the simulator and effectively select high-quality data, incorporating both global-level and instance-level metrics. Finally, we train the recruitment proactive dialogue agent on the selected dataset. Experiments in a real-world recruitment scenario demonstrate that SimRPD outperforms existing simulator-based data selection strategies, highlighting its practical value for industrial deployment and its potential applicability to other business-oriented dialogue scenarios.
TalkVerse: Democratizing Minute-Long Audio-Driven Video Generation
Dec 16, 2025We introduce TalkVerse, a large-scale, open corpus for single-person, audio-driven talking video generation designed to enable fair, reproducible comparison across methods. While current state-of-the-art systems rely on closed data or compute-heavy models, TalkVerse offers 2.3 million high-resolution (720p/1080p) audio-video synchronized clips totaling 6.3k hours. These are curated from over 60k hours of video via a transparent pipeline that includes scene-cut detection, aesthetic assessment, strict audio-visual synchronization checks, and comprehensive annotations including 2D skeletons and structured visual/audio-style captions. Leveraging TalkVerse, we present a reproducible 5B DiT baseline built on Wan2.2-5B. By utilizing a video VAE with a high downsampling ratio and a sliding window mechanism with motion-frame context, our model achieves minute-long generation with low drift. It delivers comparable lip-sync and visual quality to the 14B Wan-S2V model but with 10$\times$ lower inference cost. To enhance storytelling in long videos, we integrate an MLLM director to rewrite prompts based on audio and visual cues. Furthermore, our model supports zero-shot video dubbing via controlled latent noise injection. We open-source the dataset, training recipes, and 5B checkpoints to lower barriers for research in audio-driven human video generation. Project Page: https://zhenzhiwang.github.io/talkverse/
PAVE: An End-to-End Dataset for Production Autonomous Vehicle Evaluation
Nov 19, 2025Most existing autonomous-driving datasets (e.g., KITTI, nuScenes, and the Waymo Perception Dataset), collected by human-driving mode or unidentified driving mode, can only serve as early training for the perception and prediction of autonomous vehicles (AVs). To evaluate the real behavioral safety of AVs controlled in the black box, we present the first end-to-end benchmark dataset collected entirely by autonomous-driving mode in the real world. This dataset contains over 100 hours of naturalistic data from multiple production autonomous-driving vehicle models in the market. We segment the original data into 32,727 key frames, each consisting of four synchronized camera images and high-precision GNSS/IMU data (0.8 cm localization accuracy). For each key frame, 20 Hz vehicle trajectories spanning the past 6 s and future 5 s are provided, along with detailed 2D annotations of surrounding vehicles, pedestrians, traffic lights, and traffic signs. These key frames have rich scenario-level attributes, including driver intent, area type (covering highways, urban roads, and residential areas), lighting (day, night, or dusk), weather (clear or rain), road surface (paved or unpaved), traffic and vulnerable road users (VRU) density, traffic lights, and traffic signs (warning, prohibition, and indication). To evaluate the safety of AVs, we employ an end-to-end motion planning model that predicts vehicle trajectories with an Average Displacement Error (ADE) of 1.4 m on autonomous-driving frames. The dataset continues to expand by over 10 hours of new data weekly, thereby providing a sustainable foundation for research on AV driving behavior analysis and safety evaluation. The PAVE dataset is publicly available at https://hkustgz-my.sharepoint.com/:f:/g/personal/kema_hkust-gz_edu_cn/IgDXyoHKfdGnSZ3JbbidjduMAXxs-Z3NXzm005A_Ix9tr0Q?e=9HReCu.
DoGCLR: Dominance-Game Contrastive Learning Network for Skeleton-Based Action Recognition
Nov 19, 2025Existing self-supervised contrastive learning methods for skeleton-based action recognition often process all skeleton regions uniformly, and adopt a first-in-first-out (FIFO) queue to store negative samples, which leads to motion information loss and non-optimal negative sample selection. To address these challenges, this paper proposes Dominance-Game Contrastive Learning network for skeleton-based action Recognition (DoGCLR), a self-supervised framework based on game theory. DoGCLR models the construction of positive and negative samples as a dynamic Dominance Game, where both sample types interact to reach an equilibrium that balances semantic preservation and discriminative strength. Specifically, a spatio-temporal dual weight localization mechanism identifies key motion regions and guides region-wise augmentations to enhance motion diversity while maintaining semantics. In parallel, an entropy-driven dominance strategy manages the memory bank by retaining high entropy (hard) negatives and replacing low-entropy (weak) ones, ensuring consistent exposure to informative contrastive signals. Extensive experiments are conducted on NTU RGB+D and PKU-MMD datasets. On NTU RGB+D 60 X-Sub/X-View, DoGCLR achieves 81.1%/89.4% accuracy, and on NTU RGB+D 120 X-Sub/X-Set, DoGCLR achieves 71.2%/75.5% accuracy, surpassing state-of-the-art methods by 0.1%, 2.7%, 1.1%, and 2.3%, respectively. On PKU-MMD Part I/Part II, DoGCLR performs comparably to the state-of-the-art methods and achieves a 1.9% higher accuracy on Part II, highlighting its strong robustness on more challenging scenarios.
Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids
Nov 14, 2025



Estimating the geometric and volumetric properties of transparent deformable liquids is challenging due to optical complexities and dynamic surface deformations induced by container movements. Autonomous robots performing precise liquid manipulation tasks, such as dispensing, aspiration, and mixing, must handle containers in ways that inevitably induce these deformations, complicating accurate liquid state assessment. Current datasets lack comprehensive physics-informed simulation data representing realistic liquid behaviors under diverse dynamic scenarios. To bridge this gap, we introduce Phys-Liquid, a physics-informed dataset comprising 97,200 simulation images and corresponding 3D meshes, capturing liquid dynamics across multiple laboratory scenes, lighting conditions, liquid colors, and container rotations. To validate the realism and effectiveness of Phys-Liquid, we propose a four-stage reconstruction and estimation pipeline involving liquid segmentation, multi-view mask generation, 3D mesh reconstruction, and real-world scaling. Experimental results demonstrate improved accuracy and consistency in reconstructing liquid geometry and volume, outperforming existing benchmarks. The dataset and associated validation methods facilitate future advancements in transparent liquid perception tasks. The dataset and code are available at https://dualtransparency.github.io/Phys-Liquid/.
Learn Faster and Remember More: Balancing Exploration and Exploitation for Continual Test-time Adaptation
Aug 18, 2025Continual Test-Time Adaptation (CTTA) aims to adapt a source pre-trained model to continually changing target domains during inference. As a fundamental principle, an ideal CTTA method should rapidly adapt to new domains (exploration) while retaining and exploiting knowledge from previously encountered domains to handle similar domains in the future. Despite significant advances, balancing exploration and exploitation in CTTA is still challenging: 1) Existing methods focus on adjusting predictions based on deep-layer outputs of neural networks. However, domain shifts typically affect shallow features, which are inefficient to be adjusted from deep predictions, leading to dilatory exploration; 2) A single model inevitably forgets knowledge of previous domains during the exploration, making it incapable of exploiting historical knowledge to handle similar future domains. To address these challenges, this paper proposes a mean teacher framework that strikes an appropriate Balance between Exploration and Exploitation (BEE) during the CTTA process. For the former challenge, we introduce a Multi-level Consistency Regularization (MCR) loss that aligns the intermediate features of the student and teacher models, accelerating adaptation to the current domain. For the latter challenge, we employ a Complementary Anchor Replay (CAR) mechanism to reuse historical checkpoints (anchors), recovering complementary knowledge for diverse domains. Experiments show that our method significantly outperforms state-of-the-art methods on several benchmarks, demonstrating its effectiveness for CTTA tasks.
Architectural Co-Design for Zero-Shot Anomaly Detection: Decoupling Representation and Dynamically Fusing Features in CLIP
Aug 11, 2025Pre-trained Vision-Language Models (VLMs) face a significant adaptation gap when applied to Zero-Shot Anomaly Detection (ZSAD), stemming from their lack of local inductive biases for dense prediction and their reliance on inflexible feature fusion paradigms. We address these limitations through an Architectural Co-Design framework that jointly refines feature representation and cross-modal fusion. Our method integrates a parameter-efficient Convolutional Low-Rank Adaptation (Conv-LoRA) adapter to inject local inductive biases for fine-grained representation, and introduces a Dynamic Fusion Gateway (DFG) that leverages visual context to adaptively modulate text prompts, enabling a powerful bidirectional fusion. Extensive experiments on diverse industrial and medical benchmarks demonstrate superior accuracy and robustness, validating that this synergistic co-design is critical for robustly adapting foundation models to dense perception tasks.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025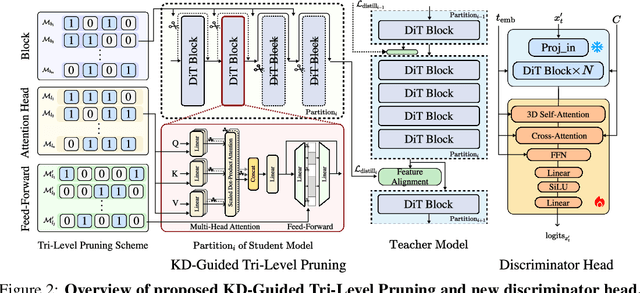
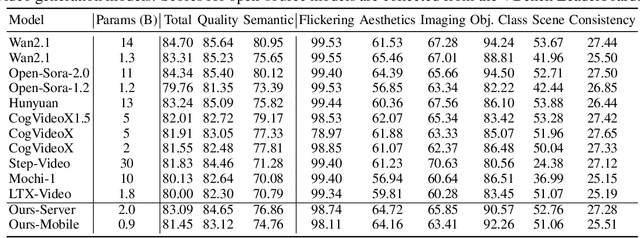

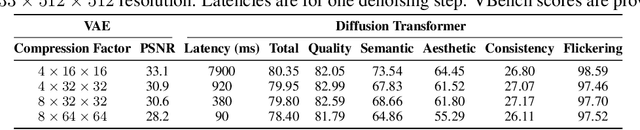
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.