 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIVE: End-to-End Instance-Specific Visual Explanations for Detection Transformers
Jun 01, 2026Visual explainability for object detection remains challenging due to the multi-instance nature of detection. Existing approaches predominantly adopt post-hoc paradigms, such as gradient-based or perturbation-based explanation methods, to interpret pretrained detectors. However, these methods require additional gradient computation or repeated model inference, resulting in limited efficiency. To address this issue, we propose an End-to-end Instance-specific Visual Explanation framework (EIVE) that directly generates instance-level saliency maps following the forward pass of Detection Transformer (DETR)-like models. Specifically, we reformulate the cross-attention mechanism in the decoder as an instance-level feature attribution pathway, so that the cross-attention of each object query corresponds to the visual attribution of its predicted instance. Based on this formulation, we design a cross-layer hybrid consensus fusion (CLHCF) module to aggregate cross-attention signals across decoder layers, producing stable and compact explanations. The explanation process of EIVE requires neither gradient computation nor input perturbation, yielding high computational efficiency, and applies to single- and multi-scale DETR-like object detectors. Finally, we present an attention-aware joint training strategy (AAJTS) as a training-oriented application, which imposes spatial constraints on cross-attention patterns to encourage stable and concentrated attribution representations, thereby improving both interpretability and detection performance. Experiments on MS COCO 2017, ExDark, and Cityscapes demonstrate that EIVE produces high-quality instance-level saliency maps and achieves performance comparable to, or better than, state-of-the-art post-hoc methods across standard metrics, while substantially improving explanation efficiency. Code is available at https://github.com/xjlDestiny/EIVE.git.
HiProto: Hierarchical Prototype Learning for Interpretable Object Detection Under Low-quality Conditions
Apr 15, 2026Interpretability is essential for deploying object detection systems in critical applications, especially under low-quality imaging conditions that degrade visual information and increase prediction uncertainty. Existing methods either enhance image quality or design complex architectures, but often lack interpretability and fail to improve semantic discrimination. In contrast, prototype learning enables interpretable modeling by associating features with class-centered semantics, which can provide more stable and interpretable representations under degradation. Motivated by this, we propose HiProto, a new paradigm for interpretable object detection based on hierarchical prototype learning. By constructing structured prototype representations across multiple feature levels, HiProto effectively models class-specific semantics, thereby enhancing both semantic discrimination and interpretability. Building upon prototype modeling, we first propose a Region-to-Prototype Contrastive Loss (RPC-Loss) to enhance the semantic focus of prototypes on target regions. Then, we propose a Prototype Regularization Loss (PR-Loss) to improve the distinctiveness among class prototypes. Finally, we propose a Scale-aware Pseudo Label Generation Strategy (SPLGS) to suppress mismatched supervision for RPC-Loss, thereby preserving the robustness of low-level prototype representations. Experiments on ExDark, RTTS, and VOC2012-FOG demonstrate that HiProto achieves competitive results while offering clear interpretability through prototype responses, without relying on image enhancement or complex architectures. Our code will be available at https://github.com/xjlDestiny/HiProto.git.
M3GCLR: Multi-View Mini-Max Infinite Skeleton-Data Game Contrastive Learning For Skeleton-Based Action Recognition
Mar 10, 2026In recent years, contrastive learning has drawn significant attention as an effective approach to reducing reliance on labeled data. However, existing methods for self-supervised skeleton-based action recognition still face three major limitations: insufficient modeling of view discrepancies, lack of effective adversarial mechanisms, and uncontrollable augmentation perturbations. To tackle these issues, we propose the Multi-view Mini-Max infinite skeleton-data Game Contrastive Learning for skeleton-based action Recognition (M3GCLR), a game-theoretic contrastive framework. First, we establish the Infinite Skeleton-data Game (ISG) model and the ISG equilibrium theorem, and further provide a rigorous proof, enabling mini-max optimization based on multi-view mutual information. Then, we generate normal-extreme data pairs through multi-view rotation augmentation and adopt temporally averaged input as a neutral anchor to achieve structural alignment, thereby explicitly characterizing perturbation strength. Next, leveraging the proposed equilibrium theorem, we construct a strongly adversarial mini-max skeleton-data game to encourage the model to mine richer action-discriminative information. Finally, we introduce the dual-loss equilibrium optimizer to optimize the game equilibrium, allowing the learning process to maximize action-relevant information while minimizing encoding redundancy, and we prove the equivalence between the proposed optimizer and the ISG model. Extensive Experiments show that M3GCLR achieves three-stream 82.1%, 85.8% accuracy on NTU RGB+D 60 (X-Sub, X-View) and 72.3%, 75.0% accuracy on NTU RGB+D 120 (X-Sub, X-Set). On PKU-MMD Part I and II, it attains 89.1%, 45.2% in three-stream respectively, all results matching or outperforming state-of-the-art performance. Ablation studies confirm the effectiveness of each component.
SDCoNet: Saliency-Driven Multi-Task Collaborative Network for Remote Sensing Object Detection
Jan 18, 2026In remote sensing images, complex backgrounds, weak object signals, and small object scales make accurate detection particularly challenging, especially under low-quality imaging conditions. A common strategy is to integrate single-image super-resolution (SR) before detection; however, such serial pipelines often suffer from misaligned optimization objectives, feature redundancy, and a lack of effective interaction between SR and detection. To address these issues, we propose a Saliency-Driven multi-task Collaborative Network (SDCoNet) that couples SR and detection through implicit feature sharing while preserving task specificity. SDCoNet employs the swin transformer-based shared encoder, where hierarchical window-shifted self-attention supports cross-task feature collaboration and adaptively balances the trade-off between texture refinement and semantic representation. In addition, a multi-scale saliency prediction module produces importance scores to select key tokens, enabling focused attention on weak object regions, suppression of background clutter, and suppression of adverse features introduced by multi-task coupling. Furthermore, a gradient routing strategy is introduced to mitigate optimization conflicts. It first stabilizes detection semantics and subsequently routes SR gradients along a detection-oriented direction, enabling the framework to guide the SR branch to generate high-frequency details that are explicitly beneficial for detection. Experiments on public datasets, including NWPU VHR-10-Split, DOTAv1.5-Split, and HRSSD-Split, demonstrate that the proposed method, while maintaining competitive computational efficiency, significantly outperforms existing mainstream algorithms in small object detection on low-quality remote sensing images. Our code is available at https://github.com/qiruo-ya/SDCoNet.
Fourier-RWKV: A Multi-State Perception Network for Efficient Image Dehazing
Dec 09, 2025Image dehazing is crucial for reliable visual perception, yet it remains highly challenging under real-world non-uniform haze conditions. Although Transformer-based methods excel at capturing global context, their quadratic computational complexity hinders real-time deployment. To address this, we propose Fourier Receptance Weighted Key Value (Fourier-RWKV), a novel dehazing framework based on a Multi-State Perception paradigm. The model achieves comprehensive haze degradation modeling with linear complexity by synergistically integrating three distinct perceptual states: (1) Spatial-form Perception, realized through the Deformable Quad-directional Token Shift (DQ-Shift) operation, which dynamically adjusts receptive fields to accommodate local haze variations; (2) Frequency-domain Perception, implemented within the Fourier Mix block, which extends the core WKV attention mechanism of RWKV from the spatial domain to the Fourier domain, preserving the long-range dependencies essential for global haze estimation while mitigating spatial attenuation; (3) Semantic-relation Perception, facilitated by the Semantic Bridge Module (SBM), which utilizes Dynamic Semantic Kernel Fusion (DSK-Fusion) to precisely align encoder-decoder features and suppress artifacts. Extensive experiments on multiple benchmarks demonstrate that Fourier-RWKV delivers state-of-the-art performance across diverse haze scenarios while significantly reducing computational overhead, establishing a favorable trade-off between restoration quality and practical efficiency. Code is available at: https://github.com/Dilizlr/Fourier-RWKV.
DoGCLR: Dominance-Game Contrastive Learning Network for Skeleton-Based Action Recognition
Nov 19, 2025Existing self-supervised contrastive learning methods for skeleton-based action recognition often process all skeleton regions uniformly, and adopt a first-in-first-out (FIFO) queue to store negative samples, which leads to motion information loss and non-optimal negative sample selection. To address these challenges, this paper proposes Dominance-Game Contrastive Learning network for skeleton-based action Recognition (DoGCLR), a self-supervised framework based on game theory. DoGCLR models the construction of positive and negative samples as a dynamic Dominance Game, where both sample types interact to reach an equilibrium that balances semantic preservation and discriminative strength. Specifically, a spatio-temporal dual weight localization mechanism identifies key motion regions and guides region-wise augmentations to enhance motion diversity while maintaining semantics. In parallel, an entropy-driven dominance strategy manages the memory bank by retaining high entropy (hard) negatives and replacing low-entropy (weak) ones, ensuring consistent exposure to informative contrastive signals. Extensive experiments are conducted on NTU RGB+D and PKU-MMD datasets. On NTU RGB+D 60 X-Sub/X-View, DoGCLR achieves 81.1%/89.4% accuracy, and on NTU RGB+D 120 X-Sub/X-Set, DoGCLR achieves 71.2%/75.5% accuracy, surpassing state-of-the-art methods by 0.1%, 2.7%, 1.1%, and 2.3%, respectively. On PKU-MMD Part I/Part II, DoGCLR performs comparably to the state-of-the-art methods and achieves a 1.9% higher accuracy on Part II, highlighting its strong robustness on more challenging scenarios.
T-Net: Deep Stacked Scale-Iteration Network for Image Dehazing
Jun 05, 2021
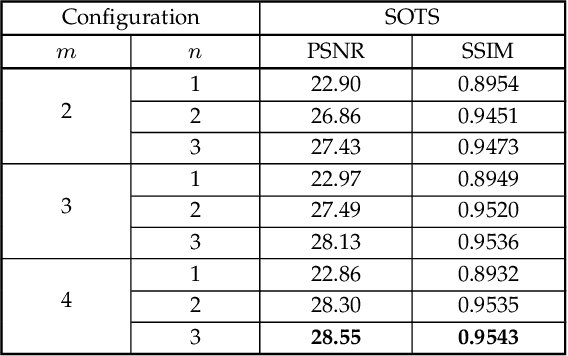
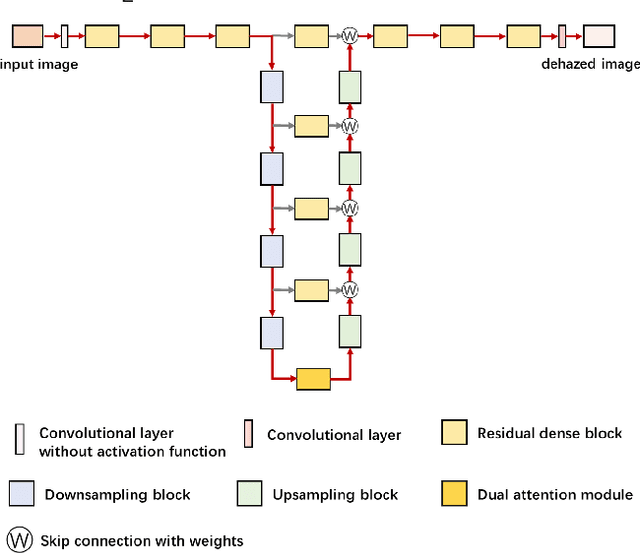
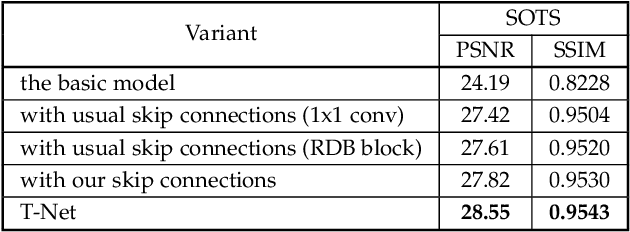
Hazy images reduce the visibility of the image content, and haze will lead to failure in handling subsequent computer vision tasks. In this paper, we address the problem of image dehazing by proposing a dehazing network named T-Net, which consists of a backbone network based on the U-Net architecture and a dual attention module. And it can achieve multi-scale feature fusion by using skip connections with a new fusion strategy. Furthermore, by repeatedly unfolding the plain T-Net, Stack T-Net is proposed to take advantage of the dependence of deep features across stages via a recursive strategy. In order to reduce network parameters, the intra-stage recursive computation of ResNet is adopted in our Stack T-Net. And we take both the stage-wise result and the original hazy image as input to each T-Net and finally output the prediction of clean image. Experimental results on both synthetic and real-world images demonstrate that our plain T-Net and the advanced Stack T-Net perform favorably against the state-of-the-art dehazing algorithms, and show that our Stack T-Net could further improve the dehazing effect, demonstrating the effectiveness of the recursive strategy.