 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025



Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
HarmonySeg: Tubular Structure Segmentation with Deep-Shallow Feature Fusion and Growth-Suppression Balanced Loss
Apr 10, 2025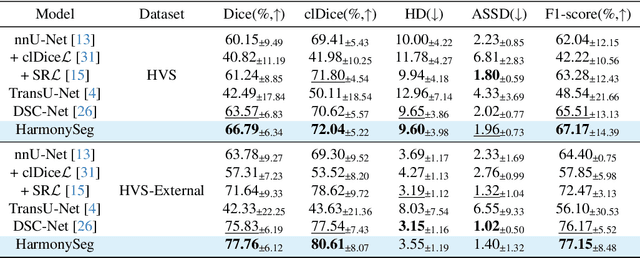
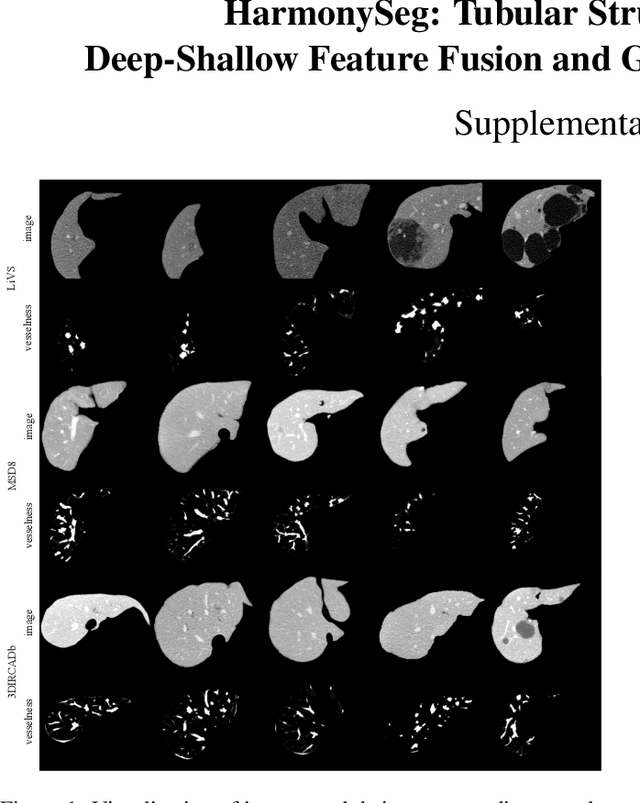

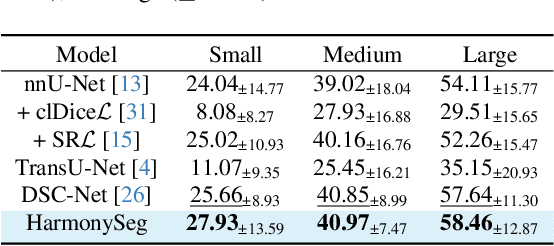
Accurate segmentation of tubular structures in medical images, such as vessels and airway trees, is crucial for computer-aided diagnosis, radiotherapy, and surgical planning. However, significant challenges exist in algorithm design when faced with diverse sizes, complex topologies, and (often) incomplete data annotation of these structures. We address these difficulties by proposing a new tubular structure segmentation framework named HarmonySeg. First, we design a deep-to-shallow decoder network featuring flexible convolution blocks with varying receptive fields, which enables the model to effectively adapt to tubular structures of different scales. Second, to highlight potential anatomical regions and improve the recall of small tubular structures, we incorporate vesselness maps as auxiliary information. These maps are aligned with image features through a shallow-and-deep fusion module, which simultaneously eliminates unreasonable candidates to maintain high precision. Finally, we introduce a topology-preserving loss function that leverages contextual and shape priors to balance the growth and suppression of tubular structures, which also allows the model to handle low-quality and incomplete annotations. Extensive quantitative experiments are conducted on four public datasets. The results show that our model can accurately segment 2D and 3D tubular structures and outperform existing state-of-the-art methods. External validation on a private dataset also demonstrates good generalizability.
Ultrasound-Guided Robotic Blood Drawing and In Vivo Studies on Submillimetre Vessels of Rats
Apr 04, 2025Billions of vascular access procedures are performed annually worldwide, serving as a crucial first step in various clinical diagnostic and therapeutic procedures. For pediatric or elderly individuals, whose vessels are small in size (typically 2 to 3 mm in diameter for adults and less than 1 mm in children), vascular access can be highly challenging. This study presents an image-guided robotic system aimed at enhancing the accuracy of difficult vascular access procedures. The system integrates a 6-DoF robotic arm with a 3-DoF end-effector, ensuring precise navigation and needle insertion. Multi-modal imaging and sensing technologies have been utilized to endow the medical robot with precision and safety, while ultrasound imaging guidance is specifically evaluated in this study. To evaluate in vivo vascular access in submillimeter vessels, we conducted ultrasound-guided robotic blood drawing on the tail veins (with a diameter of 0.7 plus or minus 0.2 mm) of 40 rats. The results demonstrate that the system achieved a first-attempt success rate of 95 percent. The high first-attempt success rate in intravenous vascular access, even with small blood vessels, demonstrates the system's effectiveness in performing these procedures. This capability reduces the risk of failed attempts, minimizes patient discomfort, and enhances clinical efficiency.
MedCL: Learning Consistent Anatomy Distribution for Scribble-supervised Medical Image Segmentation
Mar 28, 2025



Curating large-scale fully annotated datasets is expensive, laborious, and cumbersome, especially for medical images. Several methods have been proposed in the literature that make use of weak annotations in the form of scribbles. However, these approaches require large amounts of scribble annotations, and are only applied to the segmentation of regular organs, which are often unavailable for the disease species that fall in the long-tailed distribution. Motivated by the fact that the medical labels have anatomy distribution priors, we propose a scribble-supervised clustering-based framework, called MedCL, to learn the inherent anatomy distribution of medical labels. Our approach consists of two steps: i) Mix the features with intra- and inter-image mix operations, and ii) Perform feature clustering and regularize the anatomy distribution at both local and global levels. Combined with a small amount of weak supervision, the proposed MedCL is able to segment both regular organs and challenging irregular pathologies. We implement MedCL based on SAM and UNet backbones, and evaluate the performance on three open datasets of regular structure (MSCMRseg), multiple organs (BTCV) and irregular pathology (MyoPS). It is shown that even with less scribble supervision, MedCL substantially outperforms the conventional segmentation methods. Our code is available at https://github.com/BWGZK/MedCL.
CDKFormer: Contextual Deviation Knowledge-Based Transformer for Long-Tail Trajectory Prediction
Mar 16, 2025Predicting the future movements of surrounding vehicles is essential for ensuring the safe operation and efficient navigation of autonomous vehicles (AVs) in urban traffic environments. Existing vehicle trajectory prediction methods primarily focus on improving overall performance, yet they struggle to address long-tail scenarios effectively. This limitation often leads to poor predictions in rare cases, significantly increasing the risk of safety incidents. Taking Argoverse 2 motion forecasting dataset as an example, we first investigate the long-tail characteristics in trajectory samples from two perspectives, individual motion and group interaction, and deriving deviation features to distinguish abnormal from regular scenarios. On this basis, we propose CDKFormer, a Contextual Deviation Knowledge-based Transformer model for long-tail trajectory prediction. CDKFormer integrates an attention-based scene context fusion module to encode spatiotemporal interaction and road topology. An additional deviation feature fusion module is proposed to capture the dynamic deviations in the target vehicle status. We further introduce a dual query-based decoder, supported by a multi-stream decoder block, to sequentially decode heterogeneous scene deviation features and generate multimodal trajectory predictions. Extensive experiments demonstrate that CDKFormer achieves state-of-the-art performance, significantly enhancing prediction accuracy and robustness for long-tailed trajectories compared to existing methods, thus advancing the reliability of AVs in complex real-world environments.
A Survey on Foundation-Model-Based Industrial Defect Detection
Feb 26, 2025
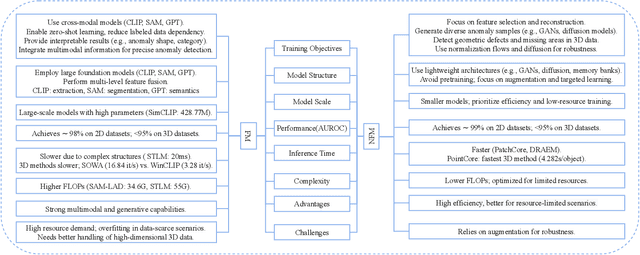
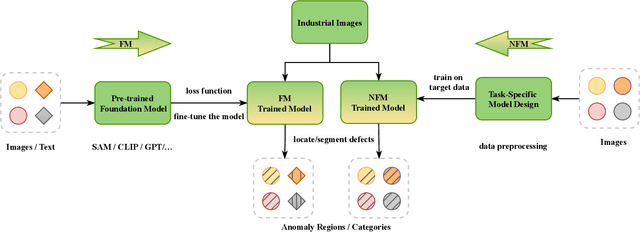
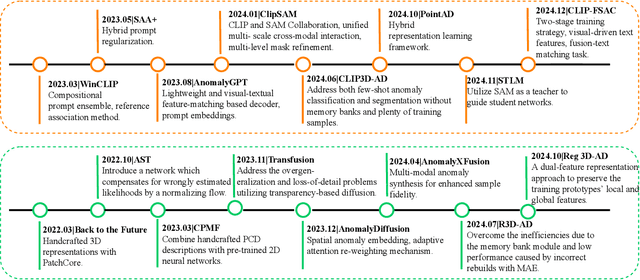
As industrial products become abundant and sophisticated, visual industrial defect detection receives much attention, including two-dimensional and three-dimensional visual feature modeling. Traditional methods use statistical analysis, abnormal data synthesis modeling, and generation-based models to separate product defect features and complete defect detection. Recently, the emergence of foundation models has brought visual and textual semantic prior knowledge. Many methods are based on foundation models (FM) to improve the accuracy of detection, but at the same time, increase model complexity and slow down inference speed. Some FM-based methods have begun to explore lightweight modeling ways, which have gradually attracted attention and deserve to be systematically analyzed. In this paper, we conduct a systematic survey with comparisons and discussions of foundation model methods from different aspects and briefly review non-foundation model (NFM) methods recently published. Furthermore, we discuss the differences between FM and NFM methods from training objectives, model structure and scale, model performance, and potential directions for future exploration. Through comparison, we find FM methods are more suitable for few-shot and zero-shot learning, which are more in line with actual industrial application scenarios and worthy of in-depth research.
IMDPrompter: Adapting SAM to Image Manipulation Detection by Cross-View Automated Prompt Learning
Feb 04, 2025Using extensive training data from SA-1B, the Segment Anything Model (SAM) has demonstrated exceptional generalization and zero-shot capabilities, attracting widespread attention in areas such as medical image segmentation and remote sensing image segmentation. However, its performance in the field of image manipulation detection remains largely unexplored and unconfirmed. There are two main challenges in applying SAM to image manipulation detection: a) reliance on manual prompts, and b) the difficulty of single-view information in supporting cross-dataset generalization. To address these challenges, we develops a cross-view prompt learning paradigm called IMDPrompter based on SAM. Benefiting from the design of automated prompts, IMDPrompter no longer relies on manual guidance, enabling automated detection and localization. Additionally, we propose components such as Cross-view Feature Perception, Optimal Prompt Selection, and Cross-View Prompt Consistency, which facilitate cross-view perceptual learning and guide SAM to generate accurate masks. Extensive experimental results from five datasets (CASIA, Columbia, Coverage, IMD2020, and NIST16) validate the effectiveness of our proposed method.
Rethinking Pseudo-Label Guided Learning for Weakly Supervised Temporal Action Localization from the Perspective of Noise Correction
Jan 19, 2025



Pseudo-label learning methods have been widely applied in weakly-supervised temporal action localization. Existing works directly utilize weakly-supervised base model to generate instance-level pseudo-labels for training the fully-supervised detection head. We argue that the noise in pseudo-labels would interfere with the learning of fully-supervised detection head, leading to significant performance leakage. Issues with noisy labels include:(1) inaccurate boundary localization; (2) undetected short action clips; (3) multiple adjacent segments incorrectly detected as one segment. To target these issues, we introduce a two-stage noisy label learning strategy to harness every potential useful signal in noisy labels. First, we propose a frame-level pseudo-label generation model with a context-aware denoising algorithm to refine the boundaries. Second, we introduce an online-revised teacher-student framework with a missing instance compensation module and an ambiguous instance correction module to solve the short-action-missing and many-to-one problems. Besides, we apply a high-quality pseudo-label mining loss in our online-revised teacher-student framework to add different weights to the noisy labels to train more effectively. Our model outperforms the previous state-of-the-art method in detection accuracy and inference speed greatly upon the THUMOS14 and ActivityNet v1.2 benchmarks.
Distributed satellite information networks: Architecture, enabling technologies, and trends
Dec 17, 2024



Driven by the vision of ubiquitous connectivity and wireless intelligence, the evolution of ultra-dense constellation-based satellite-integrated Internet is underway, now taking preliminary shape. Nevertheless, the entrenched institutional silos and limited, nonrenewable heterogeneous network resources leave current satellite systems struggling to accommodate the escalating demands of next-generation intelligent applications. In this context, the distributed satellite information networks (DSIN), exemplified by the cohesive clustered satellites system, have emerged as an innovative architecture, bridging information gaps across diverse satellite systems, such as communication, navigation, and remote sensing, and establishing a unified, open information network paradigm to support resilient space information services. This survey first provides a profound discussion about innovative network architectures of DSIN, encompassing distributed regenerative satellite network architecture, distributed satellite computing network architecture, and reconfigurable satellite formation flying, to enable flexible and scalable communication, computing and control. The DSIN faces challenges from network heterogeneity, unpredictable channel dynamics, sparse resources, and decentralized collaboration frameworks. To address these issues, a series of enabling technologies is identified, including channel modeling and estimation, cloud-native distributed MIMO cooperation, grant-free massive access, network routing, and the proper combination of all these diversity techniques. Furthermore, to heighten the overall resource efficiency, the cross-layer optimization techniques are further developed to meet upper-layer deterministic, adaptive and secure information services requirements. In addition, emerging research directions and new opportunities are highlighted on the way to achieving the DSIN vision.
V-MIND: Building Versatile Monocular Indoor 3D Detector with Diverse 2D Annotations
Dec 16, 2024The field of indoor monocular 3D object detection is gaining significant attention, fueled by the increasing demand in VR/AR and robotic applications. However, its advancement is impeded by the limited availability and diversity of 3D training data, owing to the labor-intensive nature of 3D data collection and annotation processes. In this paper, we present V-MIND (Versatile Monocular INdoor Detector), which enhances the performance of indoor 3D detectors across a diverse set of object classes by harnessing publicly available large-scale 2D datasets. By leveraging well-established monocular depth estimation techniques and camera intrinsic predictors, we can generate 3D training data by converting large-scale 2D images into 3D point clouds and subsequently deriving pseudo 3D bounding boxes. To mitigate distance errors inherent in the converted point clouds, we introduce a novel 3D self-calibration loss for refining the pseudo 3D bounding boxes during training. Additionally, we propose a novel ambiguity loss to address the ambiguity that arises when introducing new classes from 2D datasets. Finally, through joint training with existing 3D datasets and pseudo 3D bounding boxes derived from 2D datasets, V-MIND achieves state-of-the-art object detection performance across a wide range of classes on the Omni3D indoor dataset.