 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Brain Ultrasound Ablation Thermal Dose Modeling with in Vivo Experimental Validation
Sep 04, 2024



Intracorporeal needle-based therapeutic ultrasound (NBTU) is a minimally invasive option for intervening in malignant brain tumors, commonly used in thermal ablation procedures. This technique is suitable for both primary and metastatic cancers, utilizing a high-frequency alternating electric field (up to 10 MHz) to excite a piezoelectric transducer. The resulting rapid deformation of the transducer produces an acoustic wave that propagates through tissue, leading to localized high-temperature heating at the target tumor site and inducing rapid cell death. To optimize the design of NBTU transducers for thermal dose delivery during treatment, numerical modeling of the acoustic pressure field generated by the deforming piezoelectric transducer is frequently employed. The bioheat transfer process generated by the input pressure field is used to track the thermal propagation of the applicator over time. Magnetic resonance thermal imaging (MRTI) can be used to experimentally validate these models. Validation results using MRTI demonstrated the feasibility of this model, showing a consistent thermal propagation pattern. However, a thermal damage isodose map is more advantageous for evaluating therapeutic efficacy. To achieve a more accurate simulation based on the actual brain tissue environment, a new finite element method (FEM) simulation with enhanced damage evaluation capabilities was conducted. The results showed that the highest temperature and ablated volume differed between experimental and simulation results by 2.1884{\deg}C (3.71%) and 0.0631 cm$^3$ (5.74%), respectively. The lowest Pearson correlation coefficient (PCC) for peak temperature was 0.7117, and the lowest Dice coefficient for the ablated area was 0.7021, indicating a good agreement in accuracy between simulation and experiment.
Couler: Unified Machine Learning Workflow Optimization in Cloud
Mar 12, 2024Machine Learning (ML) has become ubiquitous, fueling data-driven applications across various organizations. Contrary to the traditional perception of ML in research, ML workflows can be complex, resource-intensive, and time-consuming. Expanding an ML workflow to encompass a wider range of data infrastructure and data types may lead to larger workloads and increased deployment costs. Currently, numerous workflow engines are available (with over ten being widely recognized). This variety poses a challenge for end-users in terms of mastering different engine APIs. While efforts have primarily focused on optimizing ML Operations (MLOps) for a specific workflow engine, current methods largely overlook workflow optimization across different engines. In this work, we design and implement Couler, a system designed for unified ML workflow optimization in the cloud. Our main insight lies in the ability to generate an ML workflow using natural language (NL) descriptions. We integrate Large Language Models (LLMs) into workflow generation, and provide a unified programming interface for various workflow engines. This approach alleviates the need to understand various workflow engines' APIs. Moreover, Couler enhances workflow computation efficiency by introducing automated caching at multiple stages, enabling large workflow auto-parallelization and automatic hyperparameters tuning. These enhancements minimize redundant computational costs and improve fault tolerance during deep learning workflow training. Couler is extensively deployed in real-world production scenarios at Ant Group, handling approximately 22k workflows daily, and has successfully improved the CPU/Memory utilization by more than 15% and the workflow completion rate by around 17%.
TransHER: Translating Knowledge Graph Embedding with Hyper-Ellipsoidal Restriction
Apr 27, 2022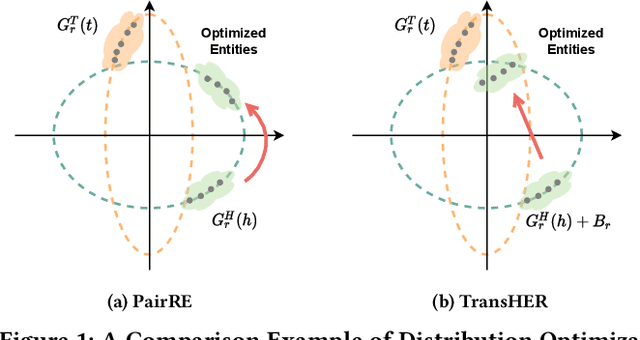
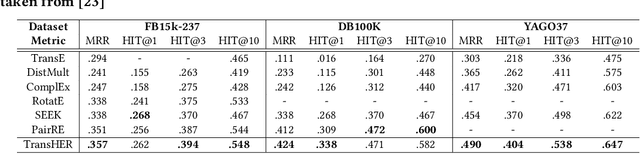
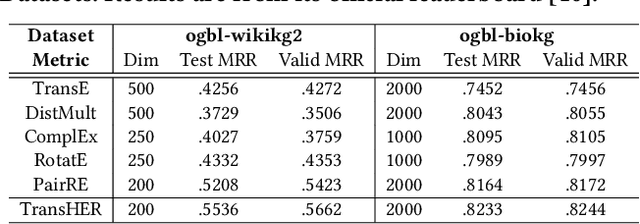

Knowledge graph embedding methods are important for knowledge graph completion (link prediction) due to their robust performance and efficiency on large-magnitude datasets. One state-of-the-art method, PairRE, leverages two separate vectors for relations to model complex relations (i.e., 1-to-N, N-to-1, and N-to-N) in knowledge graphs. However, such a method strictly restricts entities on the hyper-ellipsoid surface and thus limits the optimization of entity distribution, which largely hinders the performance of knowledge graph completion. To address this problem, we propose a novel score function TransHER, which leverages relation-specific translations between head and tail entities restricted on separate hyper-ellipsoids. Specifically, given a triplet, our model first maps entities onto two separate hyper-ellipsoids and then conducts a relation-specific translation on one of them. The relation-specific translation provides TransHER with more direct guidance in optimization and the ability to learn semantic characteristics of entities with complex relations. Experimental results show that TransHER can achieve state-of-the-art performance and generalize to datasets in different domains and scales. All our code will be publicly available.
BS-NAS: Broadening-and-Shrinking One-Shot NAS with Searchable Numbers of Channels
Mar 22, 2020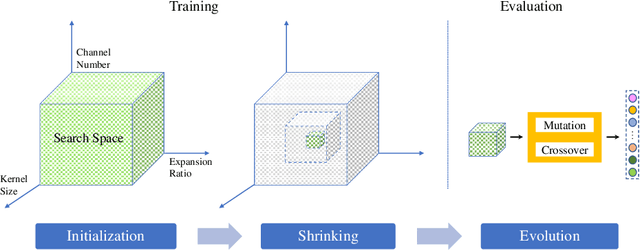

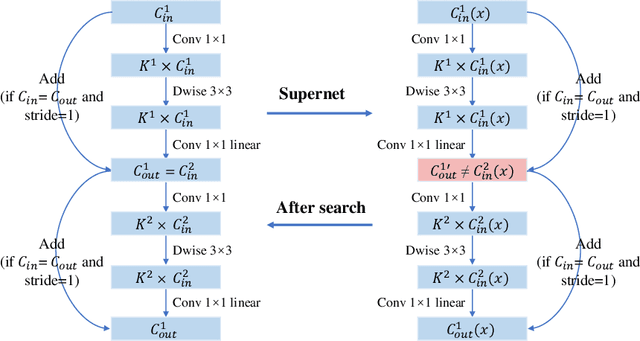
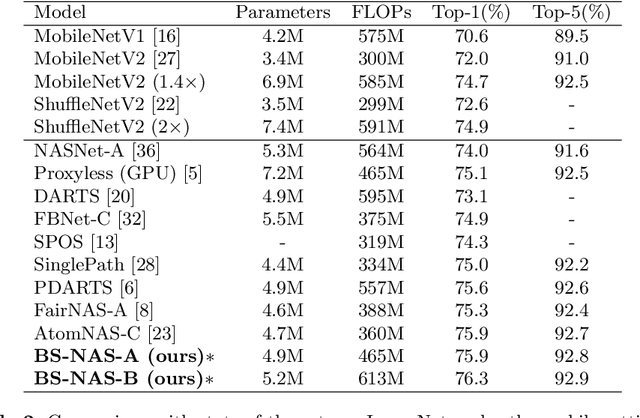
One-Shot methods have evolved into one of the most popular methods in Neural Architecture Search (NAS) due to weight sharing and single training of a supernet. However, existing methods generally suffer from two issues: predetermined number of channels in each layer which is suboptimal; and model averaging effects and poor ranking correlation caused by weight coupling and continuously expanding search space. To explicitly address these issues, in this paper, a Broadening-and-Shrinking One-Shot NAS (BS-NAS) framework is proposed, in which `broadening' refers to broadening the search space with a spring block enabling search for numbers of channels during training of the supernet; while `shrinking' refers to a novel shrinking strategy gradually turning off those underperforming operations. The above innovations broaden the search space for wider representation and then shrink it by gradually removing underperforming operations, followed by an evolutionary algorithm to efficiently search for the optimal architecture. Extensive experiments on ImageNet illustrate the effectiveness of the proposed BS-NAS as well as the state-of-the-art performance.