 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAUCUS: Knowledge Augmented User Simulators for Training Language Model Assistants
Jan 29, 2024An effective multi-turn instruction-following assistant can be developed by creating a simulator that can generate useful interaction data. Apart from relying on its intrinsic weights, an ideal user simulator should also be able to bootstrap external knowledge rapidly in its raw form to simulate the multifarious diversity of text available over the internet. Previous user simulators generally lacked diversity, were mostly closed domain, and necessitated rigid schema making them inefficient to rapidly scale to incorporate external knowledge. In this regard, we introduce, Kaucus, a Knowledge-Augmented User Simulator framework, to outline a process of creating diverse user simulators, that can seamlessly exploit external knowledge as well as benefit downstream assistant model training. Through two GPT-J based simulators viz., a Retrieval Augmented Simulator and a Summary Controlled Simulator we generate diverse simulator-assistant interactions. Through reward and preference model-based evaluations, we find that these interactions serve as useful training data and create more helpful downstream assistants. We also find that incorporating knowledge through retrieval augmentation or summary control helps create better assistants.
An Interactive Query Generation Assistant using LLM-based Prompt Modification and User Feedback
Nov 19, 2023
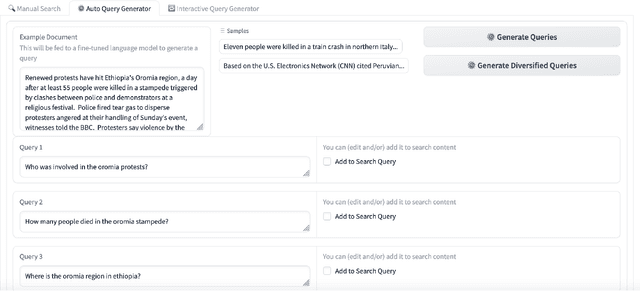
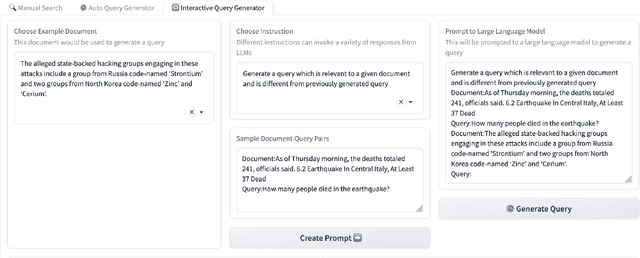
While search is the predominant method of accessing information, formulating effective queries remains a challenging task, especially for situations where the users are not familiar with a domain, or searching for documents in other languages, or looking for complex information such as events, which are not easily expressible as queries. Providing example documents or passages of interest, might be easier for a user, however, such query-by-example scenarios are prone to concept drift, and are highly sensitive to the query generation method. This demo illustrates complementary approaches of using LLMs interactively, assisting and enabling the user to provide edits and feedback at all stages of the query formulation process. The proposed Query Generation Assistant is a novel search interface which supports automatic and interactive query generation over a mono-linguial or multi-lingual document collection. Specifically, the proposed assistive interface enables the users to refine the queries generated by different LLMs, to provide feedback on the retrieved documents or passages, and is able to incorporate the users' feedback as prompts to generate more effective queries. The proposed interface is a valuable experimental tool for exploring fine-tuning and prompting of LLMs for query generation to qualitatively evaluate the effectiveness of retrieval and ranking models, and for conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries without such assistance.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
A Bird's-Eye Tutorial of Graph Attention Architectures
Jun 06, 2022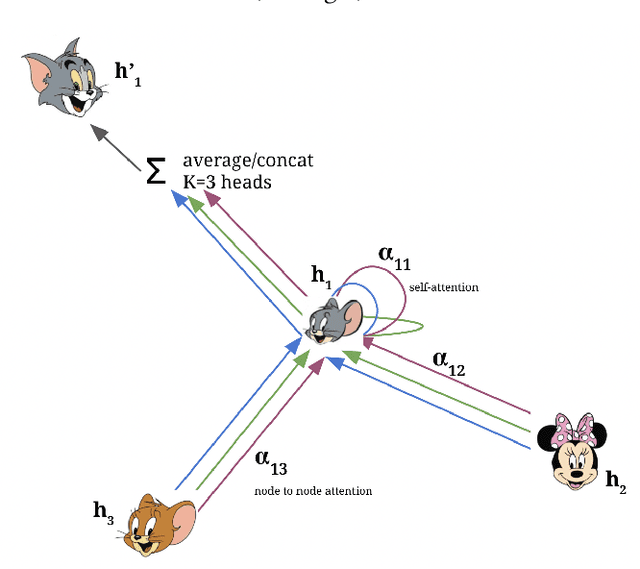
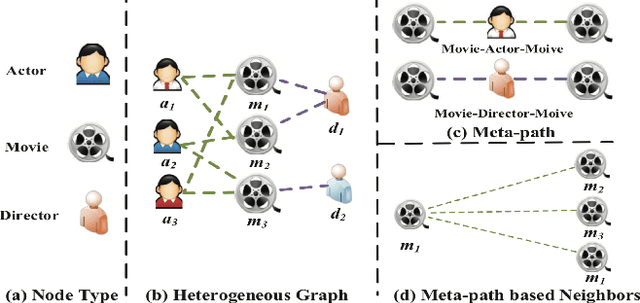
Graph Neural Networks (GNNs) have shown tremendous strides in performance for graph-structured problems especially in the domains of natural language processing, computer vision and recommender systems. Inspired by the success of the transformer architecture, there has been an ever-growing body of work on attention variants of GNNs attempting to advance the state of the art in many of these problems. Incorporating "attention" into graph mining has been viewed as a way to overcome the noisiness, heterogenity and complexity associated with graph-structured data as well as to encode soft-inductive bias. It is hence crucial and advantageous to study these variants from a bird's-eye view to assess their strengths and weaknesses. We provide a systematic and focused tutorial centered around attention based GNNs in a hope to benefit researchers dealing with graph-structured problems. Our tutorial looks at GNN variants from the point of view of the attention function and iteratively builds the reader's understanding of different graph attention variants.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
CANDLE: Decomposing Conditional and Conjunctive Queries for Task-Oriented Dialogue Systems
Jul 08, 2021
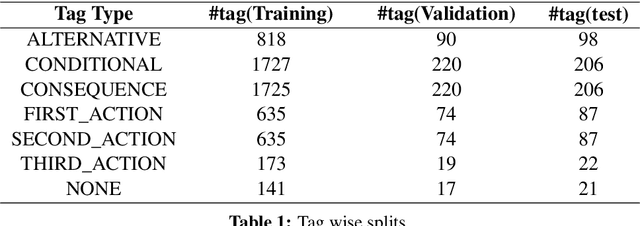


Domain-specific dialogue systems generally determine user intents by relying on sentence-level classifiers which mainly focus on single action sentences. Such classifiers are not designed to effectively handle complex queries composed of conditional and sequential clauses that represent multiple actions. We attempt to decompose such queries into smaller single-action sub-queries that are reasonable for intent classifiers to understand in a dialogue pipeline. We release CANDLE (Conditional & AND type Expressions), a dataset consisting of 3124 utterances manually tagged with conditional and sequential labels and demonstrates this decomposition by training two baseline taggers.
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
Jun 16, 2021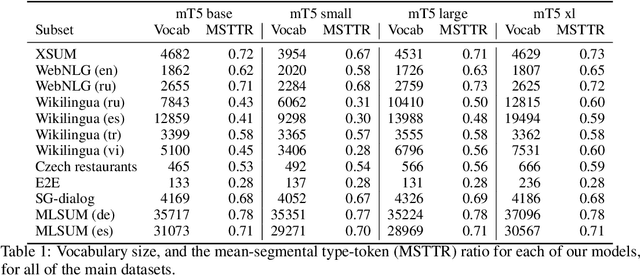
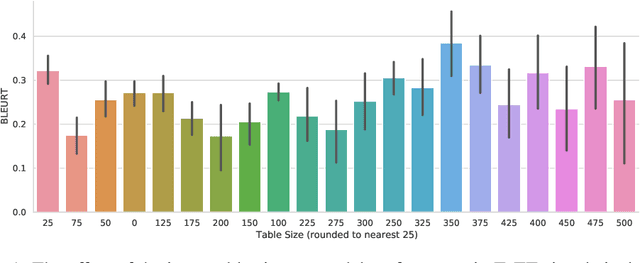
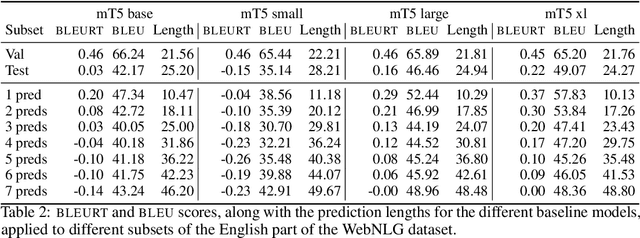
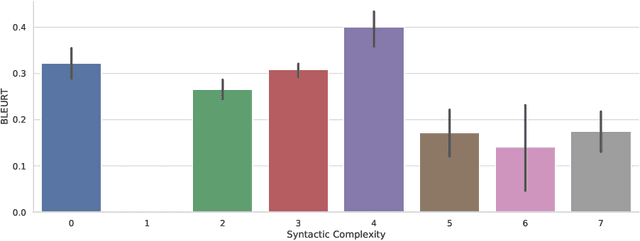
Machine learning approaches applied to NLP are often evaluated by summarizing their performance in a single number, for example accuracy. Since most test sets are constructed as an i.i.d. sample from the overall data, this approach overly simplifies the complexity of language and encourages overfitting to the head of the data distribution. As such, rare language phenomena or text about underrepresented groups are not equally included in the evaluation. To encourage more in-depth model analyses, researchers have proposed the use of multiple test sets, also called challenge sets, that assess specific capabilities of a model. In this paper, we develop a framework based on this idea which is able to generate controlled perturbations and identify subsets in text-to-scalar, text-to-text, or data-to-text settings. By applying this framework to the GEM generation benchmark, we propose an evaluation suite made of 80 challenge sets, demonstrate the kinds of analyses that it enables and shed light onto the limits of current generation models.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Resolving Intent Ambiguities by Retrieving Discriminative Clarifying Questions
Aug 17, 2020
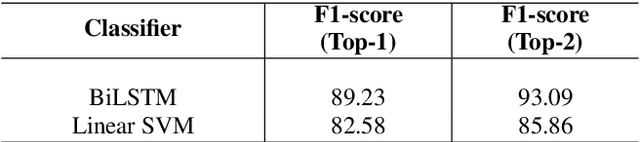
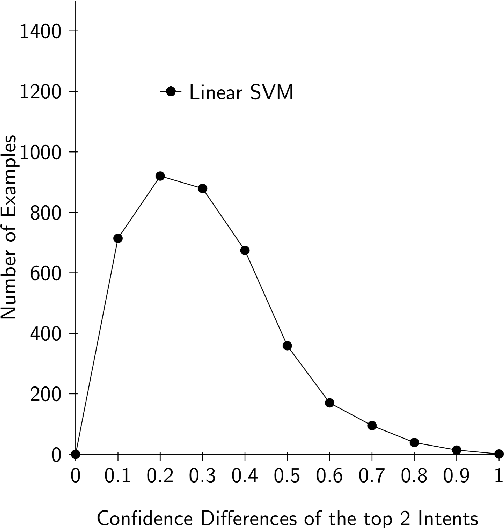
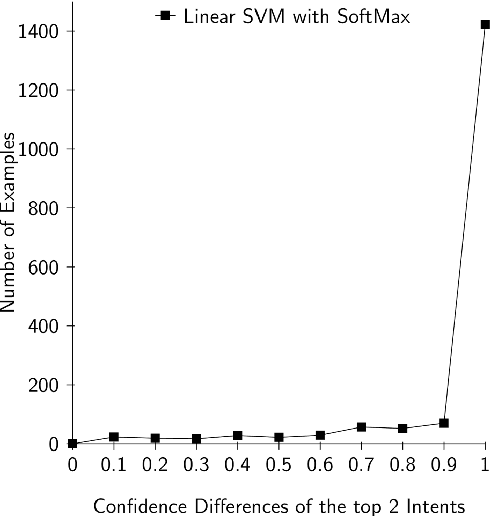
Task oriented Dialogue Systems generally employ intent detection systems in order to map user queries to a set of pre-defined intents. However, user queries appearing in natural language can be easily ambiguous and hence such a direct mapping might not be straightforward harming intent detection and eventually the overall performance of a dialogue system. Moreover, acquiring domain-specific clarification questions is costly. In order to disambiguate queries which are ambiguous between two intents, we propose a novel method of generating discriminative questions using a simple rule based system which can take advantage of any question generation system without requiring annotated data of clarification questions. Our approach aims at discrimination between two intents but can be easily extended to clarification over multiple intents. Seeking clarification from the user to classify user intents not only helps understand the user intent effectively, but also reduces the roboticity of the conversation and makes the interaction considerably natural.