 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling the performance of delivery vehicles across urban micro-regions to accelerate the transition to cargo-bike logistics
Jan 30, 2023
Light goods vehicles (LGV) used extensively in the last mile of delivery are one of the leading polluters in cities. Cargo-bike logistics has been put forward as a high impact candidate for replacing LGVs, with experts estimating over half of urban van deliveries being replaceable by cargo bikes, due to their faster speeds, shorter parking times and more efficient routes across cities. By modelling the relative delivery performance of different vehicle types across urban micro-regions, machine learning can help operators evaluate the business and environmental impact of adding cargo-bikes to their fleets. In this paper, we introduce two datasets, and present initial progress in modelling urban delivery service time (e.g. cruising for parking, unloading, walking). Using Uber's H3 index to divide the cities into hexagonal cells, and aggregating OpenStreetMap tags for each cell, we show that urban context is a critical predictor of delivery performance.
Multimodal Video Adapter for Parameter Efficient Video Text Retrieval
Jan 19, 2023



State-of-the-art video-text retrieval (VTR) methods usually fully fine-tune the pre-trained model (e.g. CLIP) on specific datasets, which may suffer from substantial storage costs in practical applications since a separate model per task needs to be stored. To overcome this issue, we present the premier work on performing parameter-efficient VTR from the pre-trained model, i.e., only a small number of parameters are tunable while freezing the backbone. Towards this goal, we propose a new method dubbed Multimodal Video Adapter (MV-Adapter) for efficiently transferring the knowledge in the pre-trained CLIP from image-text to video-text. Specifically, MV-Adapter adopts bottleneck structures in both video and text branches and introduces two novel components. The first is a Temporal Adaptation Module employed in the video branch to inject global and local temporal contexts. We also learn weights calibrations to adapt to the dynamic variations across frames. The second is a Cross-Modal Interaction Module that generates weights for video/text branches through a shared parameter space, for better aligning between modalities. Thanks to above innovations, MV-Adapter can achieve on-par or better performance than standard fine-tuning with negligible parameters overhead. Notably, on five widely used VTR benchmarks (MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet), MV-Adapter consistently outperforms various competing methods in V2T/T2V tasks with large margins. Codes will be released.
Edge Preserving Implicit Surface Representation of Point Clouds
Jan 12, 2023Learning implicit surface directly from raw data recently has become a very attractive representation method for 3D reconstruction tasks due to its excellent performance. However, as the raw data quality deteriorates, the implicit functions often lead to unsatisfactory reconstruction results. To this end, we propose a novel edge-preserving implicit surface reconstruction method, which mainly consists of a differentiable Laplican regularizer and a dynamic edge sampling strategy. Among them, the differential Laplican regularizer can effectively alleviate the implicit surface unsmoothness caused by the point cloud quality deteriorates; Meanwhile, in order to reduce the excessive smoothing at the edge regions of implicit suface, we proposed a dynamic edge extract strategy for sampling near the sharp edge of point cloud, which can effectively avoid the Laplacian regularizer from smoothing all regions. Finally, we combine them with a simple regularization term for robust implicit surface reconstruction. Compared with the state-of-the-art methods, experimental results show that our method significantly improves the quality of 3D reconstruction results. Moreover, we demonstrate through several experiments that our method can be conveniently and effectively applied to some point cloud analysis tasks, including point cloud edge feature extraction, normal estimation,etc.
Learning Physically Realizable Skills for Online Packing of General 3D Shapes
Dec 05, 2022



We study the problem of learning online packing skills for irregular 3D shapes, which is arguably the most challenging setting of bin packing problems. The goal is to consecutively move a sequence of 3D objects with arbitrary shapes into a designated container with only partial observations of the object sequence. Meanwhile, we take physical realizability into account, involving physics dynamics and constraints of a placement. The packing policy should understand the 3D geometry of the object to be packed and make effective decisions to accommodate it in the container in a physically realizable way. We propose a Reinforcement Learning (RL) pipeline to learn the policy. The complex irregular geometry and imperfect object placement together lead to huge solution space. Direct training in such space is prohibitively data intensive. We instead propose a theoretically-provable method for candidate action generation to reduce the action space of RL and the learning burden. A parameterized policy is then learned to select the best placement from the candidates. Equipped with an efficient method of asynchronous RL acceleration and a data preparation process of simulation-ready training sequences, a mature packing policy can be trained in a physics-based environment within 48 hours. Through extensive evaluation on a variety of real-life shape datasets and comparisons with state-of-the-art baselines, we demonstrate that our method outperforms the best-performing baseline on all datasets by at least 12.8% in terms of packing utility.
Multi-resolution Monocular Depth Map Fusion by Self-supervised Gradient-based Composition
Dec 03, 2022



Monocular depth estimation is a challenging problem on which deep neural networks have demonstrated great potential. However, depth maps predicted by existing deep models usually lack fine-grained details due to the convolution operations and the down-samplings in networks. We find that increasing input resolution is helpful to preserve more local details while the estimation at low resolution is more accurate globally. Therefore, we propose a novel depth map fusion module to combine the advantages of estimations with multi-resolution inputs. Instead of merging the low- and high-resolution estimations equally, we adopt the core idea of Poisson fusion, trying to implant the gradient domain of high-resolution depth into the low-resolution depth. While classic Poisson fusion requires a fusion mask as supervision, we propose a self-supervised framework based on guided image filtering. We demonstrate that this gradient-based composition performs much better at noisy immunity, compared with the state-of-the-art depth map fusion method. Our lightweight depth fusion is one-shot and runs in real-time, making our method 80X faster than a state-of-the-art depth fusion method. Quantitative evaluations demonstrate that the proposed method can be integrated into many fully convolutional monocular depth estimation backbones with a significant performance boost, leading to state-of-the-art results of detail enhancement on depth maps.
3D-Aware Object Goal Navigation via Simultaneous Exploration and Identification
Dec 01, 2022



Object goal navigation (ObjectNav) in unseen environments is a fundamental task for Embodied AI. Agents in existing works learn ObjectNav policies based on 2D maps, scene graphs, or image sequences. Considering this task happens in 3D space, a 3D-aware agent can advance its ObjectNav capability via learning from fine-grained spatial information. However, leveraging 3D scene representation can be prohibitively unpractical for policy learning in this floor-level task, due to low sample efficiency and expensive computational cost. In this work, we propose a framework for the challenging 3D-aware ObjectNav based on two straightforward sub-policies. The two sub-polices, namely corner-guided exploration policy and category-aware identification policy, simultaneously perform by utilizing online fused 3D points as observation. Through extensive experiments, we show that this framework can dramatically improve the performance in ObjectNav through learning from 3D scene representation. Our framework achieves the best performance among all modular-based methods on the Matterport3D and Gibson datasets, while requiring (up to 30x) less computational cost for training.
6DOF Pose Estimation of a 3D Rigid Object based on Edge-enhanced Point Pair Features
Sep 17, 2022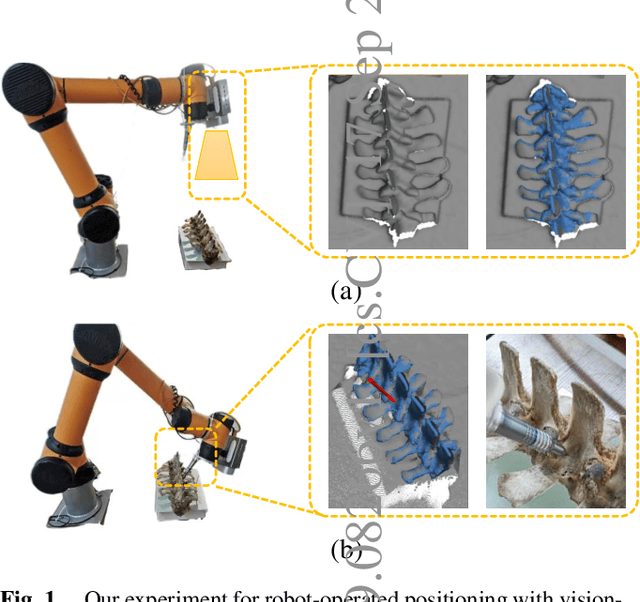
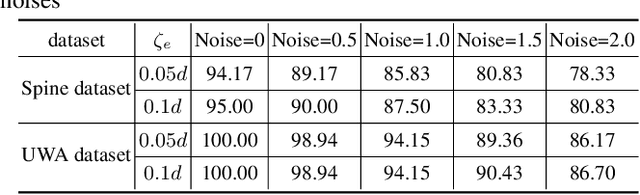
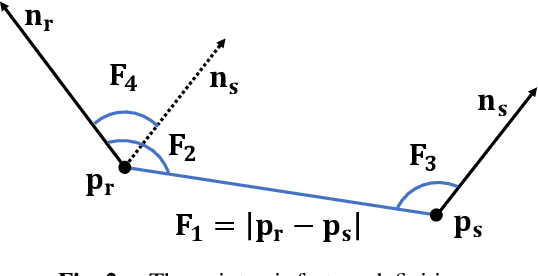
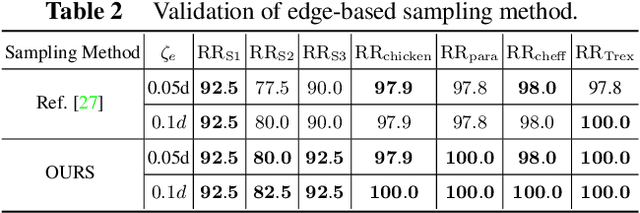
The point pair feature (PPF) is widely used for 6D pose estimation. In this paper, we propose an efficient 6D pose estimation method based on the PPF framework. We introduce a well-targeted down-sampling strategy that focuses more on edge area for efficient feature extraction of complex geometry. A pose hypothesis validation approach is proposed to resolve the symmetric ambiguity by calculating edge matching degree. We perform evaluations on two challenging datasets and one real-world collected dataset, demonstrating the superiority of our method on pose estimation of geometrically complex, occluded, symmetrical objects. We further validate our method by applying it to simulated punctures.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022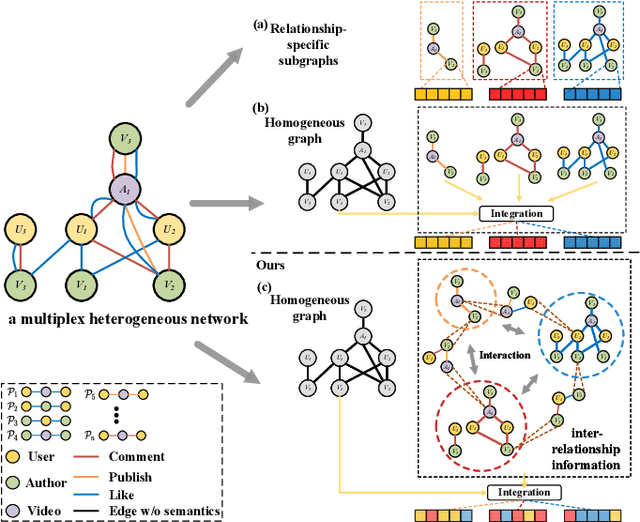
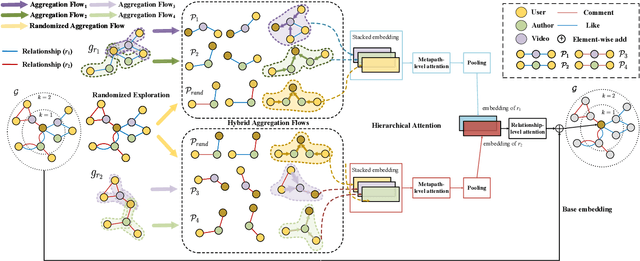
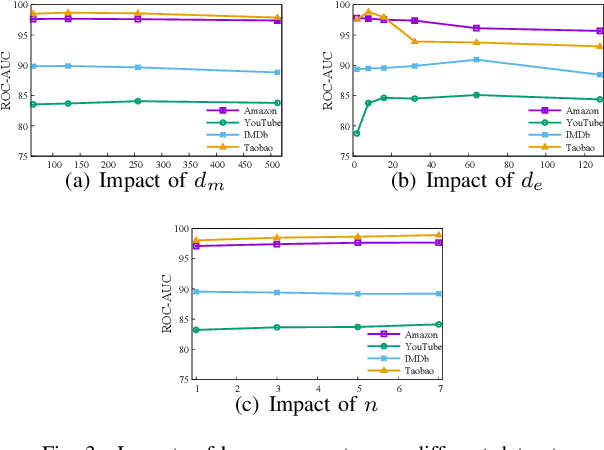
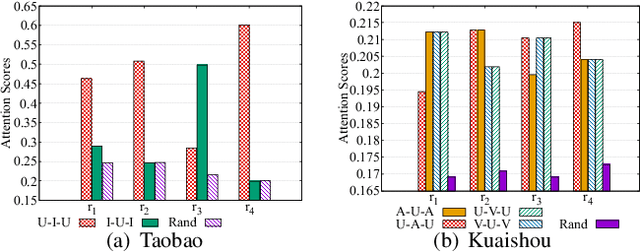
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022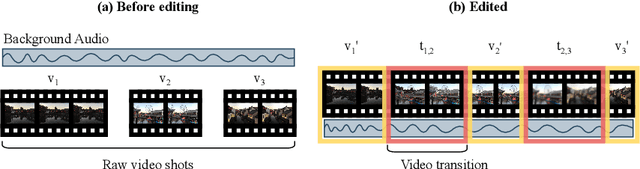
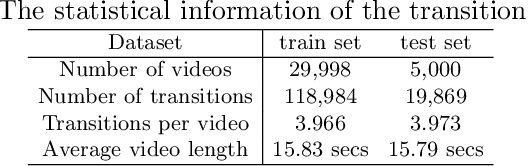
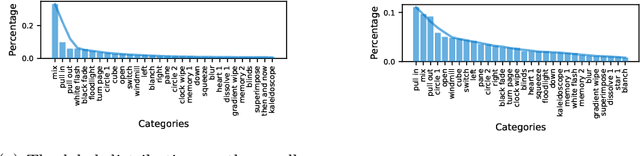
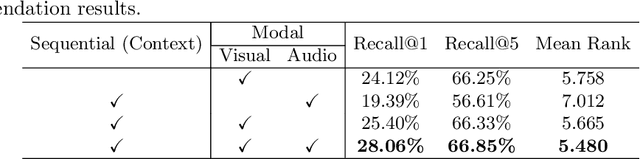
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.
Repairing Systematic Outliers by Learning Clean Subspaces in VAEs
Jul 17, 2022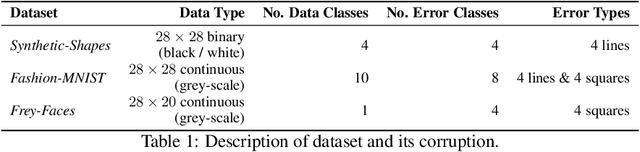
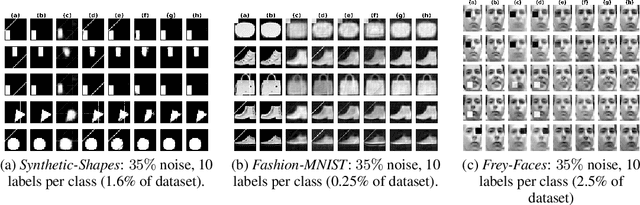
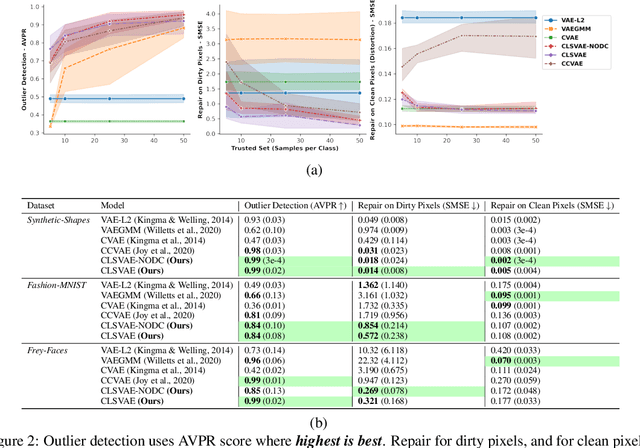

Data cleaning often comprises outlier detection and data repair. Systematic errors result from nearly deterministic transformations that occur repeatedly in the data, e.g. specific image pixels being set to default values or watermarks. Consequently, models with enough capacity easily overfit to these errors, making detection and repair difficult. Seeing as a systematic outlier is a combination of patterns of a clean instance and systematic error patterns, our main insight is that inliers can be modelled by a smaller representation (subspace) in a model than outliers. By exploiting this, we propose Clean Subspace Variational Autoencoder (CLSVAE), a novel semi-supervised model for detection and automated repair of systematic errors. The main idea is to partition the latent space and model inlier and outlier patterns separately. CLSVAE is effective with much less labelled data compared to previous related models, often with less than 2% of the data. We provide experiments using three image datasets in scenarios with different levels of corruption and labelled set sizes, comparing to relevant baselines. CLSVAE provides superior repairs without human intervention, e.g. with just 0.25% of labelled data we see a relative error decrease of 58% compared to the closest baseline.