 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning of Motion Representation for Video Understanding
Apr 02, 2018
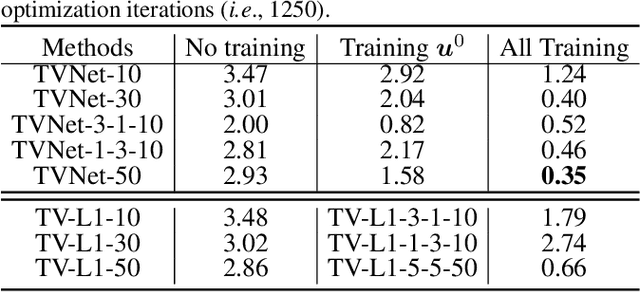
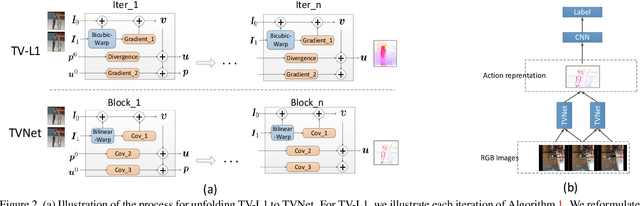
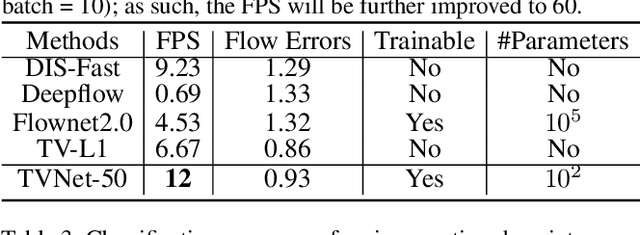
Despite the recent success of end-to-end learned representations, hand-crafted optical flow features are still widely used in video analysis tasks. To fill this gap, we propose TVNet, a novel end-to-end trainable neural network, to learn optical-flow-like features from data. TVNet subsumes a specific optical flow solver, the TV-L1 method, and is initialized by unfolding its optimization iterations as neural layers. TVNet can therefore be used directly without any extra learning. Moreover, it can be naturally concatenated with other task-specific networks to formulate an end-to-end architecture, thus making our method more efficient than current multi-stage approaches by avoiding the need to pre-compute and store features on disk. Finally, the parameters of the TVNet can be further fine-tuned by end-to-end training. This enables TVNet to learn richer and task-specific patterns beyond exact optical flow. Extensive experiments on two action recognition benchmarks verify the effectiveness of the proposed approach. Our TVNet achieves better accuracies than all compared methods, while being competitive with the fastest counterpart in terms of features extraction time.
Robust Actor-Critic Contextual Bandit for Mobile Health (mHealth) Interventions
Feb 27, 2018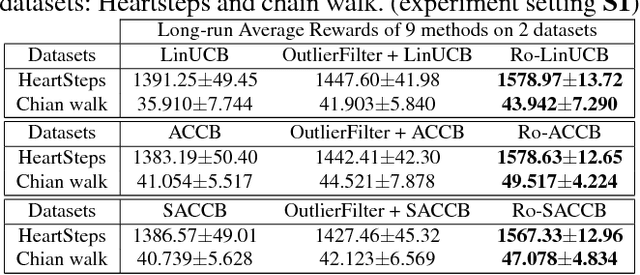
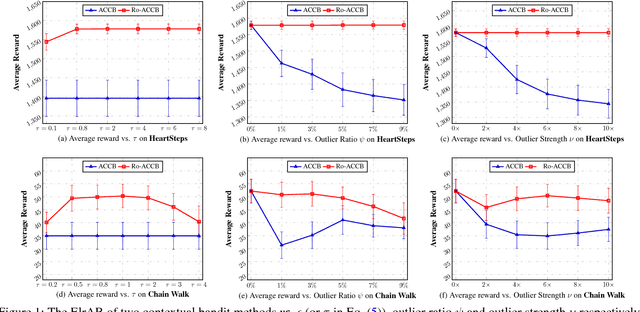
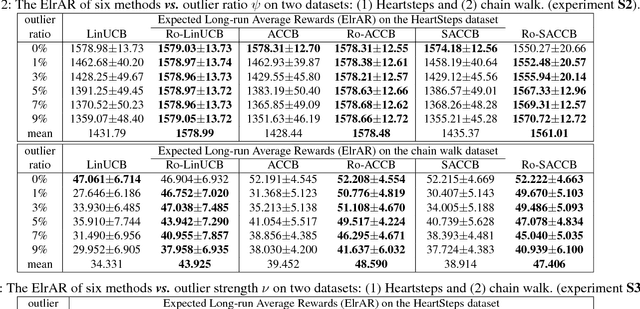
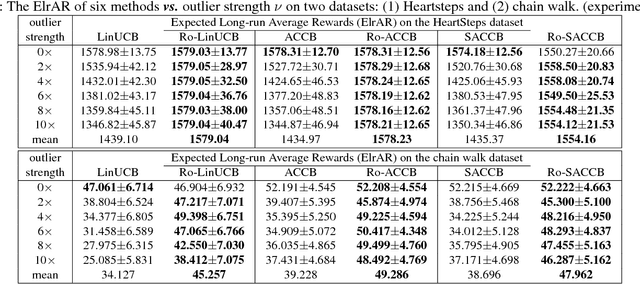
We consider the actor-critic contextual bandit for the mobile health (mHealth) intervention. State-of-the-art decision-making algorithms generally ignore the outliers in the dataset. In this paper, we propose a novel robust contextual bandit method for the mHealth. It can achieve the conflicting goal of reducing the influence of outliers while seeking for a similar solution compared with the state-of-the-art contextual bandit methods on the datasets without outliers. Such performance relies on two technologies: (1) the capped-$\ell_{2}$ norm; (2) a reliable method to set the thresholding hyper-parameter, which is inspired by one of the most fundamental techniques in the statistics. Although the model is non-convex and non-differentiable, we propose an effective reweighted algorithm and provide solid theoretical analyses. We prove that the proposed algorithm can find sufficiently decreasing points after each iteration and finally converges after a finite number of iterations. Extensive experiment results on two datasets demonstrate that our method can achieve almost identical results compared with state-of-the-art contextual bandit methods on the dataset without outliers, and significantly outperform those state-of-the-art methods on the badly noised dataset with outliers in a variety of parameter settings.
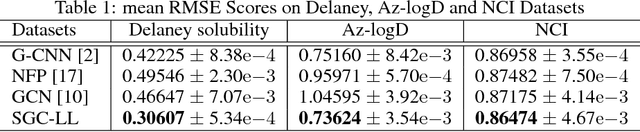
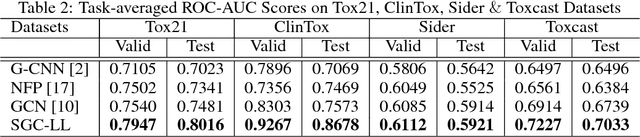
Adaptive Graph Convolutional Neural Networks
Jan 10, 2018

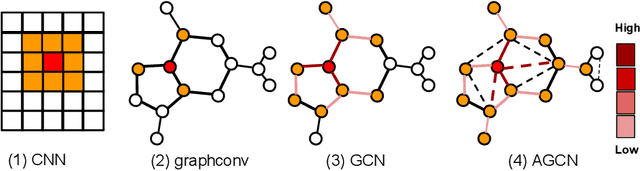

Graph Convolutional Neural Networks (Graph CNNs) are generalizations of classical CNNs to handle graph data such as molecular data, point could and social networks. Current filters in graph CNNs are built for fixed and shared graph structure. However, for most real data, the graph structures varies in both size and connectivity. The paper proposes a generalized and flexible graph CNN taking data of arbitrary graph structure as input. In that way a task-driven adaptive graph is learned for each graph data while training. To efficiently learn the graph, a distance metric learning is proposed. Extensive experiments on nine graph-structured datasets have demonstrated the superior performance improvement on both convergence speed and predictive accuracy.
Cohesion-based Online Actor-Critic Reinforcement Learning for mHealth Intervention
Aug 23, 2017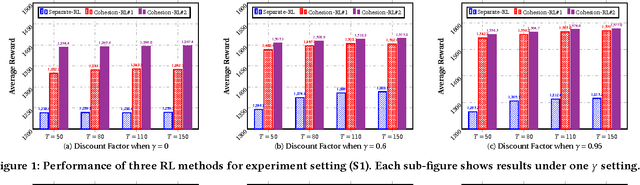
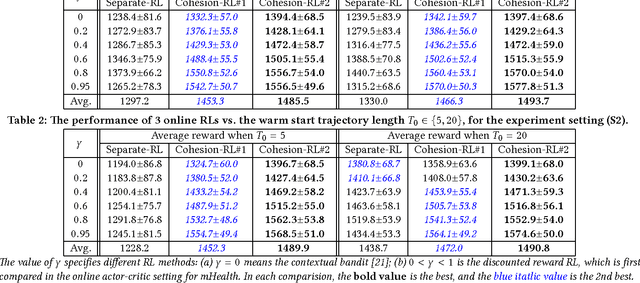
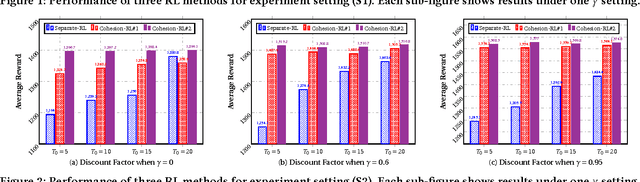
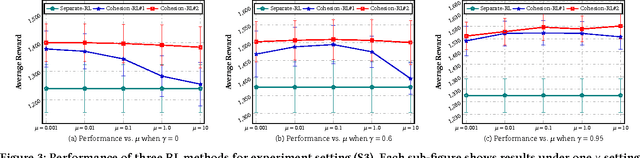
In the wake of the vast population of smart device users worldwide, mobile health (mHealth) technologies are hopeful to generate positive and wide influence on people's health. They are able to provide flexible, affordable and portable health guides to device users. Current online decision-making methods for mHealth assume that the users are completely heterogeneous. They share no information among users and learn a separate policy for each user. However, data for each user is very limited in size to support the separate online learning, leading to unstable policies that contain lots of variances. Besides, we find the truth that a user may be similar with some, but not all, users, and connected users tend to have similar behaviors. In this paper, we propose a network cohesion constrained (actor-critic) Reinforcement Learning (RL) method for mHealth. The goal is to explore how to share information among similar users to better convert the limited user information into sharper learned policies. To the best of our knowledge, this is the first online actor-critic RL for mHealth and first network cohesion constrained (actor-critic) RL method in all applications. The network cohesion is important to derive effective policies. We come up with a novel method to learn the network by using the warm start trajectory, which directly reflects the users' property. The optimization of our model is difficult and very different from the general supervised learning due to the indirect observation of values. As a contribution, we propose two algorithms for the proposed online RLs. Apart from mHealth, the proposed methods can be easily applied or adapted to other health-related tasks. Extensive experiment results on the HeartSteps dataset demonstrates that in a variety of parameter settings, the proposed two methods obtain obvious improvements over the state-of-the-art methods.
Robust Contextual Bandit via the Capped-$\ell_{2}$ norm
Aug 17, 2017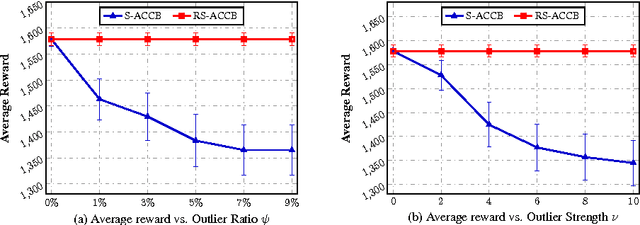
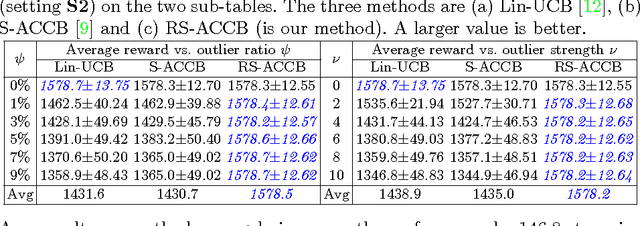
This paper considers the actor-critic contextual bandit for the mobile health (mHealth) intervention. The state-of-the-art decision-making methods in mHealth generally assume that the noise in the dynamic system follows the Gaussian distribution. Those methods use the least-square-based algorithm to estimate the expected reward, which is prone to the existence of outliers. To deal with the issue of outliers, we propose a novel robust actor-critic contextual bandit method for the mHealth intervention. In the critic updating, the capped-$\ell_{2}$ norm is used to measure the approximation error, which prevents outliers from dominating our objective. A set of weights could be achieved from the critic updating. Considering them gives a weighted objective for the actor updating. It provides the badly noised sample in the critic updating with zero weights for the actor updating. As a result, the robustness of both actor-critic updating is enhanced. There is a key parameter in the capped-$\ell_{2}$ norm. We provide a reliable method to properly set it by making use of one of the most fundamental definitions of outliers in statistics. Extensive experiment results demonstrate that our method can achieve almost identical results compared with the state-of-the-art methods on the dataset without outliers and dramatically outperform them on the datasets noised by outliers.
Group-driven Reinforcement Learning for Personalized mHealth Intervention
Aug 14, 2017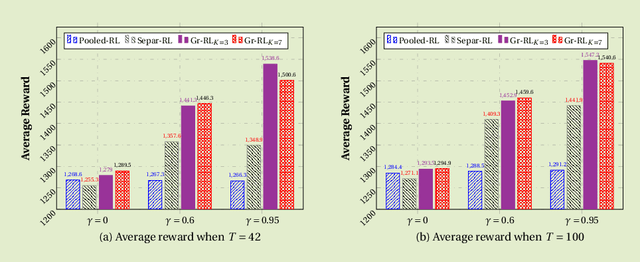
Due to the popularity of smartphones and wearable devices nowadays, mobile health (mHealth) technologies are promising to bring positive and wide impacts on people's health. State-of-the-art decision-making methods for mHealth rely on some ideal assumptions. Those methods either assume that the users are completely homogenous or completely heterogeneous. However, in reality, a user might be similar with some, but not all, users. In this paper, we propose a novel group-driven reinforcement learning method for the mHealth. We aim to understand how to share information among similar users to better convert the limited user information into sharper learned RL policies. Specifically, we employ the K-means clustering method to group users based on their trajectory information similarity and learn a shared RL policy for each group. Extensive experiment results have shown that our method can achieve clear gains over the state-of-the-art RL methods for mHealth.
Learning Graph While Training: An Evolving Graph Convolutional Neural Network
Aug 10, 2017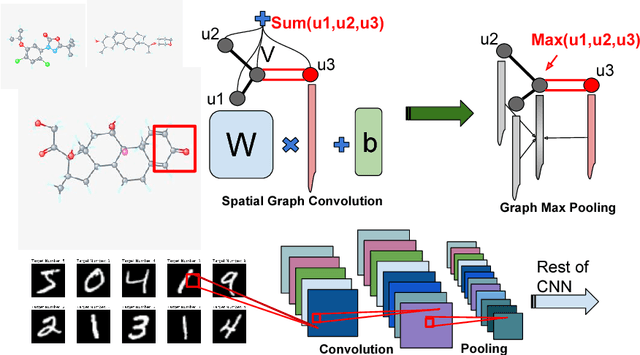
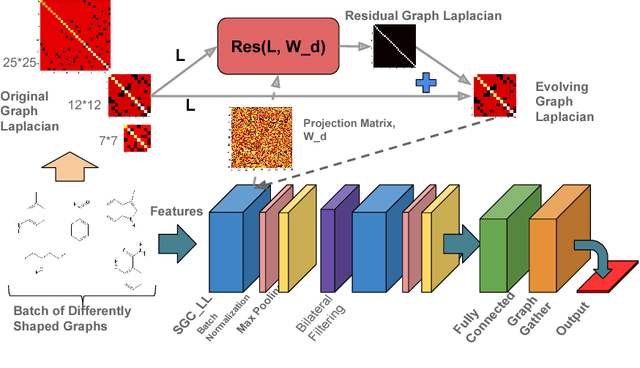
Convolution Neural Networks on Graphs are important generalization and extension of classical CNNs. While previous works generally assumed that the graph structures of samples are regular with unified dimensions, in many applications, they are highly diverse or even not well defined. Under some circumstances, e.g. chemical molecular data, clustering or coarsening for simplifying the graphs is hard to be justified chemically. In this paper, we propose a more general and flexible graph convolution network (EGCN) fed by batch of arbitrarily shaped data together with their evolving graph Laplacians trained in supervised fashion. Extensive experiments have been conducted to demonstrate the superior performance in terms of both the acceleration of parameter fitting and the significantly improved prediction accuracy on multiple graph-structured datasets.
Track Facial Points in Unconstrained Videos
Sep 09, 2016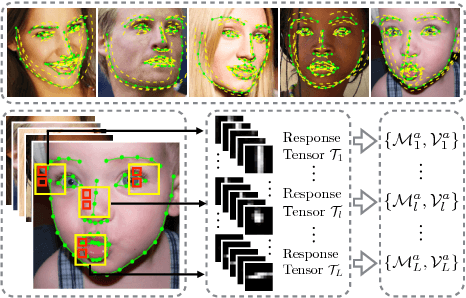

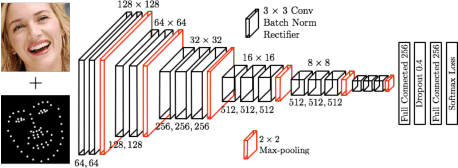
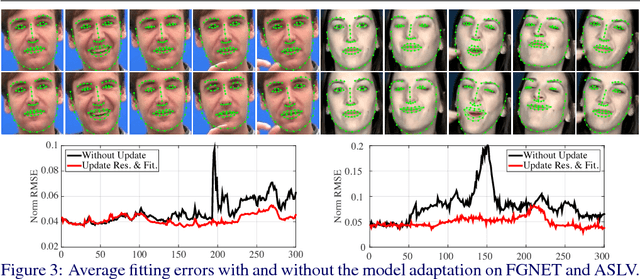
Tracking Facial Points in unconstrained videos is challenging due to the non-rigid deformation that changes over time. In this paper, we propose to exploit incremental learning for person-specific alignment in wild conditions. Our approach takes advantage of part-based representation and cascade regression for robust and efficient alignment on each frame. Unlike existing methods that usually rely on models trained offline, we incrementally update the representation subspace and the cascade of regressors in a unified framework to achieve personalized modeling on the fly. To alleviate the drifting issue, the fitting results are evaluated using a deep neural network, where well-aligned faces are picked out to incrementally update the representation and fitting models. Both image and video datasets are employed to valid the proposed method. The results demonstrate the superior performance of our approach compared with existing approaches in terms of fitting accuracy and efficiency.
Fast Iteratively Reweighted Least Squares Algorithms for Analysis-Based Sparsity Reconstruction
Apr 28, 2015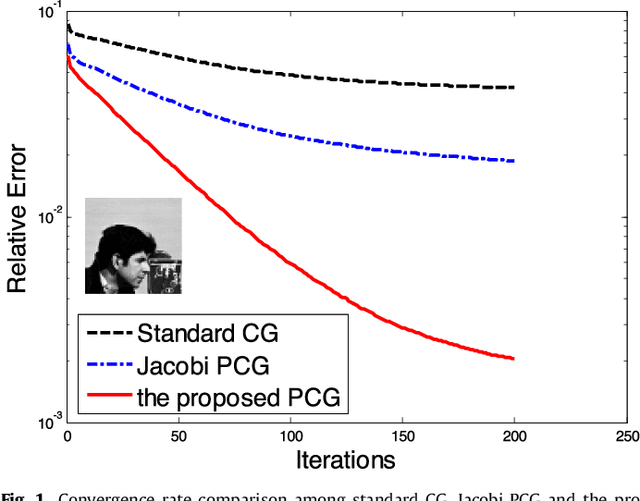


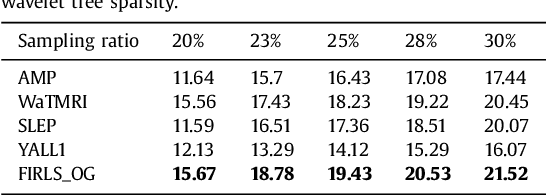
In this paper, we propose a novel algorithm for analysis-based sparsity reconstruction. It can solve the generalized problem by structured sparsity regularization with an orthogonal basis and total variation regularization. The proposed algorithm is based on the iterative reweighted least squares (IRLS) model, which is further accelerated by the preconditioned conjugate gradient method. The convergence rate of the proposed algorithm is almost the same as that of the traditional IRLS algorithms, that is, exponentially fast. Moreover, with the specifically devised preconditioner, the computational cost for each iteration is significantly less than that of traditional IRLS algorithms, which enables our approach to handle large scale problems. In addition to the fast convergence, it is straightforward to apply our method to standard sparsity, group sparsity, overlapping group sparsity and TV based problems. Experiments are conducted on a practical application: compressive sensing magnetic resonance imaging. Extensive results demonstrate that the proposed algorithm achieves superior performance over 14 state-of-the-art algorithms in terms of both accuracy and computational cost.
SIRF: Simultaneous Image Registration and Fusion in A Unified Framework
Jan 01, 2015


In this paper, we propose a novel method for image fusion with a high-resolution panchromatic image and a low-resolution multispectral image at the same geographical location. The fusion is formulated as a convex optimization problem which minimizes a linear combination of a least-squares fitting term and a dynamic gradient sparsity regularizer. The former is to preserve accurate spectral information of the multispectral image, while the latter is to keep sharp edges of the high-resolution panchromatic image. We further propose to simultaneously register the two images during the fusing process, which is naturally achieved by virtue of the dynamic gradient sparsity property. An efficient algorithm is then devised to solve the optimization problem, accomplishing a linear computational complexity in the size of the output image in each iteration. We compare our method against seven state-of-the-art image fusion methods on multispectral image datasets from four satellites. Extensive experimental results demonstrate that the proposed method substantially outperforms the others in terms of both spatial and spectral qualities. We also show that our method can provide high-quality products from coarsely registered real-world datasets. Finally, a MATLAB implementation is provided to facilitate future research.