 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization
Paper and Code
Jun 21, 2018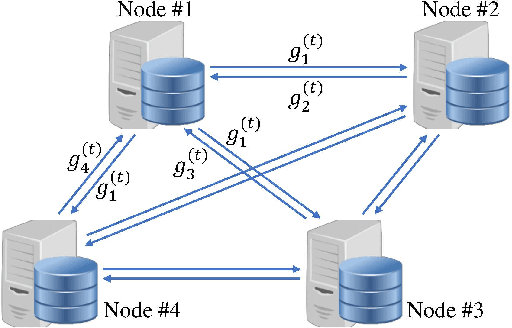
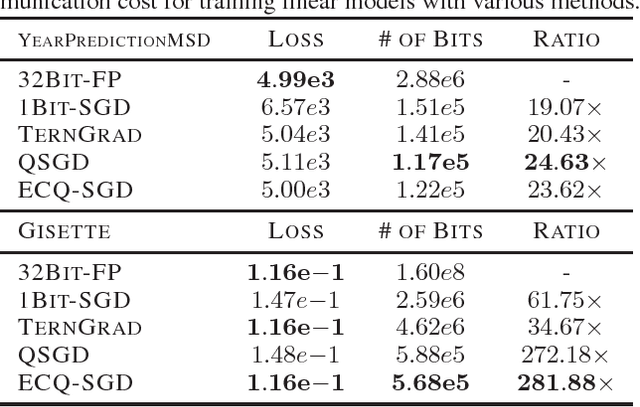
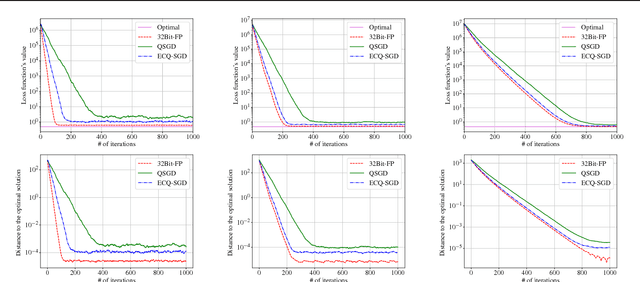
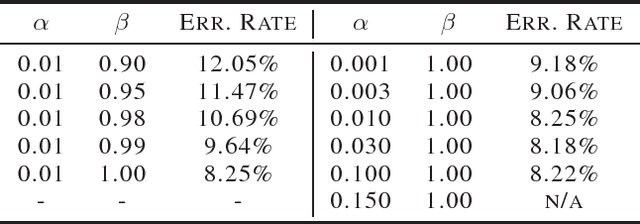
Large-scale distributed optimization is of great importance in various applications. For data-parallel based distributed learning, the inter-node gradient communication often becomes the performance bottleneck. In this paper, we propose the error compensated quantized stochastic gradient descent algorithm to improve the training efficiency. Local gradients are quantized to reduce the communication overhead, and accumulated quantization error is utilized to speed up the convergence. Furthermore, we present theoretical analysis on the convergence behaviour, and demonstrate its advantage over competitors. Extensive experiments indicate that our algorithm can compress gradients by a factor of up to two magnitudes without performance degradation.