 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohesion-based Online Actor-Critic Reinforcement Learning for mHealth Intervention
Paper and Code
Aug 23, 2017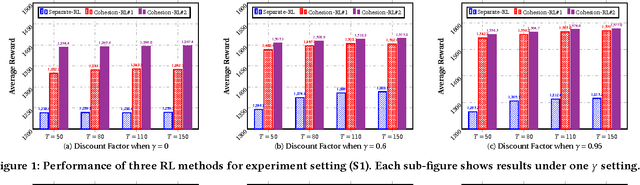
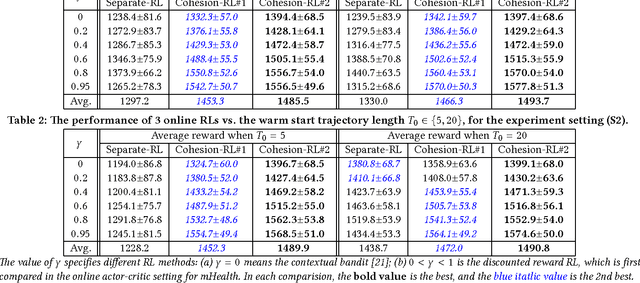
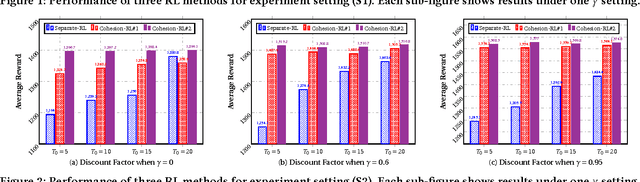
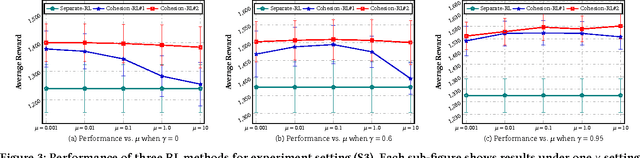
In the wake of the vast population of smart device users worldwide, mobile health (mHealth) technologies are hopeful to generate positive and wide influence on people's health. They are able to provide flexible, affordable and portable health guides to device users. Current online decision-making methods for mHealth assume that the users are completely heterogeneous. They share no information among users and learn a separate policy for each user. However, data for each user is very limited in size to support the separate online learning, leading to unstable policies that contain lots of variances. Besides, we find the truth that a user may be similar with some, but not all, users, and connected users tend to have similar behaviors. In this paper, we propose a network cohesion constrained (actor-critic) Reinforcement Learning (RL) method for mHealth. The goal is to explore how to share information among similar users to better convert the limited user information into sharper learned policies. To the best of our knowledge, this is the first online actor-critic RL for mHealth and first network cohesion constrained (actor-critic) RL method in all applications. The network cohesion is important to derive effective policies. We come up with a novel method to learn the network by using the warm start trajectory, which directly reflects the users' property. The optimization of our model is difficult and very different from the general supervised learning due to the indirect observation of values. As a contribution, we propose two algorithms for the proposed online RLs. Apart from mHealth, the proposed methods can be easily applied or adapted to other health-related tasks. Extensive experiment results on the HeartSteps dataset demonstrates that in a variety of parameter settings, the proposed two methods obtain obvious improvements over the state-of-the-art methods.