 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniArray: Unified Spectral-Spatial Modeling for Array-Geometry-Agnostic Speech Separation
Mar 07, 2025

Array-geometry-agnostic speech separation (AGA-SS) aims to develop an effective separation method regardless of the microphone array geometry. Conventional methods rely on permutation-free operations, such as summation or attention mechanisms, to capture spatial information. However, these approaches often incur high computational costs or disrupt the effective use of spatial information during intra- and inter-channel interactions, leading to suboptimal performance. To address these issues, we propose UniArray, a novel approach that abandons the conventional interleaving manner. UniArray consists of three key components: a virtual microphone estimation (VME) module, a feature extraction and fusion module, and a hierarchical dual-path separator. The VME ensures robust performance across arrays with varying channel numbers. The feature extraction and fusion module leverages a spectral feature extraction module and a spatial dictionary learning (SDL) module to extract and fuse frequency-bin-level features, allowing the separator to focus on using the fused features. The hierarchical dual-path separator models feature dependencies along the time and frequency axes while maintaining computational efficiency. Experimental results show that UniArray outperforms state-of-the-art methods in SI-SDRi, WB-PESQ, NB-PESQ, and STOI across both seen and unseen array geometries.
Paleoinspired Vision: From Exploring Colour Vision Evolution to Inspiring Camera Design
Dec 27, 2024



The evolution of colour vision is captivating, as it reveals the adaptive strategies of extinct species while simultaneously inspiring innovations in modern imaging technology. In this study, we present a simplified model of visual transduction in the retina, introducing a novel opsin layer. We quantify evolutionary pressures by measuring machine vision recognition accuracy on colour images shaped by specific opsins. Building on this, we develop an evolutionary conservation optimisation algorithm to reconstruct the spectral sensitivity of opsins, enabling mutation-driven adaptations to to more effectively spot fruits or predators. This model condenses millions of years of evolution within seconds on GPU, providing an experimental framework to test long-standing hypotheses in evolutionary biology , such as vision of early mammals, primate trichromacy from gene duplication, retention of colour blindness, blue-shift of fish rod and multiple rod opsins with bioluminescence. Moreover, the model enables speculative explorations of hypothetical species, such as organisms with eyes adapted to the conditions on Mars. Our findings suggest a minimalist yet effective approach to task-specific camera filter design, optimising the spectral response function to meet application-driven demands. The code will be made publicly available upon acceptance.
Fine-Grained Urban Flow Inference with Multi-scale Representation Learning
Jun 14, 2024Fine-grained urban flow inference (FUFI) is a crucial transportation service aimed at improving traffic efficiency and safety. FUFI can infer fine-grained urban traffic flows based solely on observed coarse-grained data. However, most of existing methods focus on the influence of single-scale static geographic information on FUFI, neglecting the interactions and dynamic information between different-scale regions within the city. Different-scale geographical features can capture redundant information from the same spatial areas. In order to effectively learn multi-scale information across time and space, we propose an effective fine-grained urban flow inference model called UrbanMSR, which uses self-supervised contrastive learning to obtain dynamic multi-scale representations of neighborhood-level and city-level geographic information, and fuses multi-scale representations to improve fine-grained accuracy. The fusion of multi-scale representations enhances fine-grained. We validate the performance through extensive experiments on three real-world datasets. The resutls compared with state-of-the-art methods demonstrate the superiority of the proposed model.
SAM-E: Leveraging Visual Foundation Model with Sequence Imitation for Embodied Manipulation
May 30, 2024



Acquiring a multi-task imitation policy in 3D manipulation poses challenges in terms of scene understanding and action prediction. Current methods employ both 3D representation and multi-view 2D representation to predict the poses of the robot's end-effector. However, they still require a considerable amount of high-quality robot trajectories, and suffer from limited generalization in unseen tasks and inefficient execution in long-horizon reasoning. In this paper, we propose SAM-E, a novel architecture for robot manipulation by leveraging a vision-foundation model for generalizable scene understanding and sequence imitation for long-term action reasoning. Specifically, we adopt Segment Anything (SAM) pre-trained on a huge number of images and promptable masks as the foundation model for extracting task-relevant features, and employ parameter-efficient fine-tuning on robot data for a better understanding of embodied scenarios. To address long-horizon reasoning, we develop a novel multi-channel heatmap that enables the prediction of the action sequence in a single pass, notably enhancing execution efficiency. Experimental results from various instruction-following tasks demonstrate that SAM-E achieves superior performance with higher execution efficiency compared to the baselines, and also significantly improves generalization in few-shot adaptation to new tasks.
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
May 10, 2024



The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset
Apr 23, 2024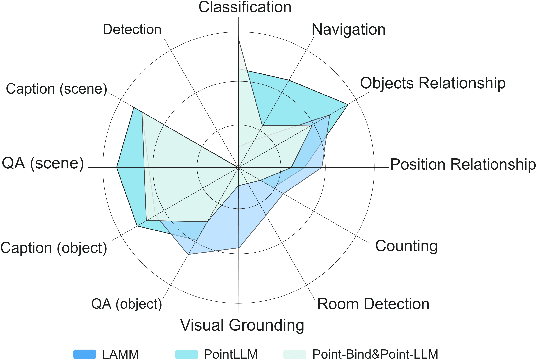
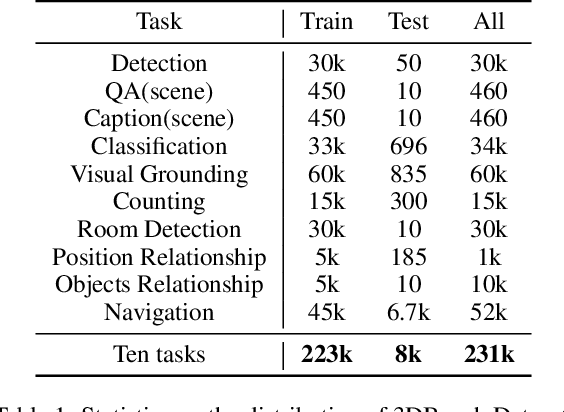
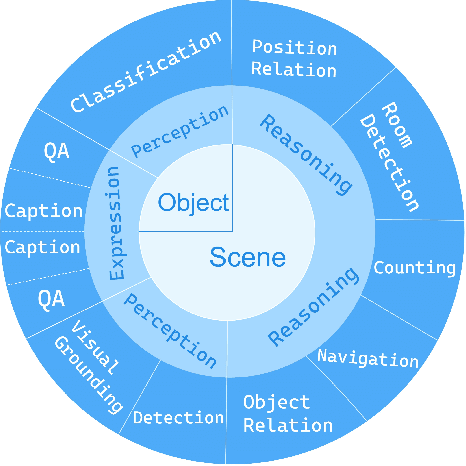

Evaluating the performance of Multi-modal Large Language Models (MLLMs), integrating both point cloud and language, presents significant challenges. The lack of a comprehensive assessment hampers determining whether these models truly represent advancements, thereby impeding further progress in the field. Current evaluations heavily rely on classification and caption tasks, falling short in providing a thorough assessment of MLLMs. A pressing need exists for a more sophisticated evaluation method capable of thoroughly analyzing the spatial understanding and expressive capabilities of these models. To address these issues, we introduce a scalable 3D benchmark, accompanied by a large-scale instruction-tuning dataset known as 3DBench, providing an extensible platform for a comprehensive evaluation of MLLMs. Specifically, we establish the benchmark that spans a wide range of spatial and semantic scales, from object-level to scene-level, addressing both perception and planning tasks. Furthermore, we present a rigorous pipeline for automatically constructing scalable 3D instruction-tuning datasets, covering 10 diverse multi-modal tasks with more than 0.23 million QA pairs generated in total. Thorough experiments evaluating trending MLLMs, comparisons against existing datasets, and variations of training protocols demonstrate the superiority of 3DBench, offering valuable insights into current limitations and potential research directions.
Sequence-level Semantic Representation Fusion for Recommender Systems
Feb 28, 2024



With the rapid development of recommender systems, there is increasing side information that can be employed to improve the recommendation performance. Specially, we focus on the utilization of the associated \emph{textual data} of items (eg product title) and study how text features can be effectively fused with ID features in sequential recommendation. However, there exists distinct data characteristics for the two kinds of item features, making a direct fusion method (eg adding text and ID embeddings as item representation) become less effective. To address this issue, we propose a novel {\ul \emph{Te}}xt-I{\ul \emph{D}} semantic fusion approach for sequential {\ul \emph{Rec}}ommendation, namely \textbf{\our}. The core idea of our approach is to conduct a sequence-level semantic fusion approach by better integrating global contexts. The key strategy lies in that we transform the text embeddings and ID embeddings by Fourier Transform from \emph{time domain} to \emph{frequency domain}. In the frequency domain, the global sequential characteristics of the original sequences are inherently aggregated into the transformed representations, so that we can employ simple multiplicative operations to effectively fuse the two kinds of item features. Our fusion approach can be proved to have the same effects of contextual convolution, so as to achieving sequence-level semantic fusion. In order to further improve the fusion performance, we propose to enhance the discriminability of the text embeddings from the text encoder, by adaptively injecting positional information via a mixture-of-experts~(MoE) modulation method. Our implementation is available at this repository: \textcolor{magenta}{\url{https://github.com/RUCAIBox/TedRec}}.
Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis
Jan 10, 2024



Recently, large language models such as ChatGPT have showcased remarkable abilities in solving general tasks, demonstrating the potential for applications in recommender systems. To assess how effectively LLMs can be used in recommendation tasks, our study primarily focuses on employing LLMs as recommender systems through prompting engineering. We propose a general framework for utilizing LLMs in recommendation tasks, focusing on the capabilities of LLMs as recommenders. To conduct our analysis, we formalize the input of LLMs for recommendation into natural language prompts with two key aspects, and explain how our framework can be generalized to various recommendation scenarios. As for the use of LLMs as recommenders, we analyze the impact of public availability, tuning strategies, model architecture, parameter scale, and context length on recommendation results based on the classification of LLMs. As for prompt engineering, we further analyze the impact of four important components of prompts, \ie task descriptions, user interest modeling, candidate items construction and prompting strategies. In each section, we first define and categorize concepts in line with the existing literature. Then, we propose inspiring research questions followed by experiments to systematically analyze the impact of different factors on two public datasets. Finally, we summarize promising directions to shed lights on future research.
Distillation is All You Need for Practically Using Different Pre-trained Recommendation Models
Jan 01, 2024Pre-trained recommendation models (PRMs) have attracted widespread attention recently. However, their totally different model structure, huge model size and computation cost hinder their application in practical recommender systems. Hence, it is highly essential to explore how to practically utilize PRMs in real-world recommendations. In this paper, we propose a novel joint knowledge distillation from different pre-trained recommendation models named PRM-KD for recommendation, which takes full advantages of diverse PRMs as teacher models for enhancing student models efficiently. Specifically, PRM-KD jointly distills diverse informative knowledge from multiple representative PRMs such as UniSRec, Recformer, and UniM^2Rec. The knowledge from the above PRMs are then smartly integrated into the student recommendation model considering their confidence and consistency. We further verify the universality of PRM-KD with various types of student models, including sequential recommendation, feature interaction, and graph-based models. Extensive experiments on five real-world datasets demonstrate the effectiveness and efficacy of PRM-KD, which could be viewed as an economical shortcut in practically and conveniently making full use of different PRMs in online systems.
AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems
Oct 13, 2023Recently, there has been an emergence of employing LLM-powered agents as believable human proxies, based on their remarkable decision-making capability. However, existing studies mainly focus on simulating human dialogue. Human non-verbal behaviors, such as item clicking in recommender systems, although implicitly exhibiting user preferences and could enhance the modeling of users, have not been deeply explored. The main reasons lie in the gap between language modeling and behavior modeling, as well as the incomprehension of LLMs about user-item relations. To address this issue, we propose AgentCF for simulating user-item interactions in recommender systems through agent-based collaborative filtering. We creatively consider not only users but also items as agents, and develop a collaborative learning approach that optimizes both kinds of agents together. Specifically, at each time step, we first prompt the user and item agents to interact autonomously. Then, based on the disparities between the agents' decisions and real-world interaction records, user and item agents are prompted to reflect on and adjust the misleading simulations collaboratively, thereby modeling their two-sided relations. The optimized agents can also propagate their preferences to other agents in subsequent interactions, implicitly capturing the collaborative filtering idea. Overall, the optimized agents exhibit diverse interaction behaviors within our framework, including user-item, user-user, item-item, and collective interactions. The results show that these agents can demonstrate personalized behaviors akin to those of real-world individuals, sparking the development of next-generation user behavior simulation.