 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid R-CNN
Nov 29, 2018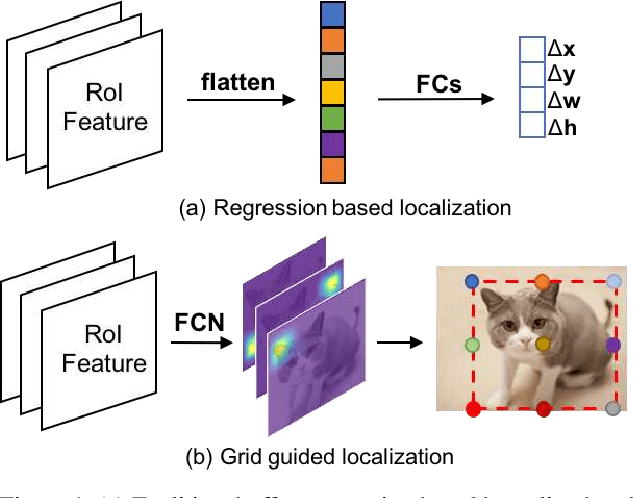
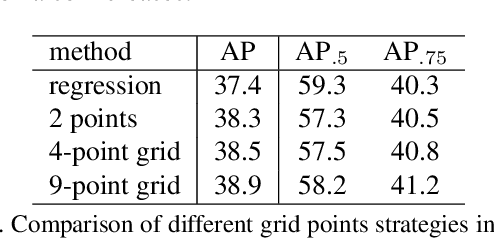
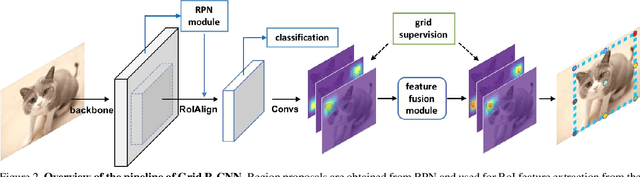
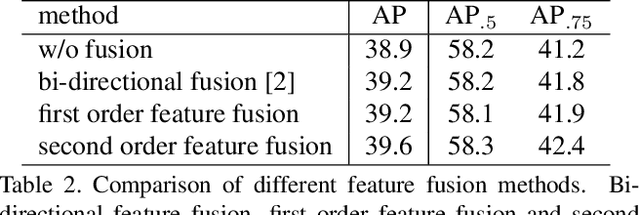
This paper proposes a novel object detection framework named Grid R-CNN, which adopts a grid guided localization mechanism for accurate object detection. Different from the traditional regression based methods, the Grid R-CNN captures the spatial information explicitly and enjoys the position sensitive property of fully convolutional architecture. Instead of using only two independent points, we design a multi-point supervision formulation to encode more clues in order to reduce the impact of inaccurate prediction of specific points. To take the full advantage of the correlation of points in a grid, we propose a two-stage information fusion strategy to fuse feature maps of neighbor grid points. The grid guided localization approach is easy to be extended to different state-of-the-art detection frameworks. Grid R-CNN leads to high quality object localization, and experiments demonstrate that it achieves a 4.1% AP gain at IoU=0.8 and a 10.0% AP gain at IoU=0.9 on COCO benchmark compared to Faster R-CNN with Res50 backbone and FPN architecture.
Synaptic Strength For Convolutional Neural Network
Nov 06, 2018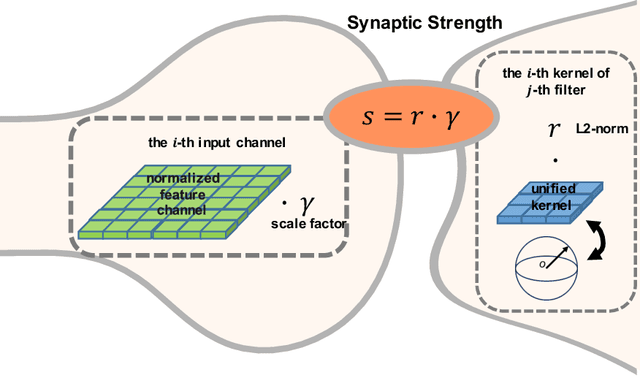
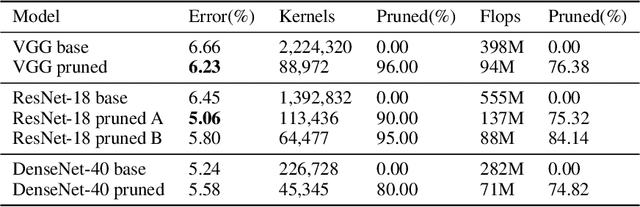
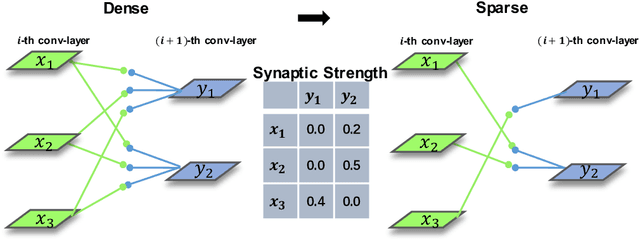
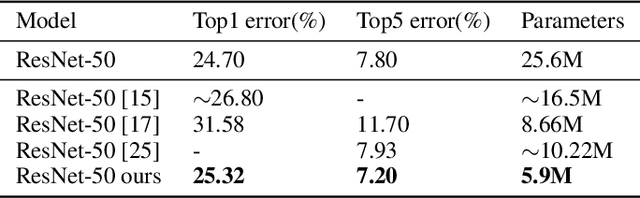
Convolutional Neural Networks(CNNs) are both computation and memory intensive which hindered their deployment in mobile devices. Inspired by the relevant concept in neural science literature, we propose Synaptic Pruning: a data-driven method to prune connections between input and output feature maps with a newly proposed class of parameters called Synaptic Strength. Synaptic Strength is designed to capture the importance of a connection based on the amount of information it transports. Experiment results show the effectiveness of our approach. On CIFAR-10, we prune connections for various CNN models with up to 96% , which results in significant size reduction and computation saving. Further evaluation on ImageNet demonstrates that synaptic pruning is able to discover efficient models which is competitive to state-of-the-art compact CNNs such as MobileNet-V2 and NasNet-Mobile. Our contribution is summarized as following: (1) We introduce Synaptic Strength, a new class of parameters for CNNs to indicate the importance of each connections. (2) Our approach can prune various CNNs with high compression without compromising accuracy. (3) Further investigation shows, the proposed Synaptic Strength is a better indicator for kernel pruning compared with the previous approach in both empirical result and theoretical analysis.
Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection
Sep 16, 2018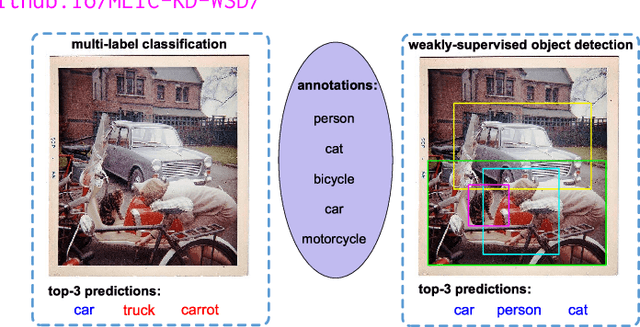
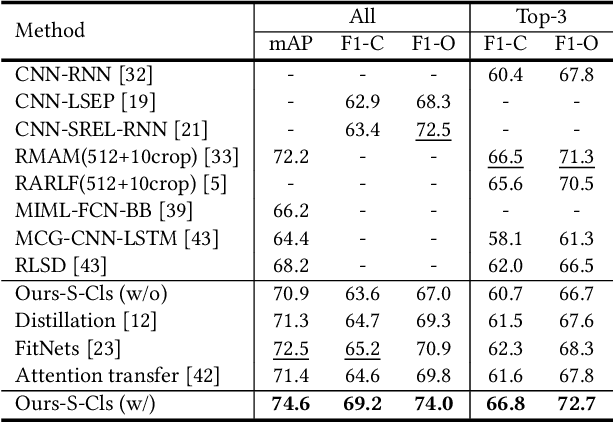
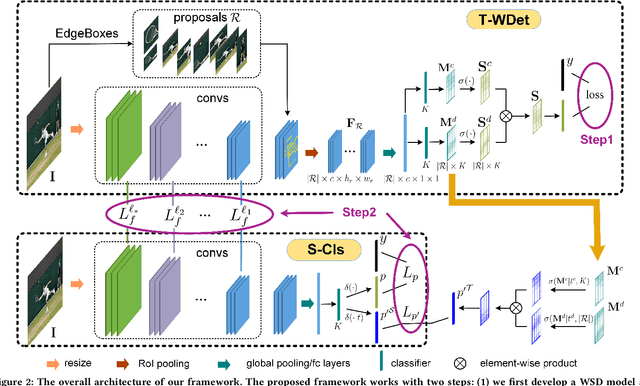
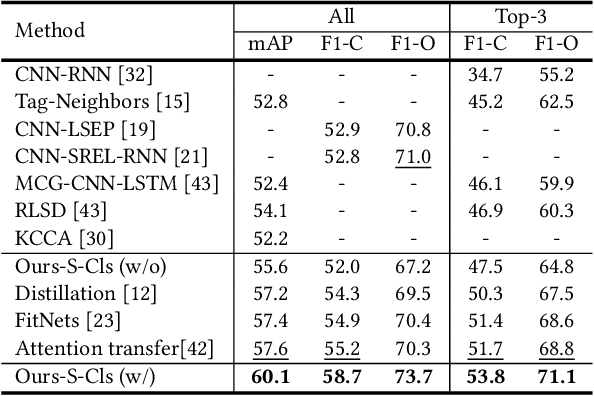
Multi-label image classification is a fundamental but challenging task towards general visual understanding. Existing methods found the region-level cues (e.g., features from RoIs) can facilitate multi-label classification. Nevertheless, such methods usually require laborious object-level annotations (i.e., object labels and bounding boxes) for effective learning of the object-level visual features. In this paper, we propose a novel and efficient deep framework to boost multi-label classification by distilling knowledge from weakly-supervised detection task without bounding box annotations. Specifically, given the image-level annotations, (1) we first develop a weakly-supervised detection (WSD) model, and then (2) construct an end-to-end multi-label image classification framework augmented by a knowledge distillation module that guides the classification model by the WSD model according to the class-level predictions for the whole image and the object-level visual features for object RoIs. The WSD model is the teacher model and the classification model is the student model. After this cross-task knowledge distillation, the performance of the classification model is significantly improved and the efficiency is maintained since the WSD model can be safely discarded in the test phase. Extensive experiments on two large-scale datasets (MS-COCO and NUS-WIDE) show that our framework achieves superior performances over the state-of-the-art methods on both performance and efficiency.
Quantization Mimic: Towards Very Tiny CNN for Object Detection
Sep 13, 2018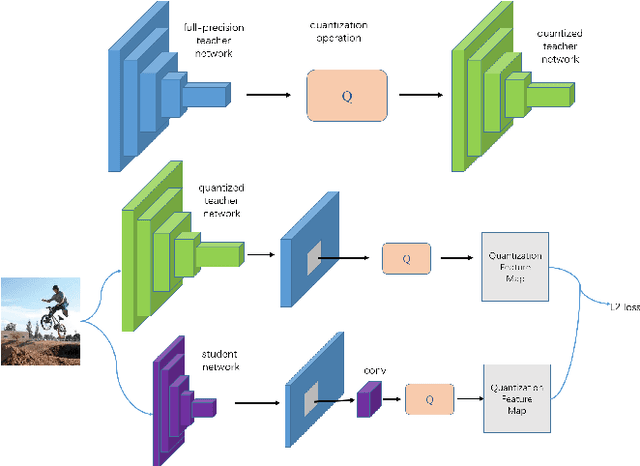
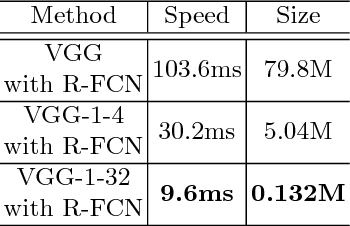
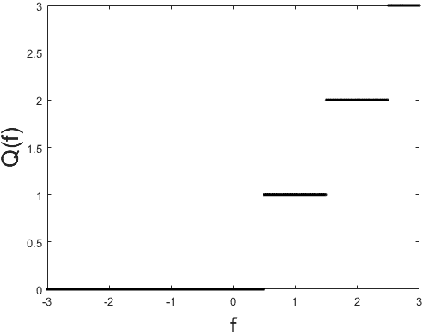
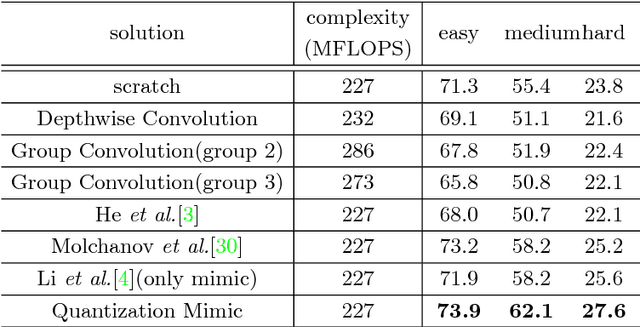
In this paper, we propose a simple and general framework for training very tiny CNNs for object detection. Due to limited representation ability, it is challenging to train very tiny networks for complicated tasks like detection. To the best of our knowledge, our method, called Quantization Mimic, is the first one focusing on very tiny networks. We utilize two types of acceleration methods: mimic and quantization. Mimic improves the performance of a student network by transfering knowledge from a teacher network. Quantization converts a full-precision network to a quantized one without large degradation of performance. If the teacher network is quantized, the search scope of the student network will be smaller. Using this feature of the quantization, we propose Quantization Mimic. It first quantizes the large network, then mimic a quantized small network. The quantization operation can help student network to better match the feature maps from teacher network. To evaluate our approach, we carry out experiments on various popular CNNs including VGG and Resnet, as well as different detection frameworks including Faster R-CNN and R-FCN. Experiments on Pascal VOC and WIDER FACE verify that our Quantization Mimic algorithm can be applied on various settings and outperforms state-of-the-art model acceleration methods given limited computing resouces.
Consensus-Driven Propagation in Massive Unlabeled Data for Face Recognition
Sep 05, 2018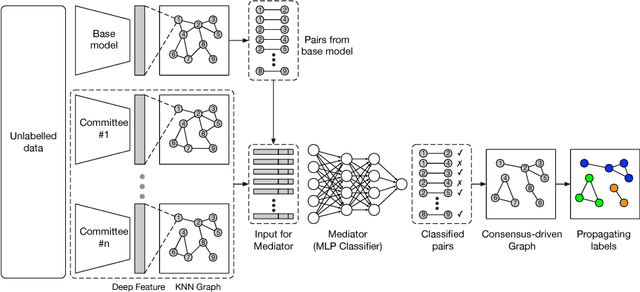
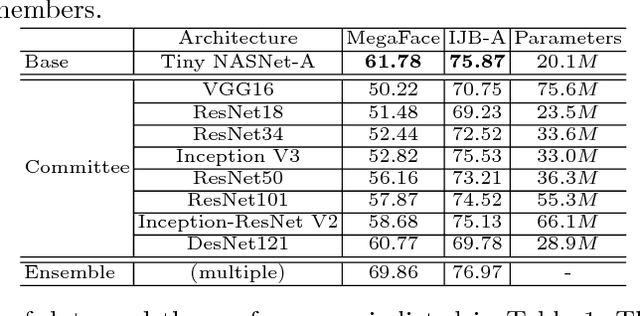
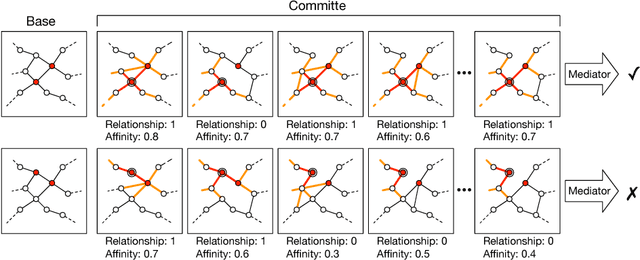
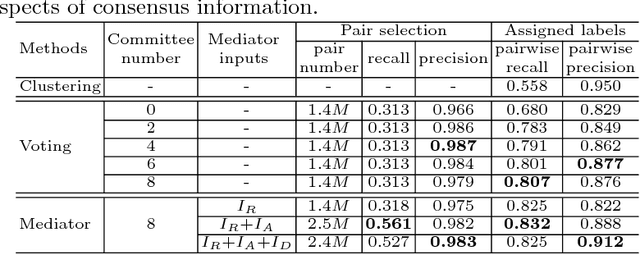
Face recognition has witnessed great progress in recent years, mainly attributed to the high-capacity model designed and the abundant labeled data collected. However, it becomes more and more prohibitive to scale up the current million-level identity annotations. In this work, we show that unlabeled face data can be as effective as the labeled ones. Here, we consider a setting closely mimicking the real-world scenario, where the unlabeled data are collected from unconstrained environments and their identities are exclusive from the labeled ones. Our main insight is that although the class information is not available, we can still faithfully approximate these semantic relationships by constructing a relational graph in a bottom-up manner. We propose Consensus-Driven Propagation (CDP) to tackle this challenging problem with two modules, the "committee" and the "mediator", which select positive face pairs robustly by carefully aggregating multi-view information. Extensive experiments validate the effectiveness of both modules to discard outliers and mine hard positives. With CDP, we achieve a compelling accuracy of 78.18% on MegaFace identification challenge by using only 9% of the labels, comparing to 61.78% when no unlabeled data are used and 78.52% when all labels are employed.
Localization Guided Learning for Pedestrian Attribute Recognition
Aug 28, 2018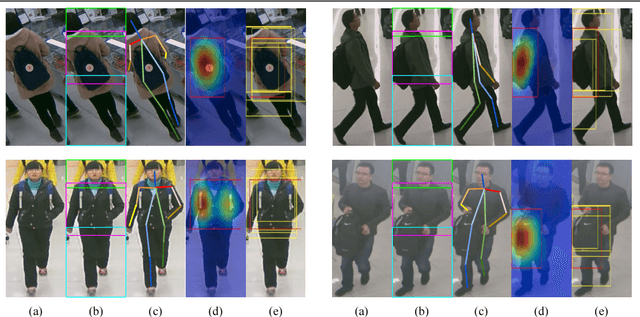
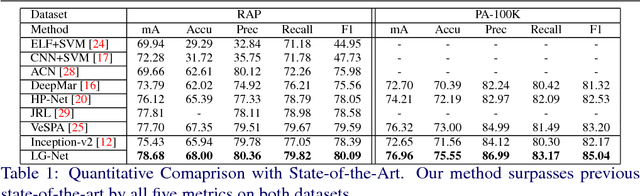
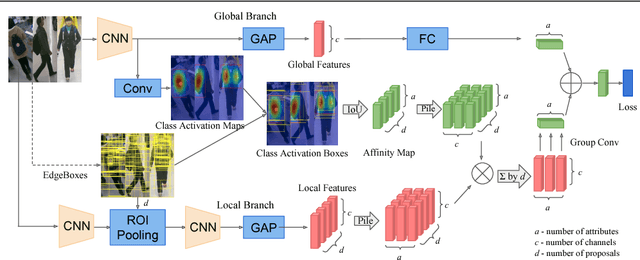
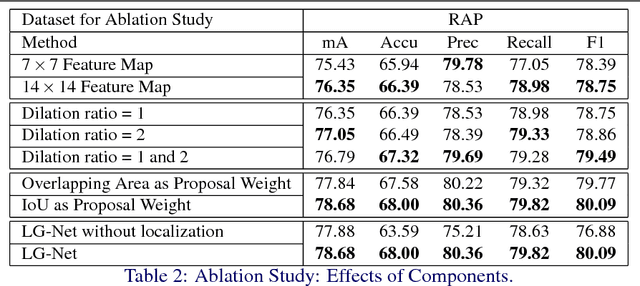
Pedestrian attribute recognition has attracted many attentions due to its wide applications in scene understanding and person analysis from surveillance videos. Existing methods try to use additional pose, part or viewpoint information to complement the global feature representation for attribute classification. However, these methods face difficulties in localizing the areas corresponding to different attributes. To address this problem, we propose a novel Localization Guided Network which assigns attribute-specific weights to local features based on the affinity between proposals pre-extracted proposals and attribute locations. The advantage of our model is that our local features are learned automatically for each attribute and emphasized by the interaction with global features. We demonstrate the effectiveness of our Localization Guided Network on two pedestrian attribute benchmarks (PA-100K and RAP). Our result surpasses the previous state-of-the-art in all five metrics on both datasets.
Distractor-aware Siamese Networks for Visual Object Tracking
Aug 18, 2018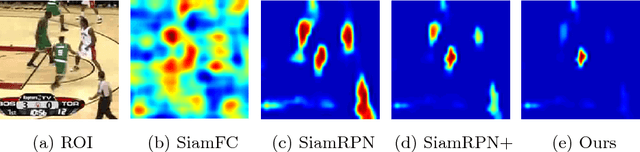
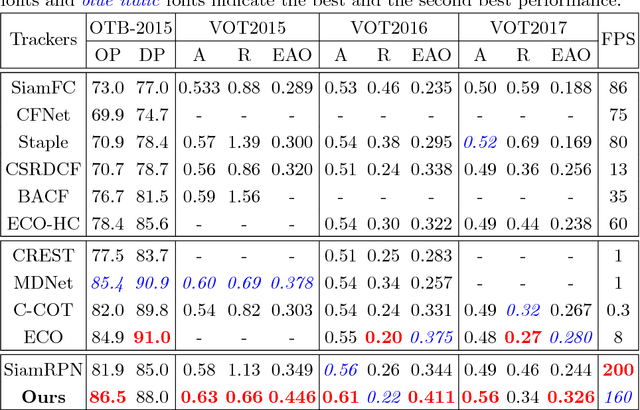


Recently, Siamese networks have drawn great attention in visual tracking community because of their balanced accuracy and speed. However, features used in most Siamese tracking approaches can only discriminate foreground from the non-semantic backgrounds. The semantic backgrounds are always considered as distractors, which hinders the robustness of Siamese trackers. In this paper, we focus on learning distractor-aware Siamese networks for accurate and long-term tracking. To this end, features used in traditional Siamese trackers are analyzed at first. We observe that the imbalanced distribution of training data makes the learned features less discriminative. During the off-line training phase, an effective sampling strategy is introduced to control this distribution and make the model focus on the semantic distractors. During inference, a novel distractor-aware module is designed to perform incremental learning, which can effectively transfer the general embedding to the current video domain. In addition, we extend the proposed approach for long-term tracking by introducing a simple yet effective local-to-global search region strategy. Extensive experiments on benchmarks show that our approach significantly outperforms the state-of-the-arts, yielding 9.6% relative gain in VOT2016 dataset and 35.9% relative gain in UAV20L dataset. The proposed tracker can perform at 160 FPS on short-term benchmarks and 110 FPS on long-term benchmarks.
BlockQNN: Efficient Block-wise Neural Network Architecture Generation
Aug 16, 2018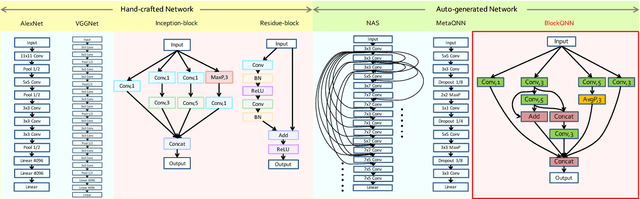
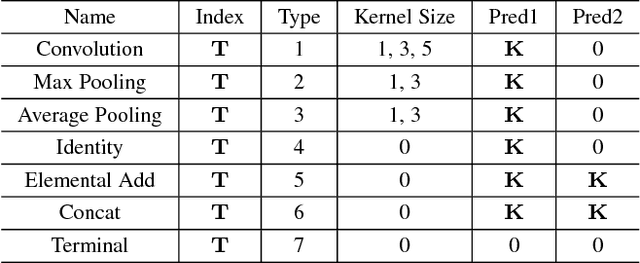
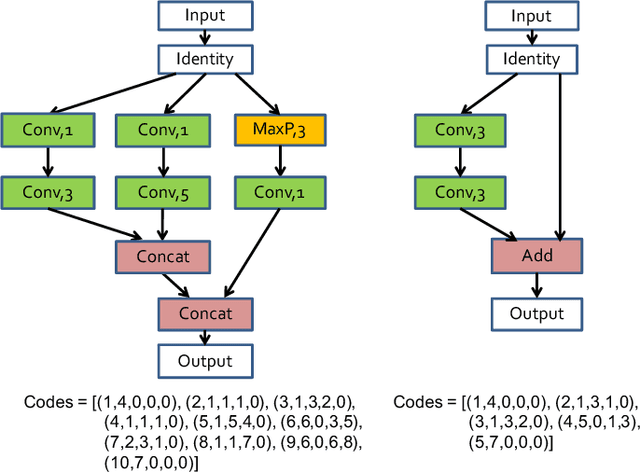

Convolutional neural networks have gained a remarkable success in computer vision. However, most usable network architectures are hand-crafted and usually require expertise and elaborate design. In this paper, we provide a block-wise network generation pipeline called BlockQNN which automatically builds high-performance networks using the Q-Learning paradigm with epsilon-greedy exploration strategy. The optimal network block is constructed by the learning agent which is trained to choose component layers sequentially. We stack the block to construct the whole auto-generated network. To accelerate the generation process, we also propose a distributed asynchronous framework and an early stop strategy. The block-wise generation brings unique advantages: (1) it yields state-of-the-art results in comparison to the hand-crafted networks on image classification, particularly, the best network generated by BlockQNN achieves 2.35% top-1 error rate on CIFAR-10. (2) it offers tremendous reduction of the search space in designing networks, spending only 3 days with 32 GPUs. A faster version can yield a comparable result with only 1 GPU in 20 hours. (3) it has strong generalizability in that the network built on CIFAR also performs well on the larger-scale dataset. The best network achieves very competitive accuracy of 82.0% top-1 and 96.0% top-5 on ImageNet.
Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy
Jun 02, 2018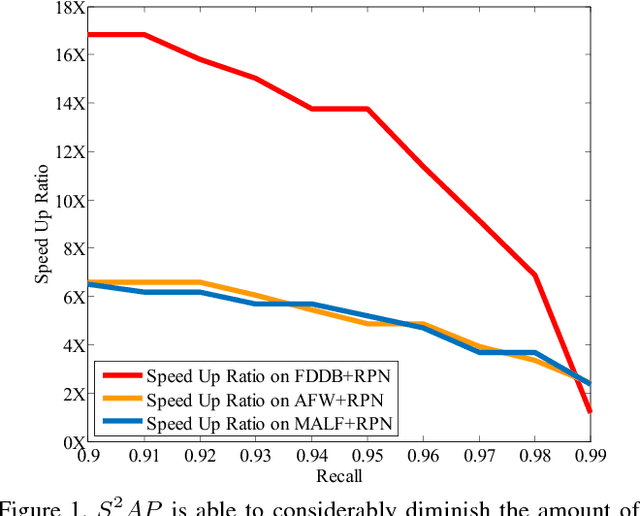

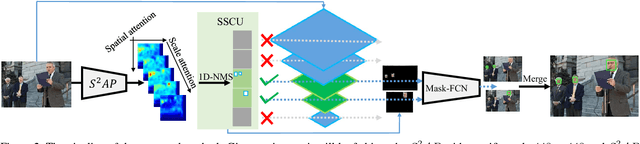
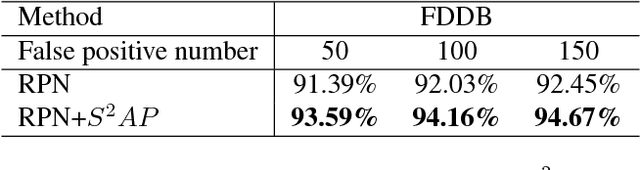
Fully convolutional neural network (FCN) has been dominating the game of face detection task for a few years with its congenital capability of sliding-window-searching with shared kernels, which boiled down all the redundant calculation, and most recent state-of-the-art methods such as Faster-RCNN, SSD, YOLO and FPN use FCN as their backbone. So here comes one question: Can we find a universal strategy to further accelerate FCN with higher accuracy, so could accelerate all the recent FCN-based methods? To analyze this, we decompose the face searching space into two orthogonal directions, `scale' and `spatial'. Only a few coordinates in the space expanded by the two base vectors indicate foreground. So if FCN could ignore most of the other points, the searching space and false alarm should be significantly boiled down. Based on this philosophy, a novel method named scale estimation and spatial attention proposal ($S^2AP$) is proposed to pay attention to some specific scales and valid locations in the image pyramid. Furthermore, we adopt a masked-convolution operation based on the attention result to accelerate FCN calculation. Experiments show that FCN-based method RPN can be accelerated by about $4\times$ with the help of $S^2AP$ and masked-FCN and at the same time it can also achieve the state-of-the-art on FDDB, AFW and MALF face detection benchmarks as well.
Practical Block-wise Neural Network Architecture Generation
May 14, 2018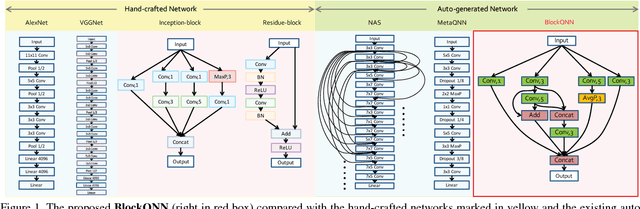
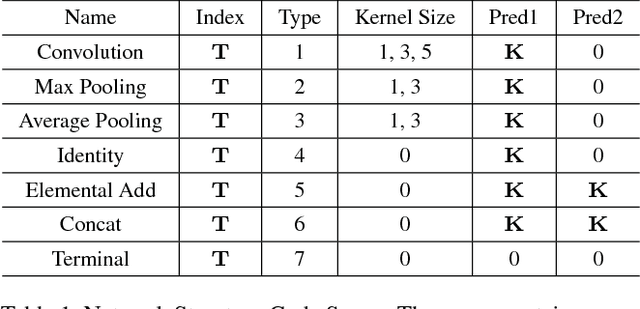


Convolutional neural networks have gained a remarkable success in computer vision. However, most usable network architectures are hand-crafted and usually require expertise and elaborate design. In this paper, we provide a block-wise network generation pipeline called BlockQNN which automatically builds high-performance networks using the Q-Learning paradigm with epsilon-greedy exploration strategy. The optimal network block is constructed by the learning agent which is trained sequentially to choose component layers. We stack the block to construct the whole auto-generated network. To accelerate the generation process, we also propose a distributed asynchronous framework and an early stop strategy. The block-wise generation brings unique advantages: (1) it performs competitive results in comparison to the hand-crafted state-of-the-art networks on image classification, additionally, the best network generated by BlockQNN achieves 3.54% top-1 error rate on CIFAR-10 which beats all existing auto-generate networks. (2) in the meanwhile, it offers tremendous reduction of the search space in designing networks which only spends 3 days with 32 GPUs, and (3) moreover, it has strong generalizability that the network built on CIFAR also performs well on a larger-scale ImageNet dataset.