 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSDiffusion: Harmonized Multi-Layer Image Generation via Layout and Appearance Alignment
May 16, 2025



Diffusion models have made remarkable advancements in generating high-quality images from textual descriptions. Recent works like LayerDiffuse have extended the previous single-layer, unified image generation paradigm to transparent image layer generation. However, existing multi-layer generation methods fail to handle the interactions among multiple layers such as rational global layout, physics-plausible contacts and visual effects like shadows and reflections while maintaining high alpha quality. To solve this problem, we propose PSDiffusion, a unified diffusion framework for simultaneous multi-layer text-to-image generation. Our model can automatically generate multi-layer images with one RGB background and multiple RGBA foregrounds through a single feed-forward process. Unlike existing methods that combine multiple tools for post-decomposition or generate layers sequentially and separately, our method introduces a global-layer interactive mechanism that generates layered-images concurrently and collaboratively, ensuring not only high quality and completeness for each layer, but also spatial and visual interactions among layers for global coherence.
Evolutionary Stochastic Policy Distillation
Apr 30, 2020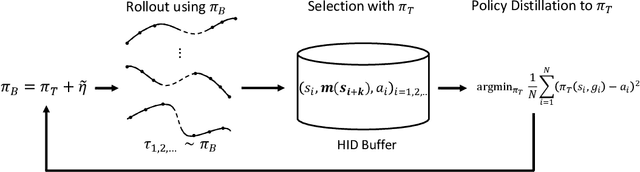


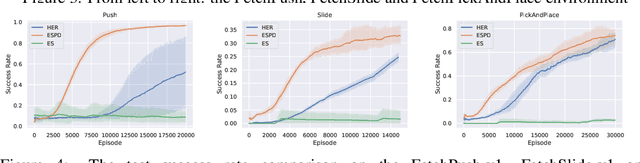
Solving the Goal-Conditioned Reward Sparse (GCRS) task is a challenging reinforcement learning problem due to the sparsity of reward signals. In this work, we propose a new formulation of GCRS tasks from the perspective of the drifted random walk on the state space, and design a novel method called Evolutionary Stochastic Policy Distillation (ESPD) to solve them based on the insight of reducing the First Hitting Time of the stochastic process. As a self-imitate approach, ESPD enables a target policy to learn from a series of its stochastic variants through the technique of policy distillation (PD). The learning mechanism of ESPD can be considered as an Evolution Strategy (ES) that applies perturbations upon policy directly on the action space, with a SELECT function to check the superiority of stochastic variants and then use PD to update the policy. The experiments based on the MuJoCo robotics control suite show the high learning efficiency of the proposed method.
Quantization Mimic: Towards Very Tiny CNN for Object Detection
Sep 13, 2018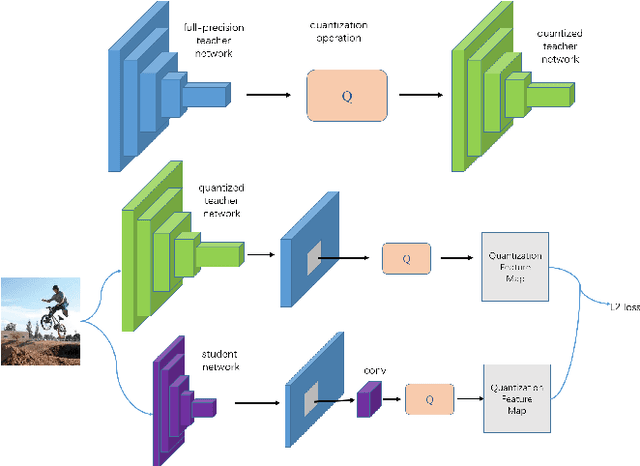
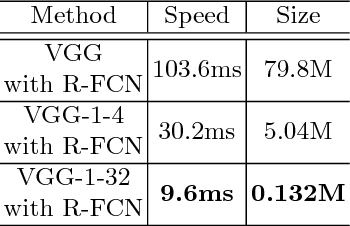
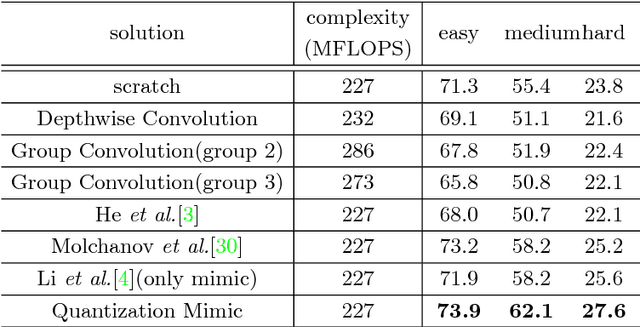
In this paper, we propose a simple and general framework for training very tiny CNNs for object detection. Due to limited representation ability, it is challenging to train very tiny networks for complicated tasks like detection. To the best of our knowledge, our method, called Quantization Mimic, is the first one focusing on very tiny networks. We utilize two types of acceleration methods: mimic and quantization. Mimic improves the performance of a student network by transfering knowledge from a teacher network. Quantization converts a full-precision network to a quantized one without large degradation of performance. If the teacher network is quantized, the search scope of the student network will be smaller. Using this feature of the quantization, we propose Quantization Mimic. It first quantizes the large network, then mimic a quantized small network. The quantization operation can help student network to better match the feature maps from teacher network. To evaluate our approach, we carry out experiments on various popular CNNs including VGG and Resnet, as well as different detection frameworks including Faster R-CNN and R-FCN. Experiments on Pascal VOC and WIDER FACE verify that our Quantization Mimic algorithm can be applied on various settings and outperforms state-of-the-art model acceleration methods given limited computing resouces.