 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetropolis-Hastings Data Augmentation for Graph Neural Networks
Mar 26, 2022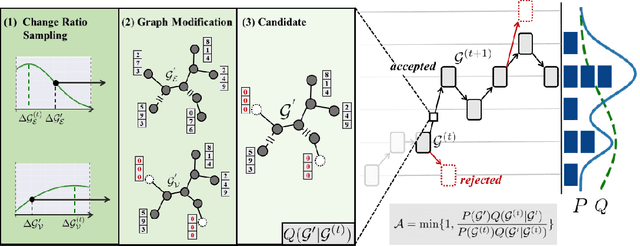
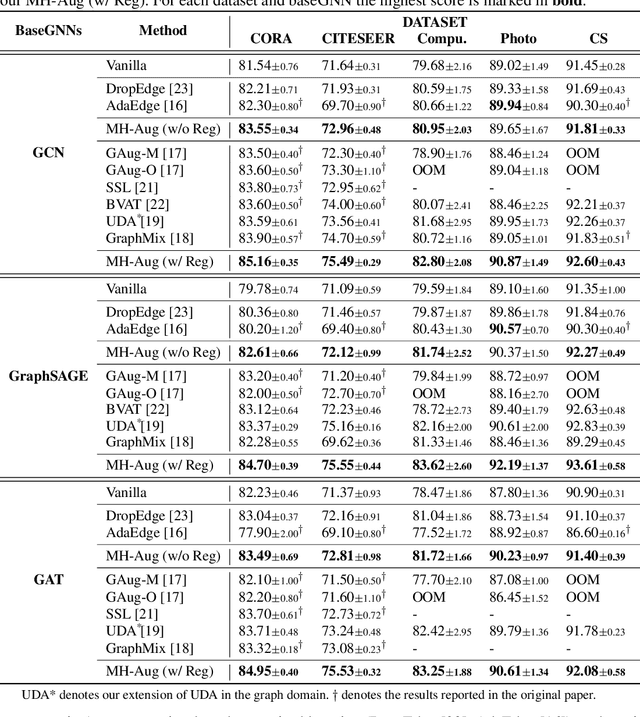
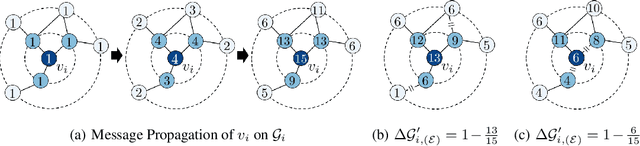
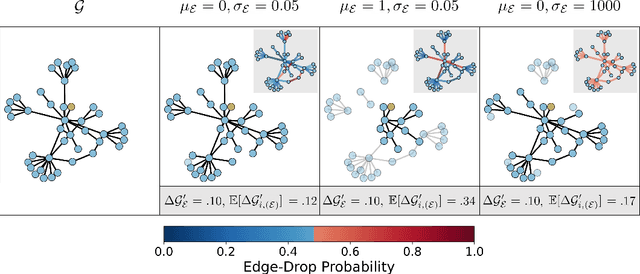
Graph Neural Networks (GNNs) often suffer from weak-generalization due to sparsely labeled data despite their promising results on various graph-based tasks. Data augmentation is a prevalent remedy to improve the generalization ability of models in many domains. However, due to the non-Euclidean nature of data space and the dependencies between samples, designing effective augmentation on graphs is challenging. In this paper, we propose a novel framework Metropolis-Hastings Data Augmentation (MH-Aug) that draws augmented graphs from an explicit target distribution for semi-supervised learning. MH-Aug produces a sequence of augmented graphs from the target distribution enables flexible control of the strength and diversity of augmentation. Since the direct sampling from the complex target distribution is challenging, we adopt the Metropolis-Hastings algorithm to obtain the augmented samples. We also propose a simple and effective semi-supervised learning strategy with generated samples from MH-Aug. Our extensive experiments demonstrate that MH-Aug can generate a sequence of samples according to the target distribution to significantly improve the performance of GNNs.
Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
Feb 21, 2022
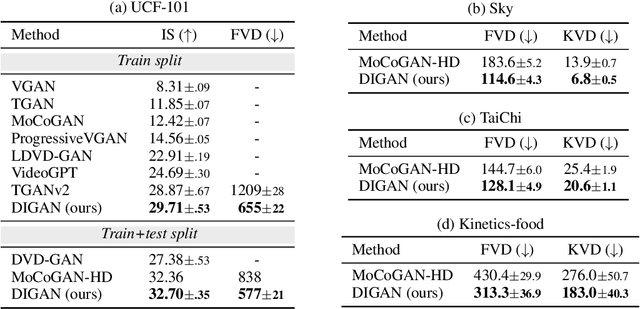
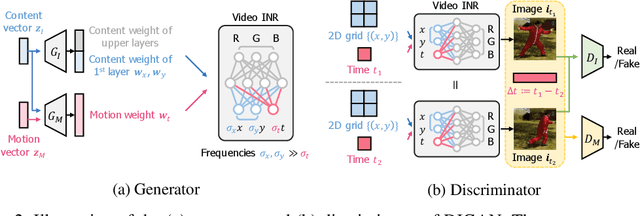
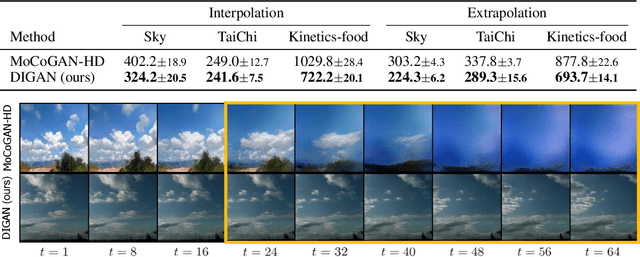
In the deep learning era, long video generation of high-quality still remains challenging due to the spatio-temporal complexity and continuity of videos. Existing prior works have attempted to model video distribution by representing videos as 3D grids of RGB values, which impedes the scale of generated videos and neglects continuous dynamics. In this paper, we found that the recent emerging paradigm of implicit neural representations (INRs) that encodes a continuous signal into a parameterized neural network effectively mitigates the issue. By utilizing INRs of video, we propose dynamics-aware implicit generative adversarial network (DIGAN), a novel generative adversarial network for video generation. Specifically, we introduce (a) an INR-based video generator that improves the motion dynamics by manipulating the space and time coordinates differently and (b) a motion discriminator that efficiently identifies the unnatural motions without observing the entire long frame sequences. We demonstrate the superiority of DIGAN under various datasets, along with multiple intriguing properties, e.g., long video synthesis, video extrapolation, and non-autoregressive video generation. For example, DIGAN improves the previous state-of-the-art FVD score on UCF-101 by 30.7% and can be trained on 128 frame videos of 128x128 resolution, 80 frames longer than the 48 frames of the previous state-of-the-art method.
Contrastive Fine-grained Class Clustering via Generative Adversarial Networks
Dec 30, 2021
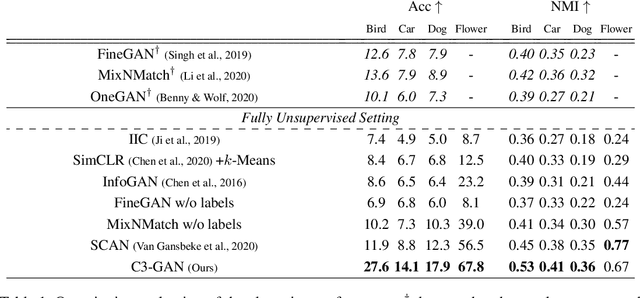
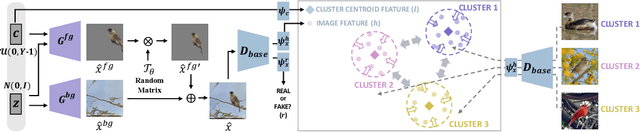

Unsupervised fine-grained class clustering is practical yet challenging task due to the difficulty of feature representations learning of subtle object details. We introduce C3-GAN, a method that leverages the categorical inference power of InfoGAN by applying contrastive learning. We aim to learn feature representations that encourage the data to form distinct cluster boundaries in the embedding space, while also maximizing the mutual information between the latent code and its observation. Our approach is to train the discriminator, which is used for inferring clusters, to optimize the contrastive loss, where the image-latent pairs that maximize the mutual information are considered as positive pairs and the rest as negative pairs. Specifically, we map the input of the generator, which has sampled from the categorical distribution, to the embedding space of the discriminator and let them act as a cluster centroid. In this way, C3-GAN achieved to learn a clustering-friendly embedding space where each cluster is distinctively separable. Experimental results show that C3-GAN achieved state-of-the-art clustering performance on four fine-grained benchmark datasets, while also alleviating the mode collapse phenomenon.
Online Continual Learning on Class Incremental Blurry Task Configuration with Anytime Inference
Oct 19, 2021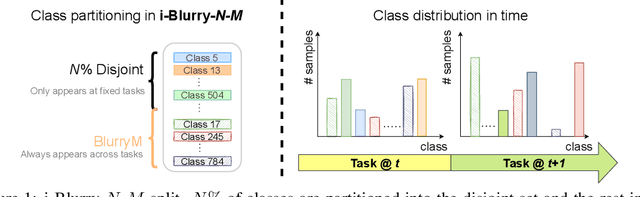
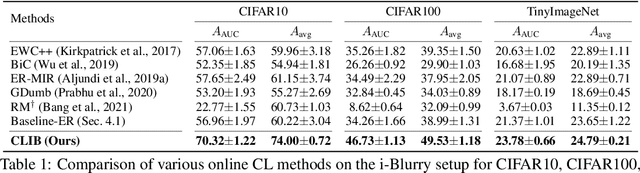
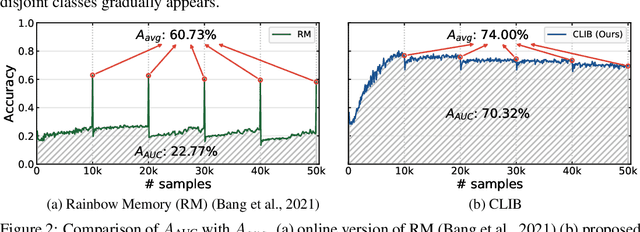
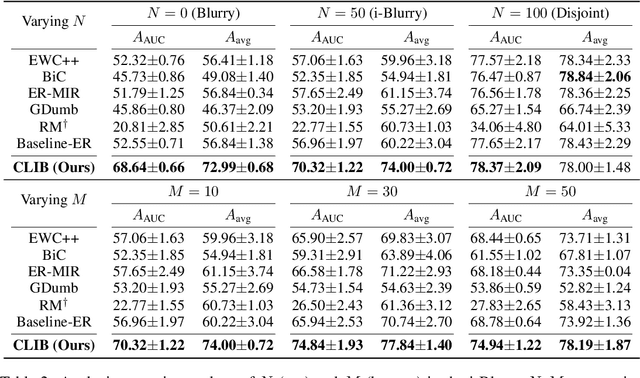
Despite rapid advances in continual learning, a large body of research is devoted to improving performance in the existing setups. While a handful of work do propose new continual learning setups, they still lack practicality in certain aspects. For better practicality, we first propose a novel continual learning setup that is online, task-free, class-incremental, of blurry task boundaries and subject to inference queries at any moment. We additionally propose a new metric to better measure the performance of the continual learning methods subject to inference queries at any moment. To address the challenging setup and evaluation protocol, we propose an effective method that employs a new memory management scheme and novel learning techniques. Our empirical validation demonstrates that the proposed method outperforms prior arts by large margins.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

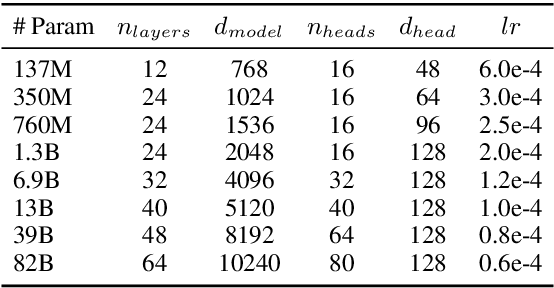
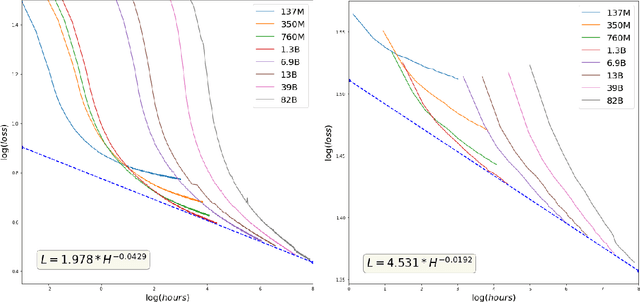
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
Weakly Supervised Pre-Training for Multi-Hop Retriever
Jun 18, 2021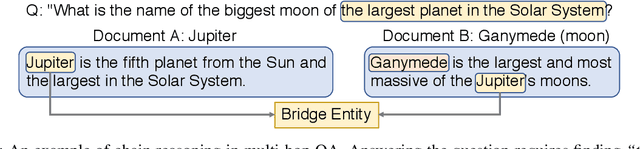


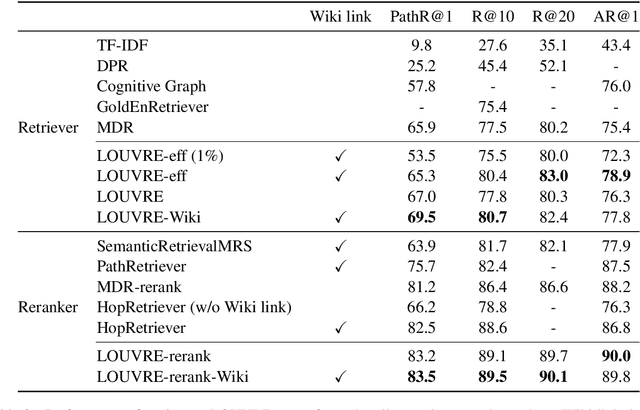
In multi-hop QA, answering complex questions entails iterative document retrieval for finding the missing entity of the question. The main steps of this process are sub-question detection, document retrieval for the sub-question, and generation of a new query for the final document retrieval. However, building a dataset that contains complex questions with sub-questions and their corresponding documents requires costly human annotation. To address the issue, we propose a new method for weakly supervised multi-hop retriever pre-training without human efforts. Our method includes 1) a pre-training task for generating vector representations of complex questions, 2) a scalable data generation method that produces the nested structure of question and sub-question as weak supervision for pre-training, and 3) a pre-training model structure based on dense encoders. We conduct experiments to compare the performance of our pre-trained retriever with several state-of-the-art models on end-to-end multi-hop QA as well as document retrieval. The experimental results show that our pre-trained retriever is effective and also robust on limited data and computational resources.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021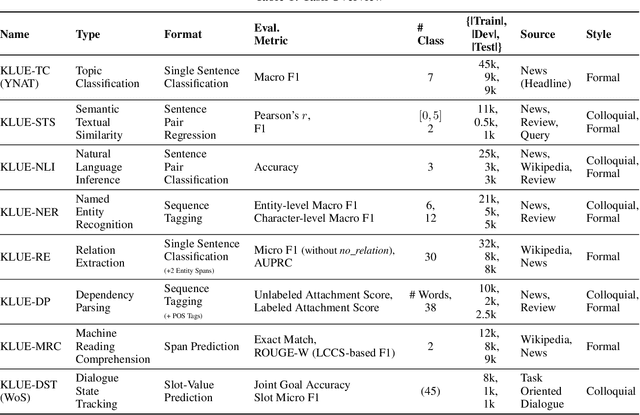
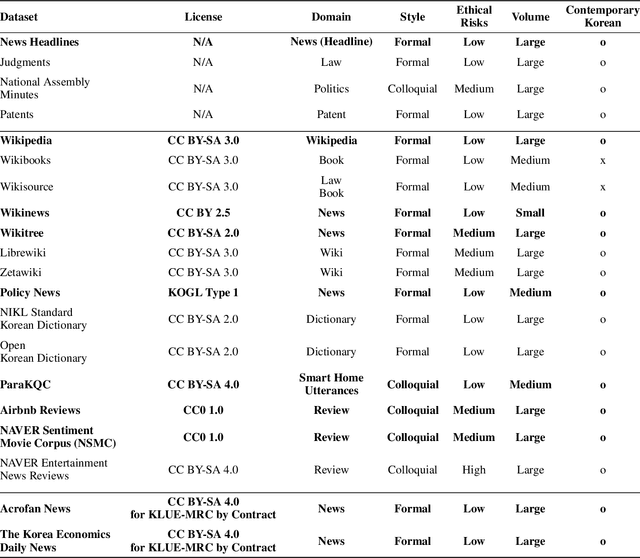
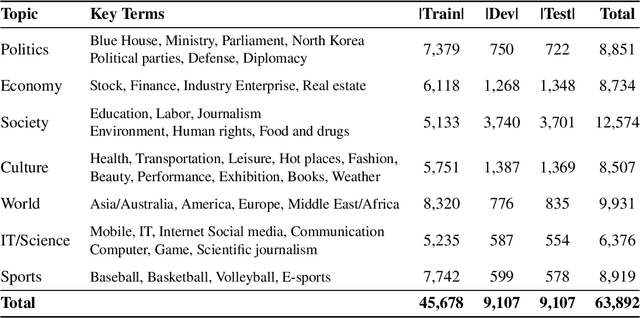
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
Reward Optimization for Neural Machine Translation with Learned Metrics
Apr 15, 2021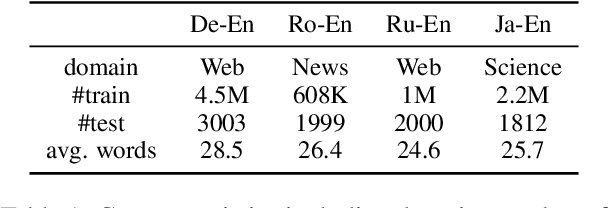
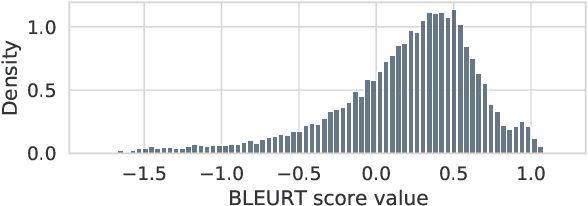
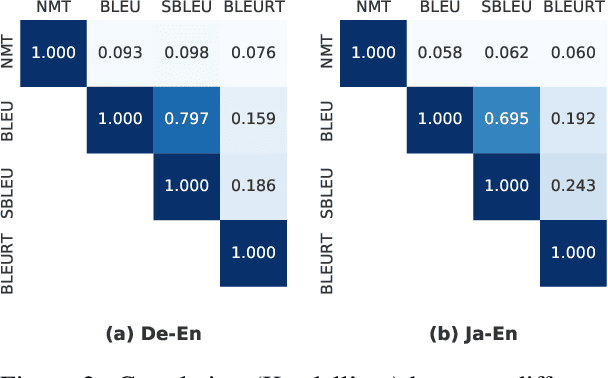

Neural machine translation (NMT) models are conventionally trained with token-level negative log-likelihood (NLL), which does not guarantee that the generated translations will be optimized for a selected sequence-level evaluation metric. Multiple approaches are proposed to train NMT with BLEU as the reward, in order to directly improve the metric. However, it was reported that the gain in BLEU does not translate to real quality improvement, limiting the application in industry. Recently, it became clear to the community that BLEU has a low correlation with human judgment when dealing with state-of-the-art models. This leads to the emerging of model-based evaluation metrics. These new metrics are shown to have a much higher human correlation. In this paper, we investigate whether it is beneficial to optimize NMT models with the state-of-the-art model-based metric, BLEURT. We propose a contrastive-margin loss for fast and stable reward optimization suitable for large NMT models. In experiments, we perform automatic and human evaluations to compare models trained with smoothed BLEU and BLEURT to the baseline models. Results show that the reward optimization with BLEURT is able to increase the metric scores by a large margin, in contrast to limited gain when training with smoothed BLEU. The human evaluation shows that models trained with BLEURT improve adequacy and coverage of translations. Code is available via https://github.com/naver-ai/MetricMT.
Rainbow Memory: Continual Learning with a Memory of Diverse Samples
Mar 31, 2021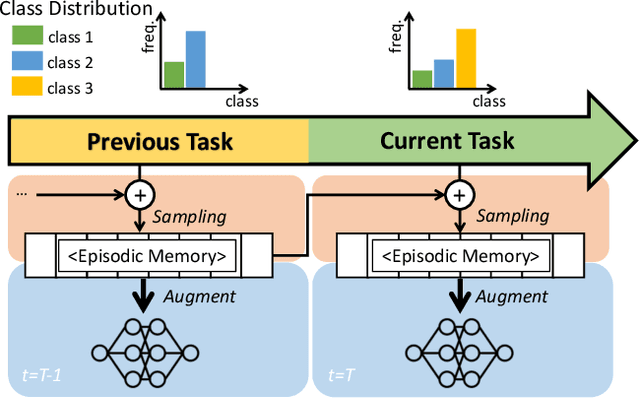
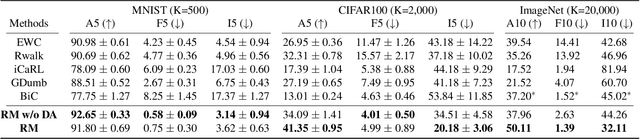
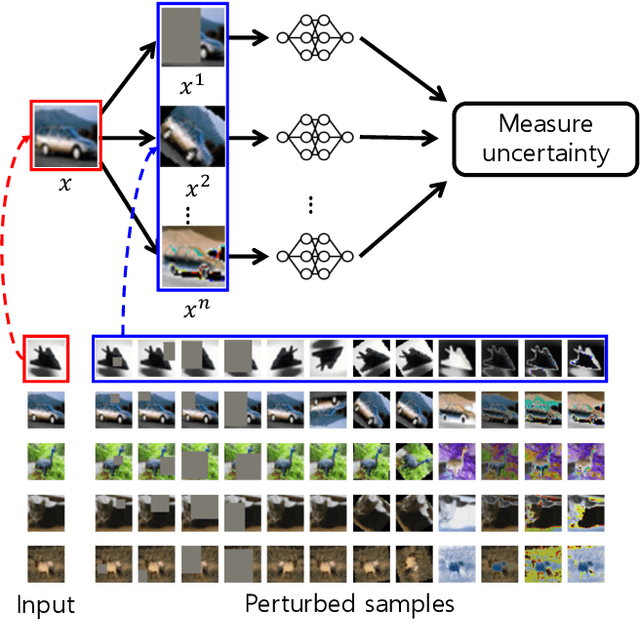
Continual learning is a realistic learning scenario for AI models. Prevalent scenario of continual learning, however, assumes disjoint sets of classes as tasks and is less realistic rather artificial. Instead, we focus on 'blurry' task boundary; where tasks shares classes and is more realistic and practical. To address such task, we argue the importance of diversity of samples in an episodic memory. To enhance the sample diversity in the memory, we propose a novel memory management strategy based on per-sample classification uncertainty and data augmentation, named Rainbow Memory (RM). With extensive empirical validations on MNIST, CIFAR10, CIFAR100, and ImageNet datasets, we show that the proposed method significantly improves the accuracy in blurry continual learning setups, outperforming state of the arts by large margins despite its simplicity. Code and data splits will be available in https://github.com/clovaai/rainbow-memory.
Self-supervised Auxiliary Learning for Graph Neural Networks via Meta-Learning
Mar 01, 2021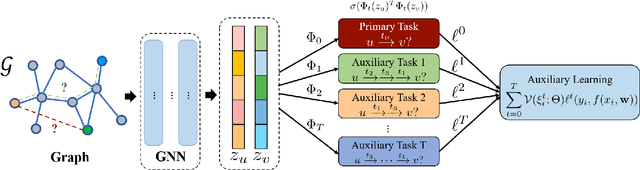
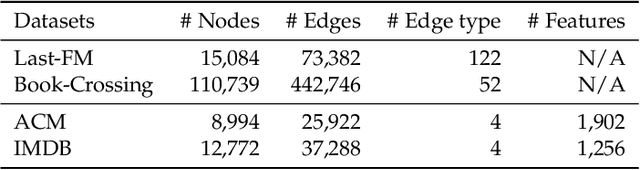
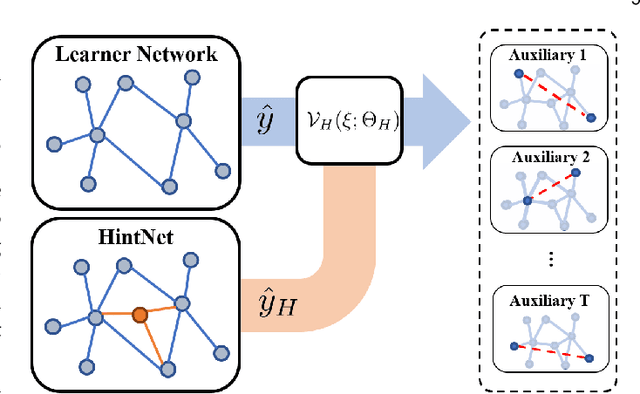
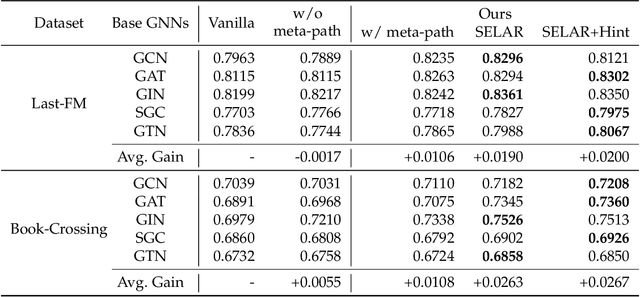
In recent years, graph neural networks (GNNs) have been widely adopted in representation learning of graph-structured data and provided state-of-the-art performance in various application such as link prediction and node classification. Simultaneously, self-supervised learning has been studied to some extent to leverage rich unlabeled data in representation learning on graphs. However, employing self-supervision tasks as auxiliary tasks to assist a primary task has been less explored in the literature on graphs. In this paper, we propose a novel self-supervised auxiliary learning framework to effectively learn graph neural networks. Moreover, we design first a meta-path prediction as a self-supervised auxiliary task for heterogeneous graphs. Our method is learning to learn a primary task with various auxiliary tasks to improve generalization performance. The proposed method identifies an effective combination of auxiliary tasks and automatically balances them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. Also, it can be extended to any other auxiliary tasks. Our experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.