 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine-Scaled Attention: Towards Flexible and Stable Transformer Attention
Feb 26, 2026Transformer attention is typically implemented using softmax normalization, which enforces attention weights with unit sum normalization. While effective in many settings, this constraint can limit flexibility in controlling attention magnitudes and may contribute to overly concentrated or unstable attention patterns during training. Prior work has explored modifications such as attention sinks or gating mechanisms, but these approaches provide only limited or indirect control over attention reweighting. We propose Affine-Scaled Attention, a simple extension to standard attention that introduces input-dependent scaling and a corresponding bias term applied to softmax-normalized attention weights. This design relaxes the strict normalization constraint while maintaining aggregation of value representations, allowing the model to adjust both the relative distribution and the scale of attention in a controlled manner. We empirically evaluate Affine-Scaled Attention in large-scale language model pretraining across multiple model sizes. Experimental results show consistent improvements in training stability, optimization behavior, and downstream task performance compared to standard softmax attention and attention sink baselines. These findings suggest that modest reweighting of attention outputs provides a practical and effective way to improve attention behavior in Transformer models.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
Sep 22, 2022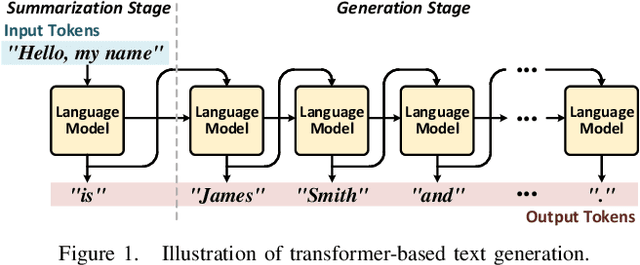
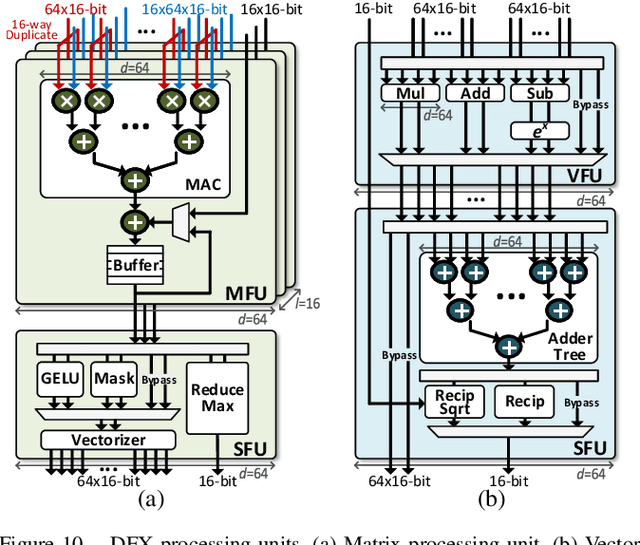
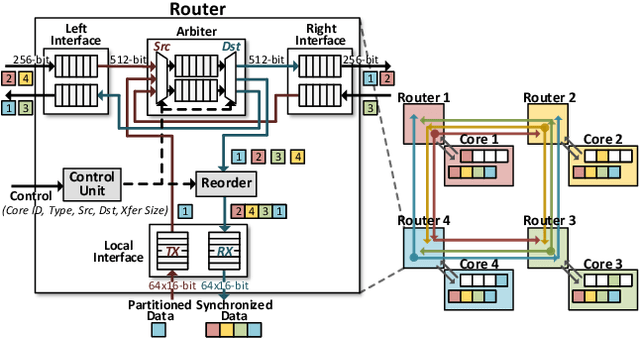
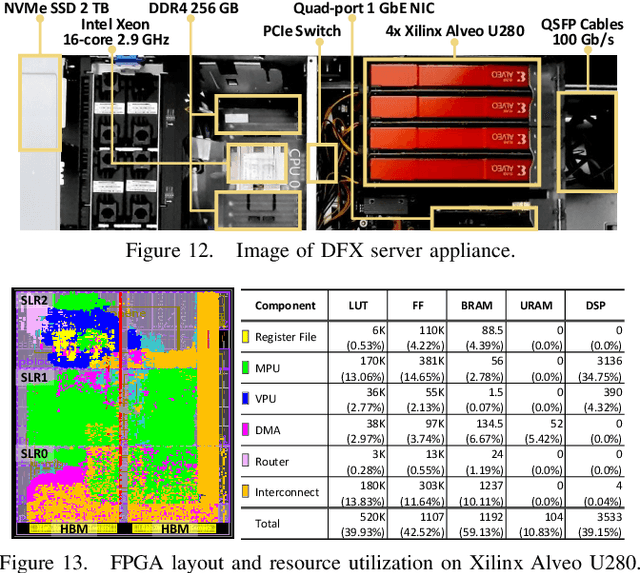
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pre-trained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation. In this paper, we present DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. We implement the proposed hardware architecture on four Xilinx Alveo U280 FPGAs and utilize all of the channels of the high bandwidth memory (HBM) and the maximum number of compute resources for high hardware efficiency. DFX achieves 5.58x speedup and 3.99x energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21x more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

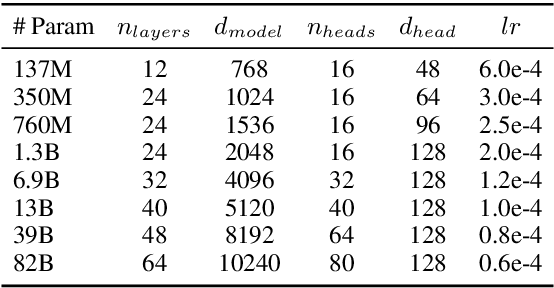
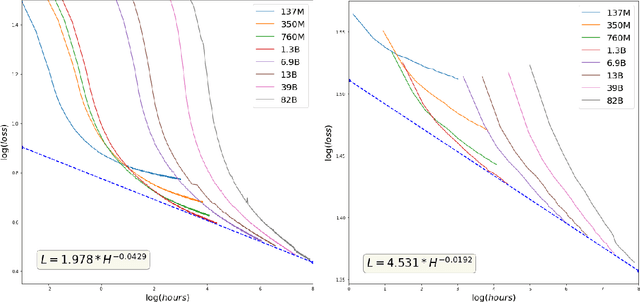
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.