 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefillShare: A Shared Prefill Module for KV Reuse in Multi-LLM Disaggregated Serving
Feb 12, 2026Multi-agent systems increasingly orchestrate multiple specialized language models to solve complex real-world problems, often invoking them over a shared context. This execution pattern repeatedly processes the same prompt prefix across models. Consequently, each model redundantly executes the prefill stage and maintains its own key-value (KV) cache, increasing aggregate prefill load and worsening tail latency by intensifying prefill-decode interference in existing LLM serving stacks. Disaggregated serving reduces such interference by placing prefill and decode on separate GPUs, but disaggregation does not fundamentally eliminate inter-model redundancy in computation and KV storage for the same prompt. To address this issue, we propose PrefillShare, a novel algorithm that enables sharing the prefill stage across multiple models in a disaggregated setting. PrefillShare factorizes the model into prefill and decode modules, freezes the prefill module, and fine-tunes only the decode module. This design allows multiple task-specific models to share a prefill module and the KV cache generated for the same prompt. We further introduce a routing mechanism that enables effective prefill sharing across heterogeneous models in a vLLM-based disaggregated system. PrefillShare not only matches full fine-tuning accuracy on a broad range of tasks and models, but also delivers 4.5x lower p95 latency and 3.9x higher throughput in multi-model agent workloads.
Physically Guided Visual Mass Estimation from a Single RGB Image
Jan 28, 2026Estimating object mass from visual input is challenging because mass depends jointly on geometric volume and material-dependent density, neither of which is directly observable from RGB appearance. Consequently, mass prediction from pixels is ill-posed and therefore benefits from physically meaningful representations to constrain the space of plausible solutions. We propose a physically structured framework for single-image mass estimation that addresses this ambiguity by aligning visual cues with the physical factors governing mass. From a single RGB image, we recover object-centric three-dimensional geometry via monocular depth estimation to inform volume and extract coarse material semantics using a vision-language model to guide density-related reasoning. These geometry, semantic, and appearance representations are fused through an instance-adaptive gating mechanism, and two physically guided latent factors (volume- and density-related) are predicted through separate regression heads under mass-only supervision. Experiments on image2mass and ABO-500 show that the proposed method consistently outperforms state-of-the-art methods.
Subspace-based Approximate Hessian Method for Zeroth-Order Optimization
Jul 08, 2025Zeroth-order optimization addresses problems where gradient information is inaccessible or impractical to compute. While most existing methods rely on first-order approximations, incorporating second-order (curvature) information can, in principle, significantly accelerate convergence. However, the high cost of function evaluations required to estimate Hessian matrices often limits practical applicability. We present the subspace-based approximate Hessian (ZO-SAH) method, a zeroth-order optimization algorithm that mitigates these costs by focusing on randomly selected two-dimensional subspaces. Within each subspace, ZO-SAH estimates the Hessian by fitting a quadratic polynomial to the objective function and extracting its second-order coefficients. To further reduce function-query costs, ZO-SAH employs a periodic subspace-switching strategy that reuses function evaluations across optimization steps. Experiments on eight benchmark datasets, including logistic regression and deep neural network training tasks, demonstrate that ZO-SAH achieves significantly faster convergence than existing zeroth-order methods.
Self-Training Large Language Models with Confident Reasoning
May 23, 2025Large language models (LLMs) have shown impressive performance by generating reasoning paths before final answers, but learning such a reasoning path requires costly human supervision. To address this issue, recent studies have explored self-training methods that improve reasoning capabilities using pseudo-labels generated by the LLMs themselves. Among these, confidence-based self-training fine-tunes LLMs to prefer reasoning paths with high-confidence answers, where confidence is estimated via majority voting. However, such methods exclusively focus on the quality of the final answer and may ignore the quality of the reasoning paths, as even an incorrect reasoning path leads to a correct answer by chance. Instead, we advocate the use of reasoning-level confidence to identify high-quality reasoning paths for self-training, supported by our empirical observations. We then propose a new self-training method, CORE-PO, that fine-tunes LLMs to prefer high-COnfidence REasoning paths through Policy Optimization. Our experiments show that CORE-PO improves the accuracy of outputs on four in-distribution and two out-of-distribution benchmarks, compared to existing self-training methods.
GraspCorrect: Robotic Grasp Correction via Vision-Language Model-Guided Feedback
Mar 19, 2025Despite significant advancements in robotic manipulation, achieving consistent and stable grasping remains a fundamental challenge, often limiting the successful execution of complex tasks. Our analysis reveals that even state-of-the-art policy models frequently exhibit unstable grasping behaviors, leading to failure cases that create bottlenecks in real-world robotic applications. To address these challenges, we introduce GraspCorrect, a plug-and-play module designed to enhance grasp performance through vision-language model-guided feedback. GraspCorrect employs an iterative visual question-answering framework with two key components: grasp-guided prompting, which incorporates task-specific constraints, and object-aware sampling, which ensures the selection of physically feasible grasp candidates. By iteratively generating intermediate visual goals and translating them into joint-level actions, GraspCorrect significantly improves grasp stability and consistently enhances task success rates across existing policy models in the RLBench and CALVIN datasets.
VisEscape: A Benchmark for Evaluating Exploration-driven Decision-making in Virtual Escape Rooms
Mar 18, 2025Escape rooms present a unique cognitive challenge that demands exploration-driven planning: players should actively search their environment, continuously update their knowledge based on new discoveries, and connect disparate clues to determine which elements are relevant to their objectives. Motivated by this, we introduce VisEscape, a benchmark of 20 virtual escape rooms specifically designed to evaluate AI models under these challenging conditions, where success depends not only on solving isolated puzzles but also on iteratively constructing and refining spatial-temporal knowledge of a dynamically changing environment. On VisEscape, we observed that even state-of-the-art multimodal models generally fail to escape the rooms, showing considerable variation in their levels of progress and trajectories. To address this issue, we propose VisEscaper, which effectively integrates Memory, Feedback, and ReAct modules, demonstrating significant improvements by performing 3.7 times more effectively and 5.0 times more efficiently on average.
Semantic Exploration with Adaptive Gating for Efficient Problem Solving with Language Models
Jan 10, 2025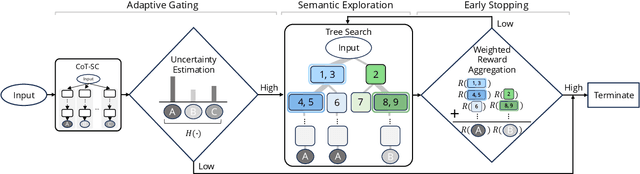
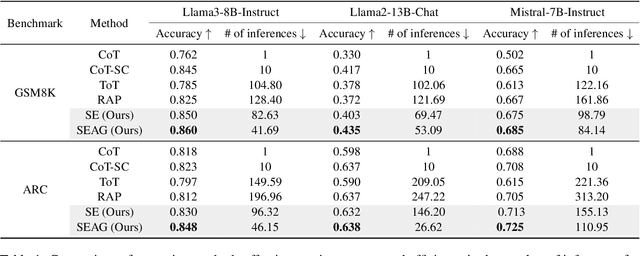
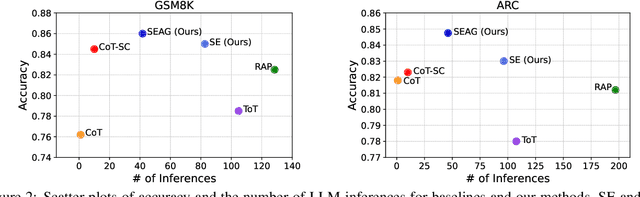
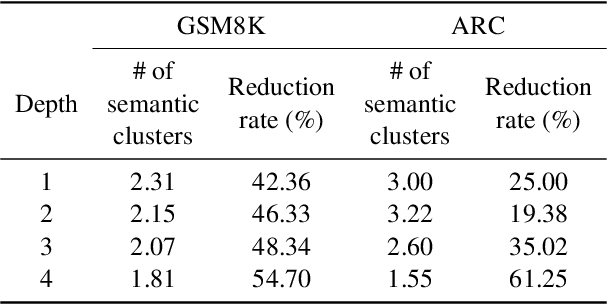
Recent advancements in large language models (LLMs) have shown remarkable potential in various complex tasks requiring multi-step reasoning methods like tree search to explore diverse reasoning paths. However, existing methods often suffer from computational inefficiency and redundancy. First, they overlook the diversity of task difficulties, leading to unnecessarily extensive searches even for easy tasks. Second, they neglect the semantics of reasoning paths, resulting in redundant exploration of semantically identical paths. To address these limitations, we propose Semantic Exploration with Adaptive Gating (SEAG), a computationally efficient method. SEAG employs an adaptive gating mechanism that dynamically decides whether to conduct a tree search, based on the confidence level of answers from a preceding simple reasoning method. Furthermore, its tree-based exploration consolidates semantically identical reasoning steps, reducing redundant explorations while maintaining or even improving accuracy. Our extensive experiments demonstrate that SEAG significantly improves accuracy by 4.3% on average while requiring only 31% of computational costs compared to existing tree search-based methods on complex reasoning benchmarks including GSM8K and ARC with diverse language models such as Llama2, Llama3, and Mistral.
Piece of Table: A Divide-and-Conquer Approach for Selecting Sub-Tables in Table Question Answering
Dec 10, 2024Applying language models (LMs) to tables is challenging due to the inherent structural differences between two-dimensional tables and one-dimensional text for which the LMs were originally designed. Furthermore, when applying linearized tables to LMs, the maximum token lengths often imposed in self-attention calculations make it difficult to comprehensively understand the context spread across large tables. To address these challenges, we present PieTa (Piece of Table), a new framework for sub-table-based question answering (QA). PieTa operates through an iterative process of dividing tables into smaller windows, using LMs to select relevant cells within each window, and merging these cells into a sub-table. This multi-resolution approach captures dependencies across multiple rows and columns while avoiding the limitations caused by long context inputs. Instantiated as a simple iterative sub-table union algorithm, PieTa demonstrates improved performance over previous sub-table-based QA approaches.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024



Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.
Selective Vision is the Challenge for Visual Reasoning: A Benchmark for Visual Argument Understanding
Jun 27, 2024



Visual arguments, often used in advertising or social causes, rely on images to persuade viewers to do or believe something. Understanding these arguments requires selective vision: only specific visual stimuli within an image are relevant to the argument, and relevance can only be understood within the context of a broader argumentative structure. While visual arguments are readily appreciated by human audiences, we ask: are today's AI capable of similar understanding? We collect and release VisArgs, an annotated corpus designed to make explicit the (usually implicit) structures underlying visual arguments. VisArgs includes 1,611 images accompanied by three types of textual annotations: 5,112 visual premises (with region annotations), 5,574 commonsense premises, and reasoning trees connecting them to a broader argument. We propose three tasks over VisArgs to probe machine capacity for visual argument understanding: localization of premises, identification of premises, and deduction of conclusions. Experiments demonstrate that 1) machines cannot fully identify the relevant visual cues. The top-performing model, GPT-4-O, achieved an accuracy of only 78.5%, whereas humans reached 98.0%. All models showed a performance drop, with an average decrease in accuracy of 19.5%, when the comparison set was changed from objects outside the image to irrelevant objects within the image. Furthermore, 2) this limitation is the greatest factor impacting their performance in understanding visual arguments. Most models improved the most when given relevant visual premises as additional inputs, compared to other inputs, for deducing the conclusion of the visual argument.