 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSAI: Unbiased and Interpretable Latent Feature Extraction for Data-Centric AI
Dec 09, 2024



Large language models (LLMs) often struggle to objectively identify latent characteristics in large datasets due to their reliance on pre-trained knowledge rather than actual data patterns. To address this data grounding issue, we propose Data Scientist AI (DSAI), a framework that enables unbiased and interpretable feature extraction through a multi-stage pipeline with quantifiable prominence metrics for evaluating extracted features. On synthetic datasets with known ground-truth features, DSAI demonstrates high recall in identifying expert-defined features while faithfully reflecting the underlying data. Applications on real-world datasets illustrate the framework's practical utility in uncovering meaningful patterns with minimal expert oversight, supporting use cases such as interpretable classification. The title of our paper is chosen from multiple candidates based on DSAI-generated criteria.
Navigating the Path of Writing: Outline-guided Text Generation with Large Language Models
Apr 22, 2024



Large Language Models (LLMs) have significantly impacted the writing process, enabling collaborative content creation and enhancing productivity. However, generating high-quality, user-aligned text remains challenging. In this paper, we propose Writing Path, a framework that uses explicit outlines to guide LLMs in generating goal-oriented, high-quality pieces of writing. Our approach draws inspiration from structured writing planning and reasoning paths, focusing on capturing and reflecting user intentions throughout the writing process. We construct a diverse dataset from unstructured blog posts to benchmark writing performance and introduce a comprehensive evaluation framework assessing the quality of outlines and generated texts. Our evaluations with GPT-3.5-turbo, GPT-4, and HyperCLOVA X demonstrate that the Writing Path approach significantly enhances text quality according to both LLMs and human evaluations. This study highlights the potential of integrating writing-specific techniques into LLMs to enhance their ability to meet the diverse writing needs of users.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
TeSS: Zero-Shot Classification via Textual Similarity Comparison with Prompting using Sentence Encoder
Dec 20, 2022
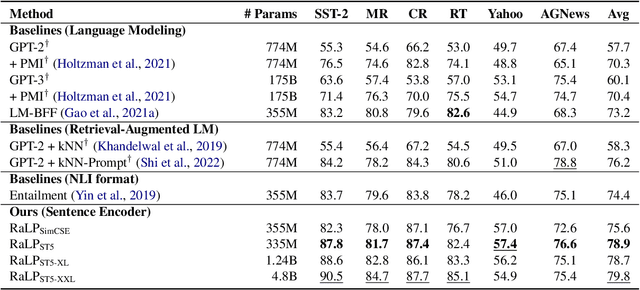


We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

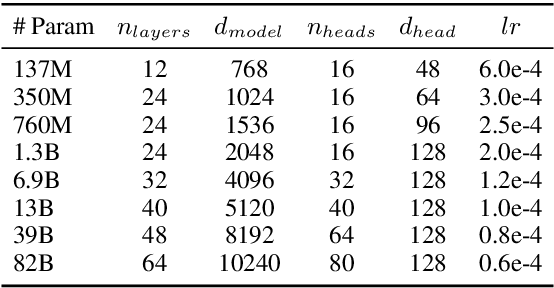
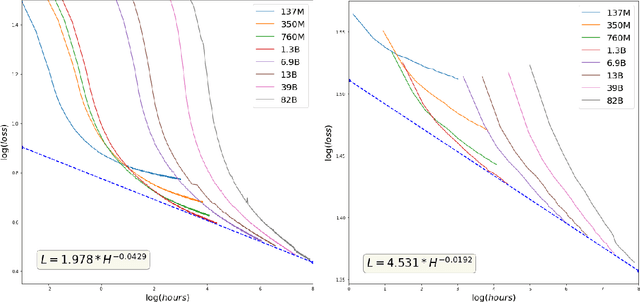
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation
Apr 18, 2021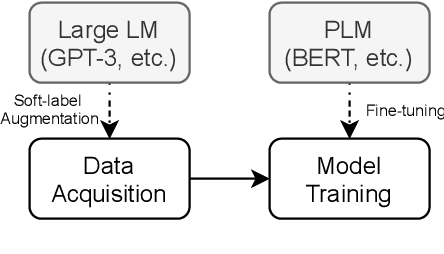
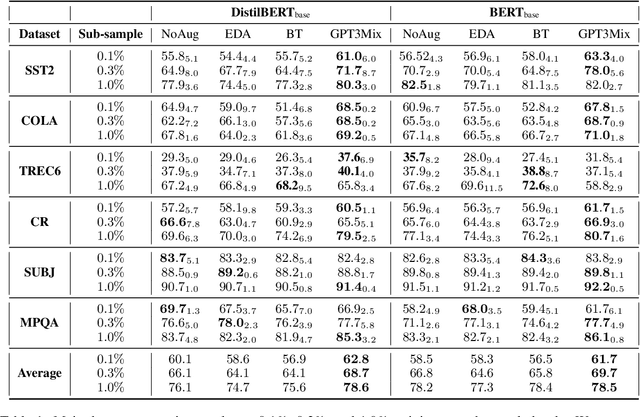
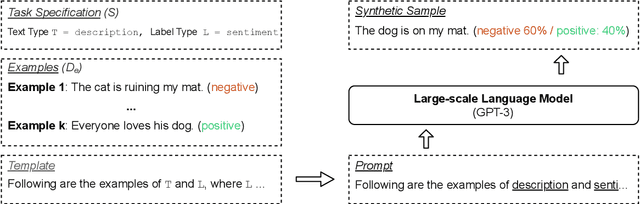
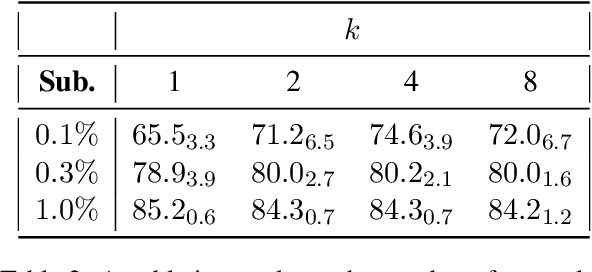
Large-scale language models such as GPT-3 are excellent few-shot learners, allowing them to be controlled via natural text prompts. Recent studies report that prompt-based direct classification eliminates the need for fine-tuning but lacks data and inference scalability. This paper proposes a novel data augmentation technique that leverages large-scale language models to generate realistic text samples from a mixture of real samples. We also propose utilizing soft-labels predicted by the language models, effectively distilling knowledge from the large-scale language models and creating textual perturbations simultaneously. We perform data augmentation experiments on diverse classification tasks and show that our method hugely outperforms existing text augmentation methods. Ablation studies and a qualitative analysis provide more insights into our approach.