 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUE: Pretrained Model and Dataset for Understanding Hanja Documents of Ancient Korea
Oct 11, 2022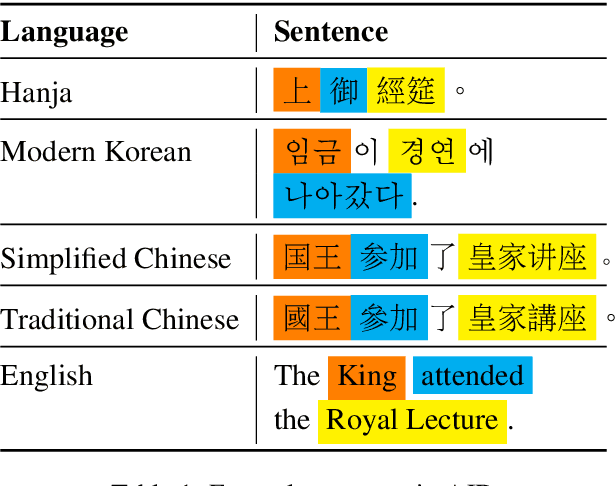
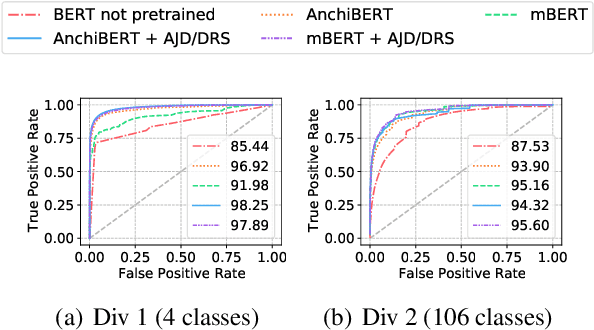

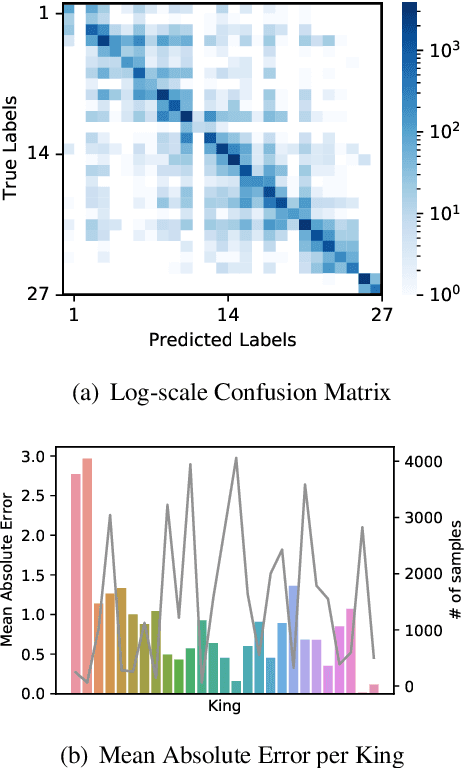
Historical records in Korea before the 20th century were primarily written in Hanja, an extinct language based on Chinese characters and not understood by modern Korean or Chinese speakers. Historians with expertise in this time period have been analyzing the documents, but that process is very difficult and time-consuming, and language models would significantly speed up the process. Toward building and evaluating language models for Hanja, we release the Hanja Understanding Evaluation dataset consisting of chronological attribution, topic classification, named entity recognition, and summary retrieval tasks. We also present BERT-based models continued training on the two major corpora from the 14th to the 19th centuries: the Annals of the Joseon Dynasty and Diaries of the Royal Secretariats. We compare the models with several baselines on all tasks and show there are significant improvements gained by training on the two corpora. Additionally, we run zero-shot experiments on the Daily Records of the Royal Court and Important Officials (DRRI). The DRRI dataset has not been studied much by the historians, and not at all by the NLP community.
Translating Hanja historical documents to understandable Korean and English
May 20, 2022
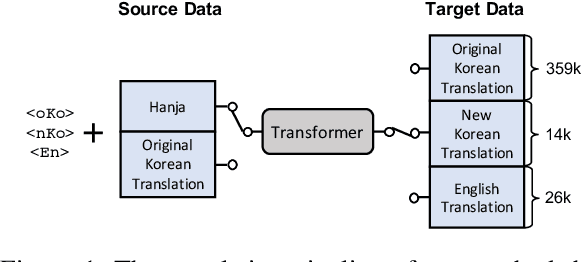
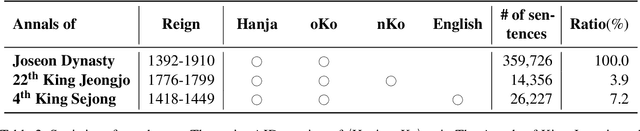
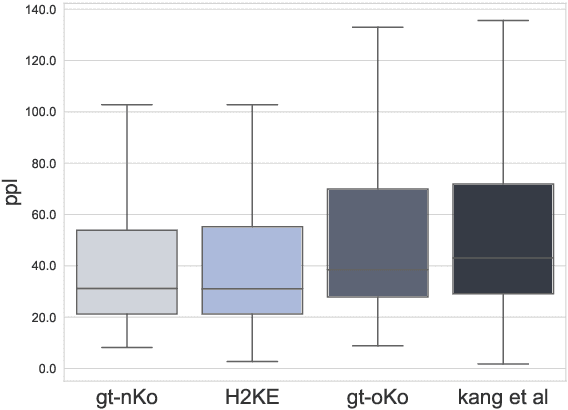
The Annals of Joseon Dynasty (AJD) contain the daily records of the Kings of Joseon, the 500-year kingdom preceding the modern nation of Korea. The Annals were originally written in an archaic Korean writing system, `Hanja', and translated into Korean from 1968 to 1993. However, this translation was literal and contained many archaic Korean words; thus, a new expert translation effort began in 2012, completing the records of only one king in a decade. Also, expert translators are working on an English translation, of which only one king's records are available because of the high cost and slow progress. Thus, we propose H2KE, the neural machine translation model that translates Hanja historical documents to understandable Korean and English. Based on the multilingual neural machine translation approach, it translates the historical document written in Hanja, using both the full dataset of outdated Korean translation and a small dataset of recently translated Korean and English. We compare our method with two baselines: one is a recent model that simultaneously learns to restore and translate Hanja historical document and the other is the transformer that trained on newly translated corpora only. The results show that our method significantly outperforms the baselines in terms of BLEU score in both modern Korean and English translations. We also conduct a human evaluation that shows that our translation is preferred over the original expert translation.
Two-Step Question Retrieval for Open-Domain QA
May 19, 2022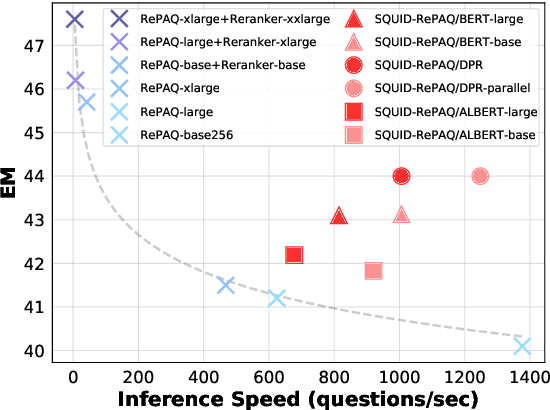
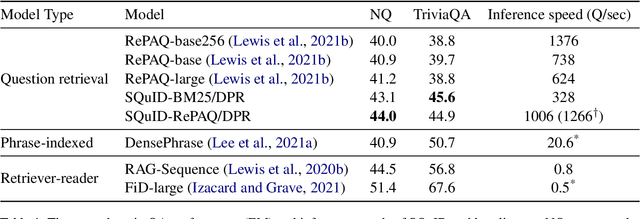
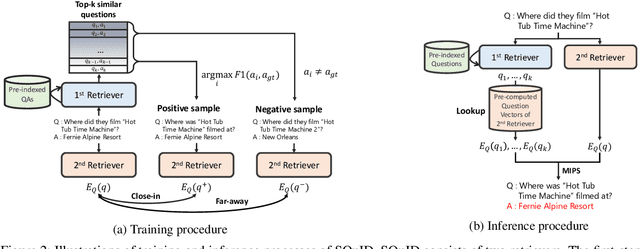
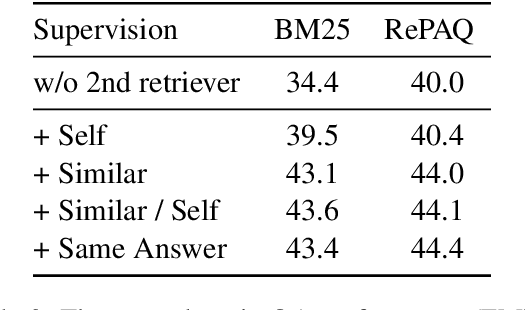
The retriever-reader pipeline has shown promising performance in open-domain QA but suffers from a very slow inference speed. Recently proposed question retrieval models tackle this problem by indexing question-answer pairs and searching for similar questions. These models have shown a significant increase in inference speed, but at the cost of lower QA performance compared to the retriever-reader models. This paper proposes a two-step question retrieval model, SQuID (Sequential Question-Indexed Dense retrieval) and distant supervision for training. SQuID uses two bi-encoders for question retrieval. The first-step retriever selects top-k similar questions, and the second-step retriever finds the most similar question from the top-k questions. We evaluate the performance and the computational efficiency of SQuID. The results show that SQuID significantly increases the performance of existing question retrieval models with a negligible loss on inference speed.
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Jun 11, 2021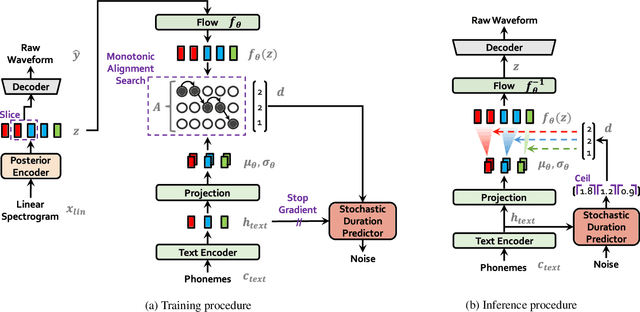
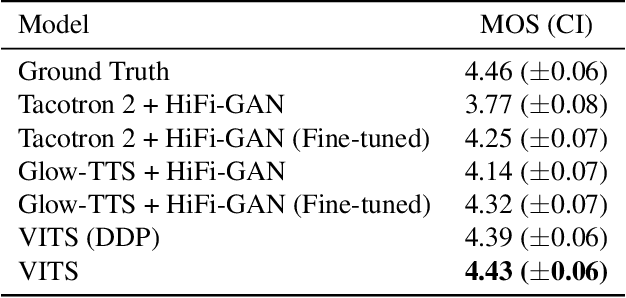

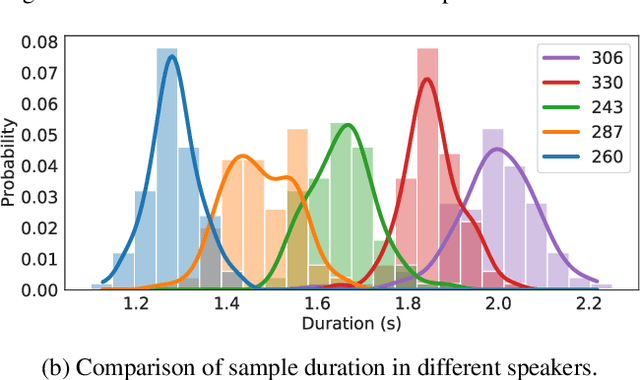
Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In this work, we present a parallel end-to-end TTS method that generates more natural sounding audio than current two-stage models. Our method adopts variational inference augmented with normalizing flows and an adversarial training process, which improves the expressive power of generative modeling. We also propose a stochastic duration predictor to synthesize speech with diverse rhythms from input text. With the uncertainty modeling over latent variables and the stochastic duration predictor, our method expresses the natural one-to-many relationship in which a text input can be spoken in multiple ways with different pitches and rhythms. A subjective human evaluation (mean opinion score, or MOS) on the LJ Speech, a single speaker dataset, shows that our method outperforms the best publicly available TTS systems and achieves a MOS comparable to ground truth.