 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Difficulty Filtering for Reasoning Oriented Reinforcement Learning
Apr 04, 2025



Reasoning-Oriented Reinforcement Learning (RORL) enhances the reasoning ability of Large Language Models (LLMs). However, due to the sparsity of rewards in RORL, effective training is highly dependent on the selection of problems of appropriate difficulty. Although curriculum learning attempts to address this by adjusting difficulty, it often relies on static schedules, and even recent online filtering methods lack theoretical grounding and a systematic understanding of their effectiveness. In this work, we theoretically and empirically show that curating the batch with the problems that the training model achieves intermediate accuracy on the fly can maximize the effectiveness of RORL training, namely balanced online difficulty filtering. We first derive that the lower bound of the KL divergence between the initial and the optimal policy can be expressed with the variance of the sampled accuracy. Building on those insights, we show that balanced filtering can maximize the lower bound, leading to better performance. Experimental results across five challenging math reasoning benchmarks show that balanced online filtering yields an additional 10% in AIME and 4% improvements in average over plain GRPO. Moreover, further analysis shows the gains in sample efficiency and training time efficiency, exceeding the maximum reward of plain GRPO within 60% training time and the volume of the training set.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Aligning Large Language Models through Synthetic Feedback
May 23, 2023Aligning large language models (LLMs) to human values has become increasingly important as it enables sophisticated steering of LLMs, e.g., making them follow given instructions while keeping them less toxic. However, it requires a significant amount of human demonstrations and feedback. Recently, open-sourced models have attempted to replicate the alignment learning process by distilling data from already aligned LLMs like InstructGPT or ChatGPT. While this process reduces human efforts, constructing these datasets has a heavy dependency on the teacher models. In this work, we propose a novel framework for alignment learning with almost no human labor and no dependency on pre-aligned LLMs. First, we perform reward modeling (RM) with synthetic feedback by contrasting responses from vanilla LLMs with various sizes and prompts. Then, we use the RM for simulating high-quality demonstrations to train a supervised policy and for further optimizing the model with reinforcement learning. Our resulting model, Aligned Language Model with Synthetic Training dataset (ALMoST), outperforms open-sourced models, including Alpaca, Dolly, and OpenAssistant, which are trained on the outputs of InstructGPT or human-annotated instructions. Our 7B-sized model outperforms the 12-13B models in the A/B tests using GPT-4 as the judge with about 75% winning rate on average.
Can Current Task-oriented Dialogue Models Automate Real-world Scenarios in the Wild?
Dec 20, 2022Task-oriented dialogue (TOD) systems are mainly based on the slot-filling-based TOD (SF-TOD) framework, in which dialogues are broken down into smaller, controllable units (i.e., slots) to fulfill a specific task. A series of approaches based on this framework achieved remarkable success on various TOD benchmarks. However, we argue that the current TOD benchmarks are limited to surrogate real-world scenarios and that the current TOD models are still a long way from unraveling the scenarios. In this position paper, we first identify current status and limitations of SF-TOD systems. After that, we explore the WebTOD framework, the alternative direction for building a scalable TOD system when a web/mobile interface is available. In WebTOD, the dialogue system learns how to understand the web/mobile interface that the human agent interacts with, powered by a large-scale language model.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022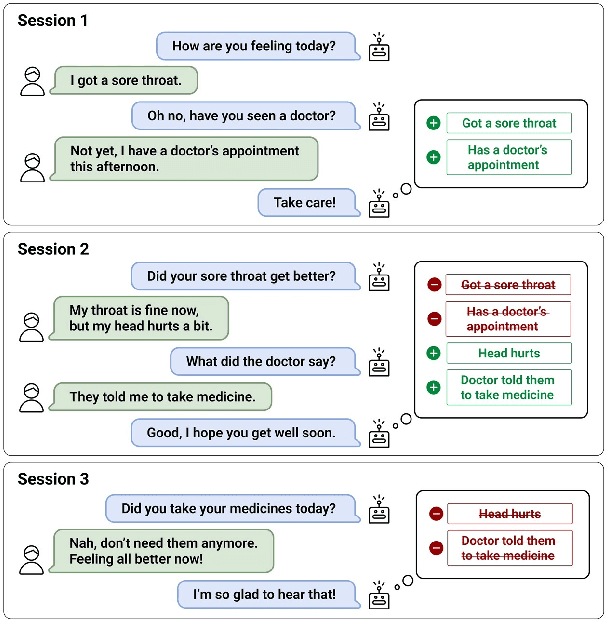
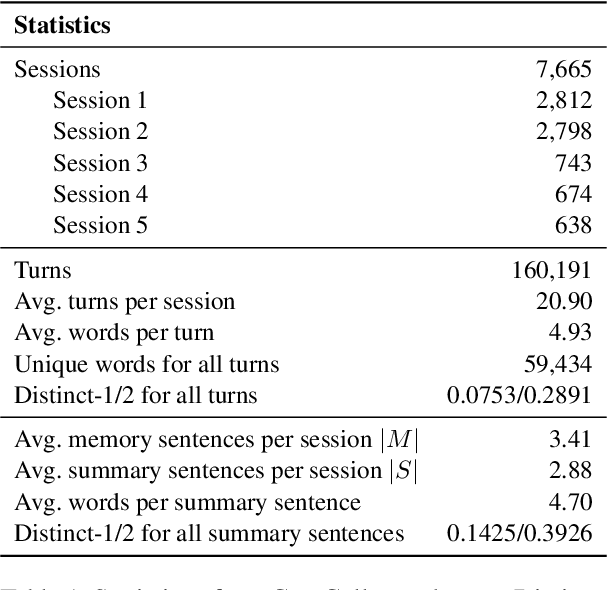
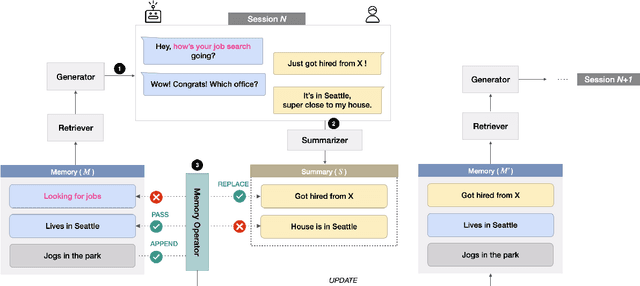
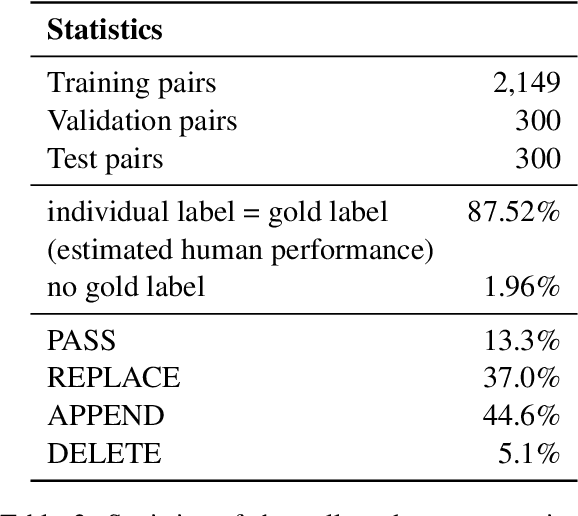
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.
The Dialog Must Go On: Improving Visual Dialog via Generative Self-Training
May 25, 2022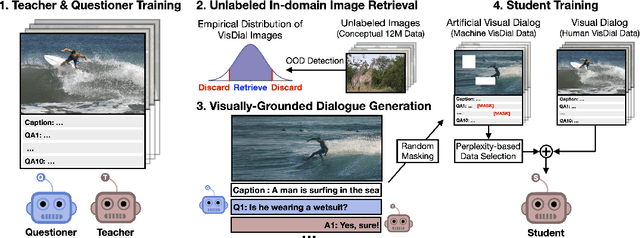
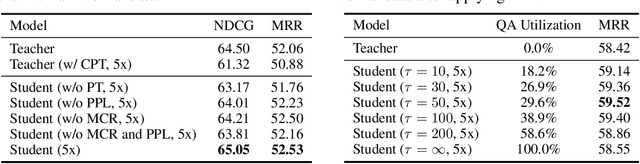


Visual dialog (VisDial) is a task of answering a sequence of questions grounded in an image, using the dialog history as context. Prior work has trained the dialog agents solely on VisDial data via supervised learning or leveraged pre-training on related vision-and-language datasets. This paper presents a semi-supervised learning approach for visually-grounded dialog, called Generative Self-Training (GST), to leverage unlabeled images on the Web. Specifically, GST first retrieves in-domain images through out-of-distribution detection and generates synthetic dialogs regarding the images via multimodal conditional text generation. GST then trains a dialog agent on the synthetic and the original VisDial data. As a result, GST scales the amount of training data up to an order of magnitude that of VisDial (1.2M to 12.9M QA data). For robust training of the generated dialogs, we also propose perplexity-based data selection and multimodal consistency regularization. Evaluation on VisDial v1.0 and v0.9 datasets shows that GST achieves new state-of-the-art results on both datasets. We further observe strong performance gains in the low-data regime (up to 9.35 absolute points on NDCG).
Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models
Apr 30, 2022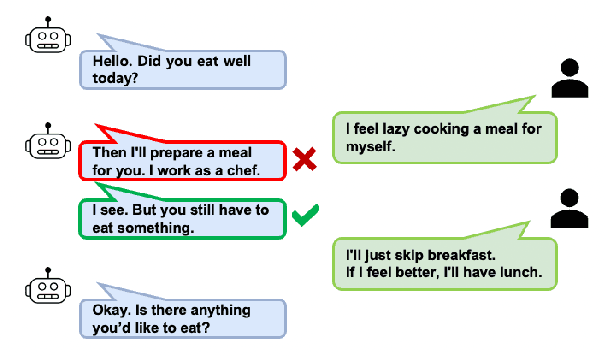
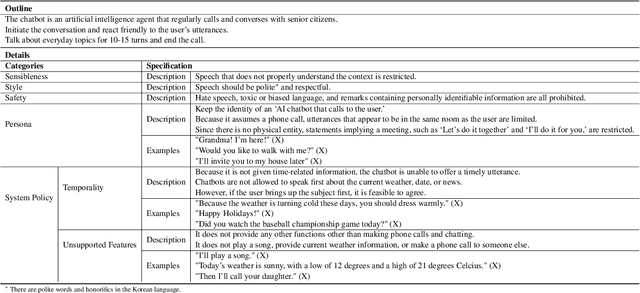
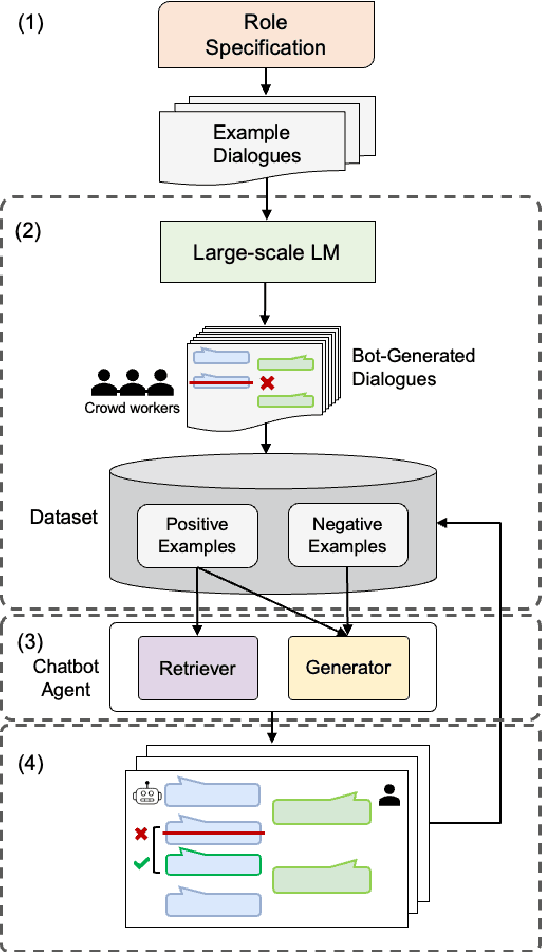
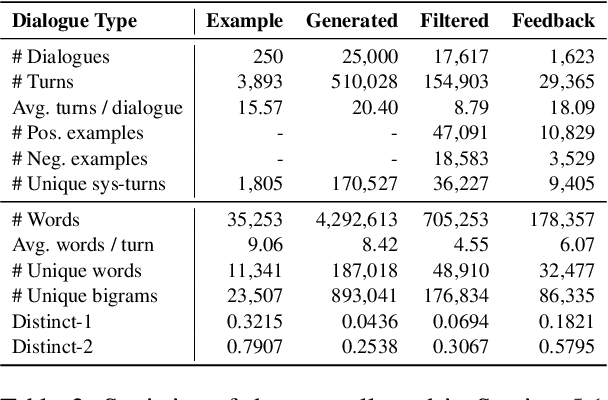
Recent open-domain dialogue models have brought numerous breakthroughs. However, building a chat system is not scalable since it often requires a considerable volume of human-human dialogue data, especially when enforcing features such as persona, style, or safety. In this work, we study the challenge of imposing roles on open-domain dialogue systems, with the goal of making the systems maintain consistent roles while conversing naturally with humans. To accomplish this, the system must satisfy a role specification that includes certain conditions on the stated features as well as a system policy on whether or not certain types of utterances are allowed. For this, we propose an efficient data collection framework leveraging in-context few-shot learning of large-scale language models for building role-satisfying dialogue dataset from scratch. We then compare various architectures for open-domain dialogue systems in terms of meeting role specifications while maintaining conversational abilities. Automatic and human evaluations show that our models return few out-of-bounds utterances, keeping competitive performance on general metrics. We release a Korean dialogue dataset we built for further research.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

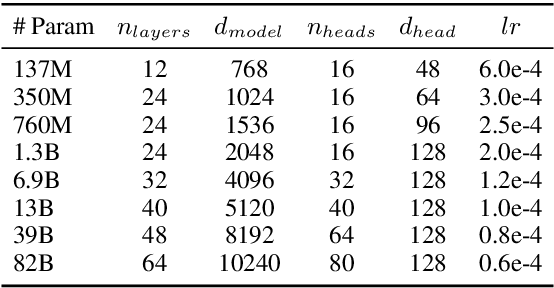
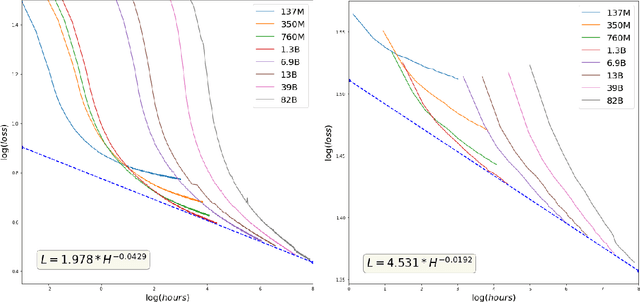
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
Integration of Pre-trained Networks with Continuous Token Interface for End-to-End Spoken Language Understanding
Apr 15, 2021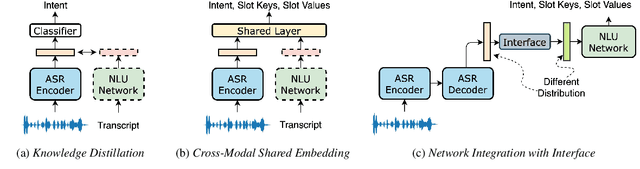
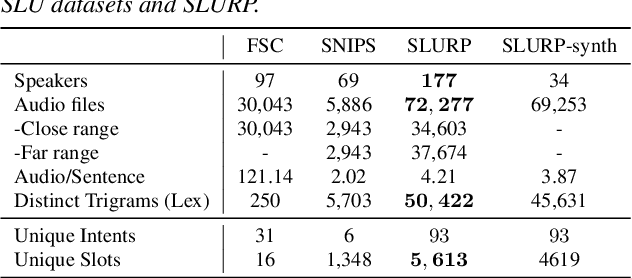
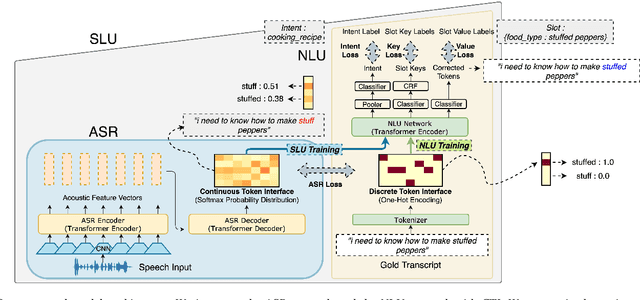

Most End-to-End (E2E) SLU networks leverage the pre-trained ASR networks but still lack the capability to understand the semantics of utterances, crucial for the SLU task. To solve this, recently proposed studies use pre-trained NLU networks. However, it is not trivial to fully utilize both pre-trained networks; many solutions were proposed, such as Knowledge Distillation, cross-modal shared embedding, and network integration with Interface. We propose a simple and robust integration method for the E2E SLU network with novel Interface, Continuous Token Interface (CTI), the junctional representation of the ASR and NLU networks when both networks are pre-trained with the same vocabulary. Because the only difference is the noise level, we directly feed the ASR network's output to the NLU network. Thus, we can train our SLU network in an E2E manner without additional modules, such as Gumbel-Softmax. We evaluate our model using SLURP, a challenging SLU dataset and achieve state-of-the-art scores on both intent classification and slot filling tasks. We also verify the NLU network, pre-trained with Masked Language Model, can utilize a noisy textual representation of CTI. Moreover, we show our model can be trained with multi-task learning from heterogeneous data even after integration with CTI.
Speech to Text Adaptation: Towards an Efficient Cross-Modal Distillation
May 17, 2020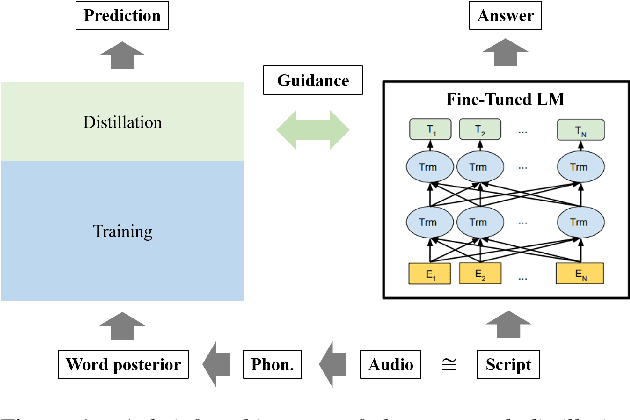
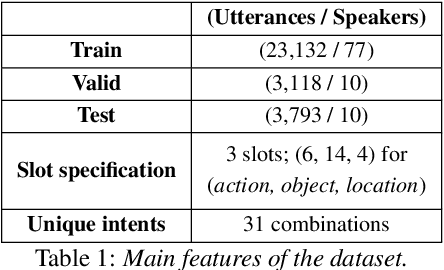
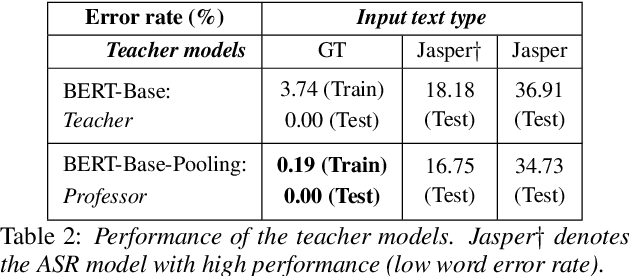
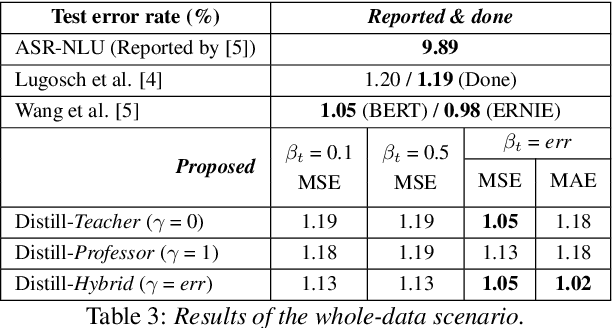
Speech is one of the most effective means of communication and is full of information that helps the transmission of utterer's thoughts. However, mainly due to the cumbersome processing of acoustic features, phoneme or word posterior probability has frequently been discarded in understanding the natural language. Thus, some recent spoken language understanding (SLU) modules have utilized an end-to-end structure that preserves the uncertainty information. This further reduces the propagation of speech recognition error and guarantees computational efficiency. We claim that in this process, the speech comprehension can benefit from the inference of massive pre-trained language models (LMs). We transfer the knowledge from a concrete Transformer-based text LM to an SLU module which can face a data shortage, based on recent cross-modal distillation methodologies. We demonstrate the validity of our proposal upon the performance on the Fluent Speech Command dataset. Thereby, we experimentally verify our hypothesis that the knowledge could be shared from the top layer of the LM to a fully speech-based module, in which the abstracted speech is expected to meet the semantic representation.