 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
May 29, 2025Transformer-based large language models (LLMs) cache context as key-value (KV) pairs during inference. As context length grows, KV cache sizes expand, leading to substantial memory overhead and increased attention latency. This paper introduces KVzip, a query-agnostic KV cache eviction method enabling effective reuse of compressed KV caches across diverse queries. KVzip quantifies the importance of a KV pair using the underlying LLM to reconstruct original contexts from cached KV pairs, subsequently evicting pairs with lower importance. Extensive empirical evaluations demonstrate that KVzip reduces KV cache size by 3-4$\times$ and FlashAttention decoding latency by approximately 2$\times$, with negligible performance loss in question-answering, retrieval, reasoning, and code comprehension tasks. Evaluations include various models such as LLaMA3.1-8B, Qwen2.5-14B, and Gemma3-12B, with context lengths reaching up to 170K tokens. KVzip significantly outperforms existing query-aware KV eviction methods, which suffer from performance degradation even at a 90% cache budget ratio under multi-query scenarios.
GuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
May 11, 2025



Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
Guided Stream of Search: Learning to Better Search with Language Models via Optimal Path Guidance
Oct 03, 2024While language models have demonstrated impressive capabilities across a range of tasks, they still struggle with tasks that require complex planning and reasoning. Recent studies have proposed training language models on search processes rather than optimal solutions, resulting in better generalization performance even though search processes are noisy and even suboptimal. However, these studies overlook the value of optimal solutions, which can serve as step-by-step landmarks to guide more effective search. In this work, we explore how to leverage optimal solutions to enhance the search and planning abilities of language models. To this end, we propose guided stream of search (GSoS), which seamlessly incorporates optimal solutions into the self-generation process in a progressive manner, producing high-quality search trajectories. These trajectories are then distilled into the pre-trained model via supervised fine-tuning. Our approach significantly enhances the search and planning abilities of language models on Countdown, a simple yet challenging mathematical reasoning task. Notably, combining our method with RL fine-tuning yields further improvements, whereas previous supervised fine-tuning methods do not benefit from RL. Furthermore, our approach exhibits greater effectiveness than leveraging optimal solutions in the form of subgoal rewards.
Targeted Cause Discovery with Data-Driven Learning
Aug 29, 2024



We propose a novel machine learning approach for inferring causal variables of a target variable from observations. Our goal is to identify both direct and indirect causes within a system, thereby efficiently regulating the target variable when the difficulty and cost of intervening on each causal variable vary. Our method employs a neural network trained to identify causality through supervised learning on simulated data. By implementing a local-inference strategy, we achieve linear complexity with respect to the number of variables, efficiently scaling up to thousands of variables. Empirical results demonstrate the effectiveness of our method in identifying causal relationships within large-scale gene regulatory networks, outperforming existing causal discovery methods that primarily focus on direct causality. We validate our model's generalization capability across novel graph structures and generating mechanisms, including gene regulatory networks of E. coli and the human K562 cell line. Implementation codes are available at https://github.com/snu-mllab/Targeted-Cause-Discovery.
Training Greedy Policy for Proposal Batch Selection in Expensive Multi-Objective Combinatorial Optimization
Jun 21, 2024



Active learning is increasingly adopted for expensive multi-objective combinatorial optimization problems, but it involves a challenging subset selection problem, optimizing the batch acquisition score that quantifies the goodness of a batch for evaluation. Due to the excessively large search space of the subset selection problem, prior methods optimize the batch acquisition on the latent space, which has discrepancies with the actual space, or optimize individual acquisition scores without considering the dependencies among candidates in a batch instead of directly optimizing the batch acquisition. To manage the vast search space, a simple and effective approach is the greedy method, which decomposes the problem into smaller subproblems, yet it has difficulty in parallelization since each subproblem depends on the outcome from the previous ones. To this end, we introduce a novel greedy-style subset selection algorithm that optimizes batch acquisition directly on the combinatorial space by sequential greedy sampling from the greedy policy, specifically trained to address all greedy subproblems concurrently. Notably, our experiments on the red fluorescent proteins design task show that our proposed method achieves the baseline performance in 1.69x fewer queries, demonstrating its efficiency.
LayerMerge: Neural Network Depth Compression through Layer Pruning and Merging
Jun 18, 2024



Recent works show that reducing the number of layers in a convolutional neural network can enhance efficiency while maintaining the performance of the network. Existing depth compression methods remove redundant non-linear activation functions and merge the consecutive convolution layers into a single layer. However, these methods suffer from a critical drawback; the kernel size of the merged layers becomes larger, significantly undermining the latency reduction gained from reducing the depth of the network. We show that this problem can be addressed by jointly pruning convolution layers and activation functions. To this end, we propose LayerMerge, a novel depth compression method that selects which activation layers and convolution layers to remove, to achieve a desired inference speed-up while minimizing performance loss. Since the corresponding selection problem involves an exponential search space, we formulate a novel surrogate optimization problem and efficiently solve it via dynamic programming. Empirical results demonstrate that our method consistently outperforms existing depth compression and layer pruning methods on various network architectures, both on image classification and generation tasks. We release the code at https://github.com/snu-mllab/LayerMerge.
Compressed Context Memory For Online Language Model Interaction
Dec 06, 2023This paper presents a novel context compression method for Transformer language models in online scenarios such as ChatGPT, where the context continually expands. As the context lengthens, the attention process requires more memory and computational resources, which in turn reduces the throughput of the language model. To this end, we propose a compressed context memory system that continually compresses the growing context into a compact memory space. The compression process simply involves integrating a lightweight conditional LoRA into the language model's forward pass during inference. Based on the compressed context memory, the language model can perform inference with reduced memory and attention operations. Through evaluations on conversation, personalization, and multi-task learning, we demonstrate that our approach achieves the performance level of a full context model with $5\times$ smaller context memory space. Codes are available at https://github.com/snu-mllab/context-memory.
Discovering Hierarchical Achievements in Reinforcement Learning via Contrastive Learning
Jul 07, 2023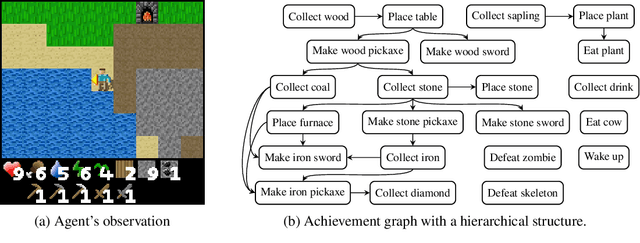
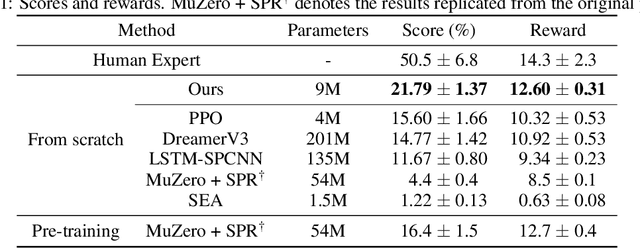
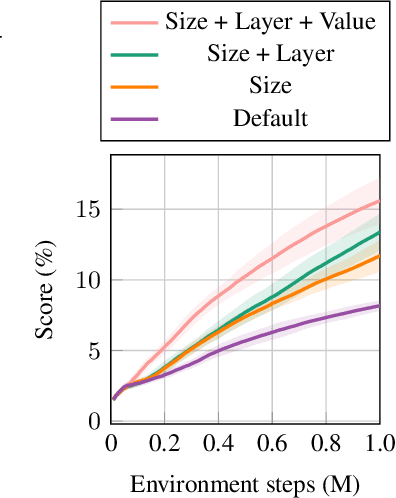
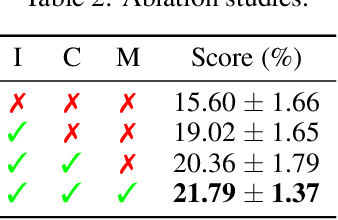
Discovering achievements with a hierarchical structure on procedurally generated environments poses a significant challenge. This requires agents to possess a broad range of abilities, including generalization and long-term reasoning. Many prior methods are built upon model-based or hierarchical approaches, with the belief that an explicit module for long-term planning would be beneficial for learning hierarchical achievements. However, these methods require an excessive amount of environment interactions or large model sizes, limiting their practicality. In this work, we identify that proximal policy optimization (PPO), a simple and versatile model-free algorithm, outperforms the prior methods with recent implementation practices. Moreover, we find that the PPO agent can predict the next achievement to be unlocked to some extent, though with low confidence. Based on this observation, we propose a novel contrastive learning method, called achievement distillation, that strengthens the agent's capability to predict the next achievement. Our method exhibits a strong capacity for discovering hierarchical achievements and shows state-of-the-art performance on the challenging Crafter environment using fewer model parameters in a sample-efficient regime.
Query-Efficient Black-Box Red Teaming via Bayesian Optimization
May 27, 2023



The deployment of large-scale generative models is often restricted by their potential risk of causing harm to users in unpredictable ways. We focus on the problem of black-box red teaming, where a red team generates test cases and interacts with the victim model to discover a diverse set of failures with limited query access. Existing red teaming methods construct test cases based on human supervision or language model (LM) and query all test cases in a brute-force manner without incorporating any information from past evaluations, resulting in a prohibitively large number of queries. To this end, we propose Bayesian red teaming (BRT), novel query-efficient black-box red teaming methods based on Bayesian optimization, which iteratively identify diverse positive test cases leading to model failures by utilizing the pre-defined user input pool and the past evaluations. Experimental results on various user input pools demonstrate that our method consistently finds a significantly larger number of diverse positive test cases under the limited query budget than the baseline methods. The source code is available at https://github.com/snu-mllab/Bayesian-Red-Teaming.
Designing an offline reinforcement learning objective from scratch
Jan 30, 2023



Offline reinforcement learning has developed rapidly over the recent years, but estimating the actual performance of offline policies still remains a challenge. We propose a scoring metric for offline policies that highly correlates with actual policy performance and can be directly used for offline policy optimization in a supervised manner. To achieve this, we leverage the contrastive learning framework to design a scoring metric that gives high scores to policies that imitate the actions yielding relatively high returns while avoiding those yielding relatively low returns. Our experiments show that 1) our scoring metric is able to more accurately rank offline policies and 2) the policies optimized using our metric show high performance on various offline reinforcement learning benchmarks. Notably, our algorithm has a much lower network capacity requirement for the policy network compared to other supervised learning-based methods and also does not need any additional networks such as a Q-network.