 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
May 29, 2025Transformer-based large language models (LLMs) cache context as key-value (KV) pairs during inference. As context length grows, KV cache sizes expand, leading to substantial memory overhead and increased attention latency. This paper introduces KVzip, a query-agnostic KV cache eviction method enabling effective reuse of compressed KV caches across diverse queries. KVzip quantifies the importance of a KV pair using the underlying LLM to reconstruct original contexts from cached KV pairs, subsequently evicting pairs with lower importance. Extensive empirical evaluations demonstrate that KVzip reduces KV cache size by 3-4$\times$ and FlashAttention decoding latency by approximately 2$\times$, with negligible performance loss in question-answering, retrieval, reasoning, and code comprehension tasks. Evaluations include various models such as LLaMA3.1-8B, Qwen2.5-14B, and Gemma3-12B, with context lengths reaching up to 170K tokens. KVzip significantly outperforms existing query-aware KV eviction methods, which suffer from performance degradation even at a 90% cache budget ratio under multi-query scenarios.
GuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
May 11, 2025



Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
LayerMerge: Neural Network Depth Compression through Layer Pruning and Merging
Jun 18, 2024



Recent works show that reducing the number of layers in a convolutional neural network can enhance efficiency while maintaining the performance of the network. Existing depth compression methods remove redundant non-linear activation functions and merge the consecutive convolution layers into a single layer. However, these methods suffer from a critical drawback; the kernel size of the merged layers becomes larger, significantly undermining the latency reduction gained from reducing the depth of the network. We show that this problem can be addressed by jointly pruning convolution layers and activation functions. To this end, we propose LayerMerge, a novel depth compression method that selects which activation layers and convolution layers to remove, to achieve a desired inference speed-up while minimizing performance loss. Since the corresponding selection problem involves an exponential search space, we formulate a novel surrogate optimization problem and efficiently solve it via dynamic programming. Empirical results demonstrate that our method consistently outperforms existing depth compression and layer pruning methods on various network architectures, both on image classification and generation tasks. We release the code at https://github.com/snu-mllab/LayerMerge.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Efficient Latency-Aware CNN Depth Compression via Two-Stage Dynamic Programming
Jan 28, 2023



Recent works on neural network pruning advocate that reducing the depth of the network is more effective in reducing run-time memory usage and accelerating inference latency than reducing the width of the network through channel pruning. In this regard, some recent works propose depth compression algorithms that merge convolution layers. However, the existing algorithms have a constricted search space and rely on human-engineered heuristics. In this paper, we propose a novel depth compression algorithm which targets general convolution operations. We propose a subset selection problem that replaces inefficient activation layers with identity functions and optimally merges consecutive convolution operations into shallow equivalent convolution operations for efficient end-to-end inference latency. Since the proposed subset selection problem is NP-hard, we formulate a surrogate optimization problem that can be solved exactly via two-stage dynamic programming within a few seconds. We evaluate our methods and baselines by TensorRT for a fair inference latency comparison. Our method outperforms the baseline method with higher accuracy and faster inference speed in MobileNetV2 on the ImageNet dataset. Specifically, we achieve $1.61\times$speed-up with only $0.62$\%p accuracy drop in MobileNetV2-1.4 on the ImageNet.
Dataset Condensation via Efficient Synthetic-Data Parameterization
Jun 02, 2022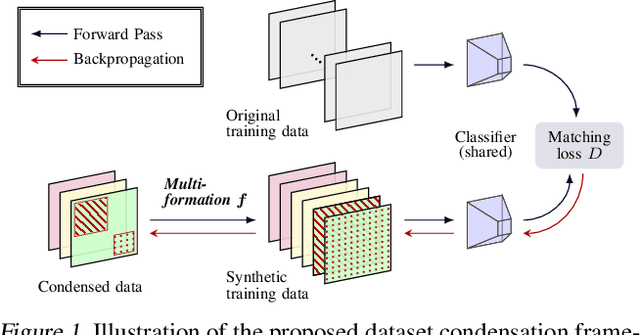
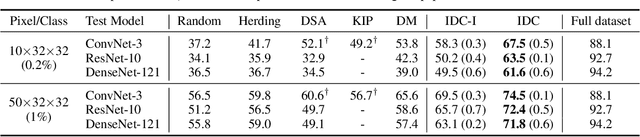
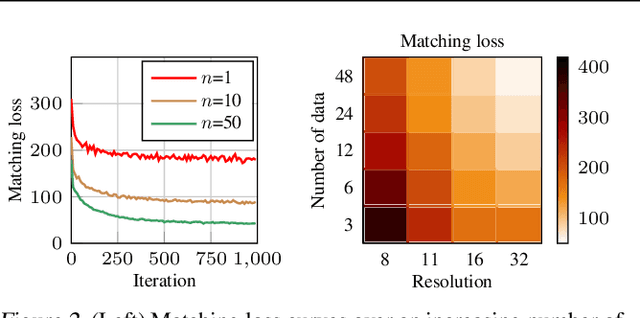
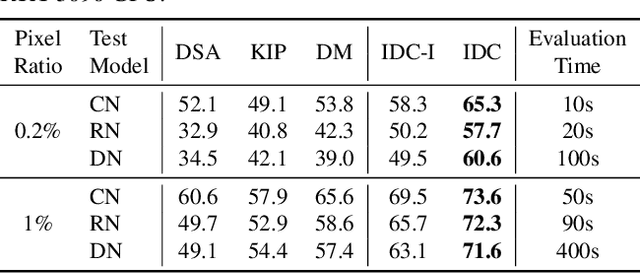
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

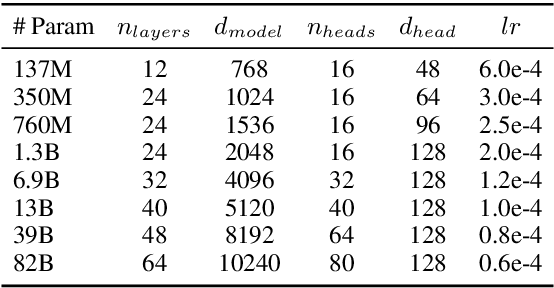
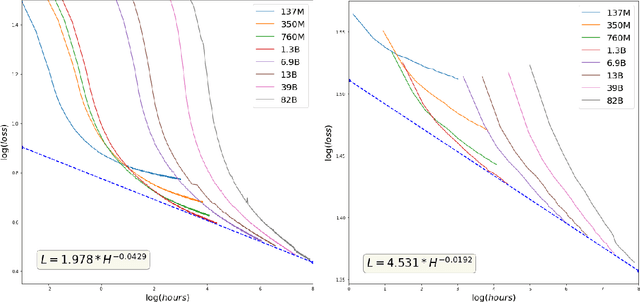
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.