 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Vision-Language Representation Space with Single-tower Transformer
Nov 21, 2022



Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.
Self-Distilled Self-Supervised Representation Learning
Nov 25, 2021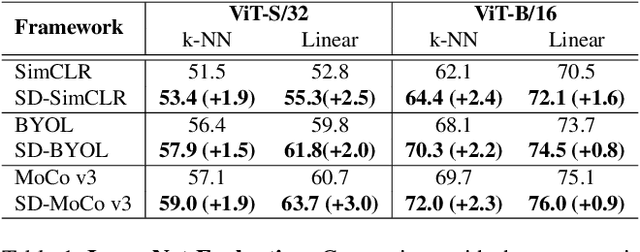
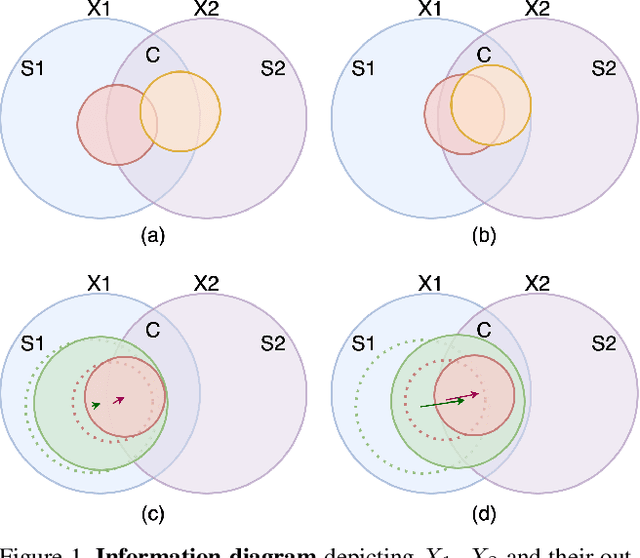
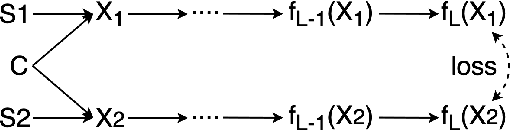
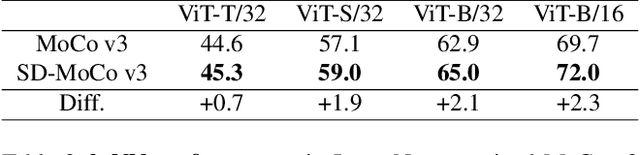
State-of-the-art frameworks in self-supervised learning have recently shown that fully utilizing transformer-based models can lead to performance boost compared to conventional CNN models. Thriving to maximize the mutual information of two views of an image, existing works apply a contrastive loss to the final representations. In our work, we further exploit this by allowing the intermediate representations to learn from the final layers via the contrastive loss, which is maximizing the upper bound of the original goal and the mutual information between two layers. Our method, Self-Distilled Self-Supervised Learning (SDSSL), outperforms competitive baselines (SimCLR, BYOL and MoCo v3) using ViT on various tasks and datasets. In the linear evaluation and k-NN protocol, SDSSL not only leads to superior performance in the final layers, but also in most of the lower layers. Furthermore, positive and negative alignments are used to explain how representations are formed more effectively. Code will be available.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
Sep 10, 2021

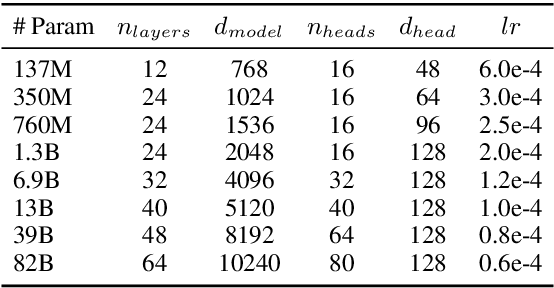
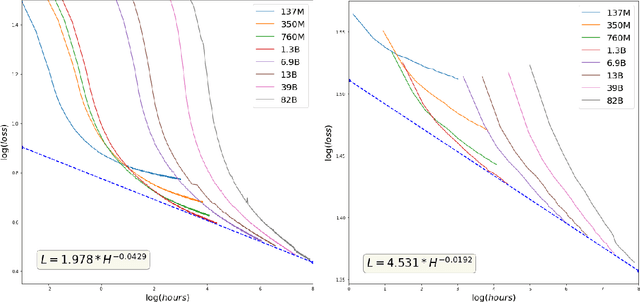
GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.
Self-supervised pre-training and contrastive representation learning for multiple-choice video QA
Sep 17, 2020
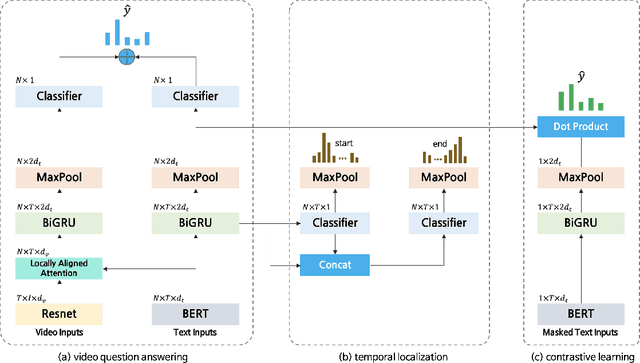
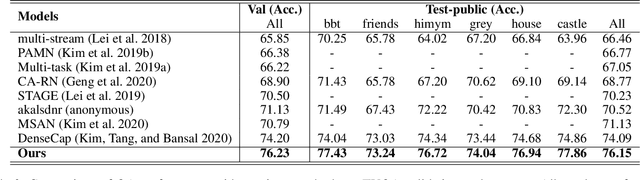
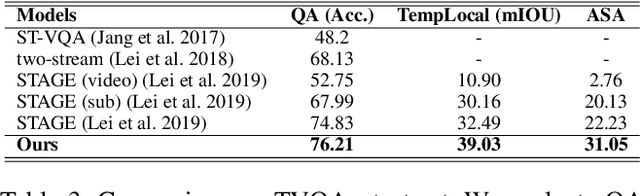
Video Question Answering (Video QA) requires fine-grained understanding of both video and language modalities to answer the given questions. In this paper, we propose novel training schemes for multiple-choice video question answering with a self-supervised pre-training stage and a supervised contrastive learning in the main stage as an auxiliary learning. In the self-supervised pre-training stage, we transform the original problem format of predicting the correct answer into the one that predicts the relevant question to provide a model with broader contextual inputs without any further dataset or annotation. For contrastive learning in the main stage, we add a masking noise to the input corresponding to the ground-truth answer, and consider the original input of the ground-truth answer as a positive sample, while treating the rest as negative samples. By mapping the positive sample closer to the masked input, we show that the model performance is improved. We further employ locally aligned attention to focus more effectively on the video frames that are particularly relevant to the given corresponding subtitle sentences. We evaluate our proposed model on highly competitive benchmark datasets related to multiple-choice videoQA: TVQA, TVQA+, and DramaQA. Experimental results show that our model achieves state-of-the-art performance on all datasets. We also validate our approaches through further analyses.
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
Nov 02, 2018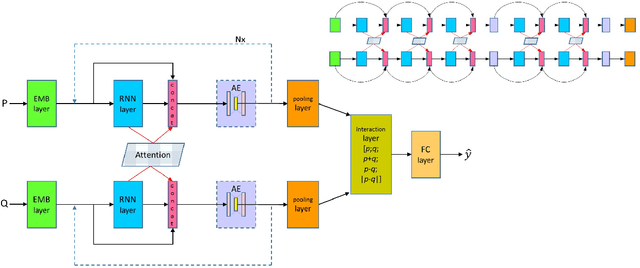
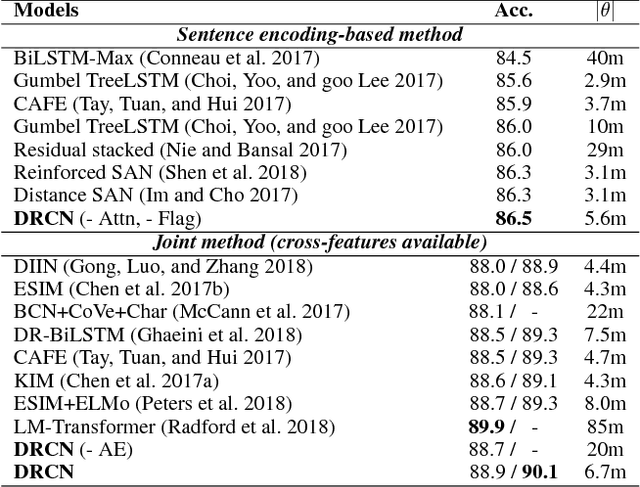
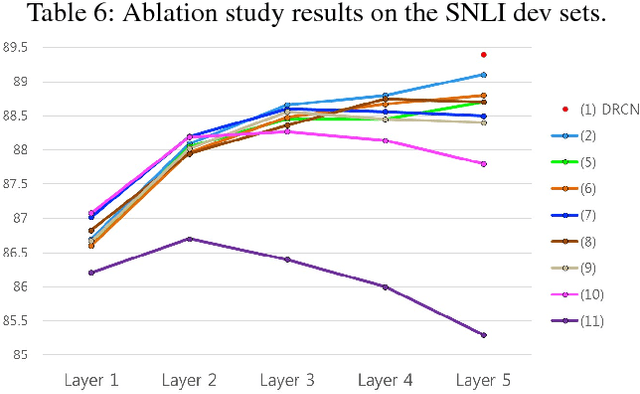
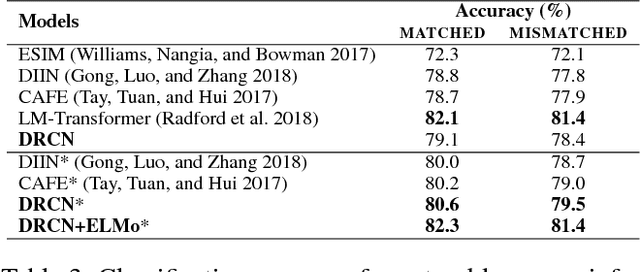
Sentence matching is widely used in various natural language tasks such as natural language inference, paraphrase identification, and question answering. For these tasks, understanding logical and semantic relationship between two sentences is required but it is yet challenging. Although attention mechanism is useful to capture the semantic relationship and to properly align the elements of two sentences, previous methods of attention mechanism simply use a summation operation which does not retain original features enough. Inspired by DenseNet, a densely connected convolutional network, we propose a densely-connected co-attentive recurrent neural network, each layer of which uses concatenated information of attentive features as well as hidden features of all the preceding recurrent layers. It enables preserving the original and the co-attentive feature information from the bottommost word embedding layer to the uppermost recurrent layer. To alleviate the problem of an ever-increasing size of feature vectors due to dense concatenation operations, we also propose to use an autoencoder after dense concatenation. We evaluate our proposed architecture on highly competitive benchmark datasets related to sentence matching. Experimental results show that our architecture, which retains recurrent and attentive features, achieves state-of-the-art performances for most of the tasks.
Textbook Question Answering with Knowledge Graph Understanding and Unsupervised Open-set Text Comprehension
Nov 01, 2018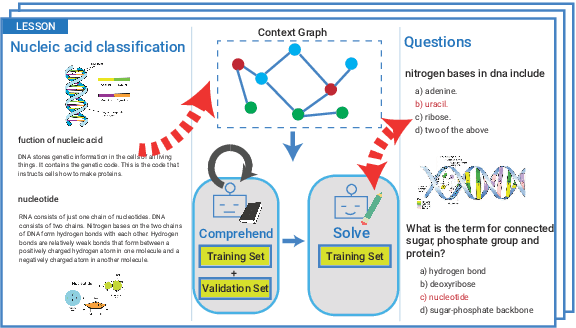
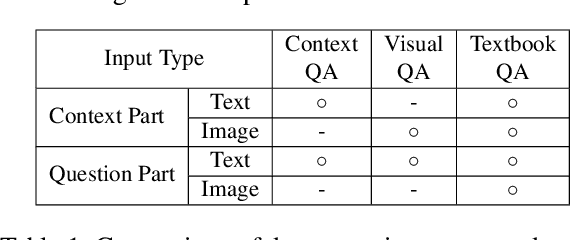
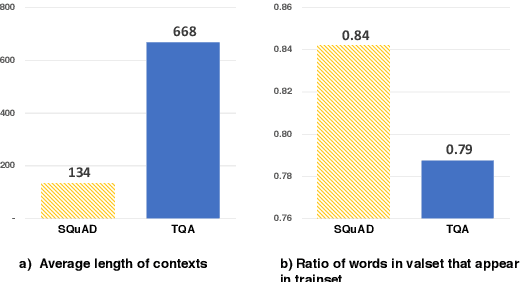
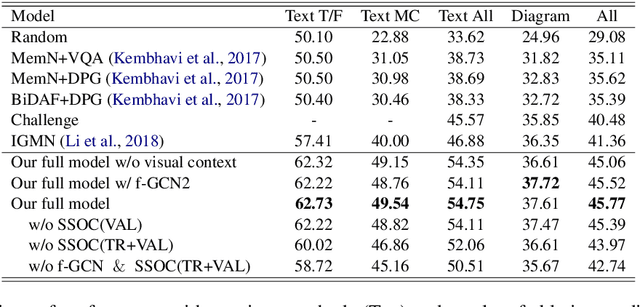
In this work, we introduce a novel algorithm for solving the textbook question answering (TQA) task which describes more realistic QA problems compared to other recent tasks. We mainly focus on two related issues with analysis of TQA dataset. First, it requires to comprehend long lessons to extract knowledge. To tackle this issue of extracting knowledge features from long lessons, we establish knowledge graph from texts and incorporate graph convolutional network (GCN). Second, scientific terms are not spread over the chapters and data splits in TQA dataset. To overcome this so called `out-of-domain' issue, we add novel unsupervised text learning process without any annotations before learning QA problems. The experimental results show that our model significantly outperforms prior state-of-the-art methods. Moreover, ablation studies validate that both methods of incorporating GCN for extracting knowledge from long lessons and our newly proposed unsupervised learning process are meaningful to solve this problem.