 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysicsAgentABM: Physics-Guided Generative Agent-Based Modeling
Feb 05, 2026Large language model (LLM)-based multi-agent systems enable expressive agent reasoning but are expensive to scale and poorly calibrated for timestep-aligned state-transition simulation, while classical agent-based models (ABMs) offer interpretability but struggle to integrate rich individual-level signals and non-stationary behaviors. We propose PhysicsAgentABM, which shifts inference to behaviorally coherent agent clusters: state-specialized symbolic agents encode mechanistic transition priors, a multimodal neural transition model captures temporal and interaction dynamics, and uncertainty-aware epistemic fusion yields calibrated cluster-level transition distributions. Individual agents then stochastically realize transitions under local constraints, decoupling population inference from entity-level variability. We further introduce ANCHOR, an LLM agent-driven clustering strategy based on cross-contextual behavioral responses and a novel contrastive loss, reducing LLM calls by up to 6-8 times. Experiments across public health, finance, and social sciences show consistent gains in event-time accuracy and calibration over mechanistic, neural, and LLM baselines. By re-architecting generative ABM around population-level inference with uncertainty-aware neuro-symbolic fusion, PhysicsAgentABM establishes a new paradigm for scalable and calibrated simulation with LLMs.
MolEdit: Knowledge Editing for Multimodal Molecule Language Models
Nov 16, 2025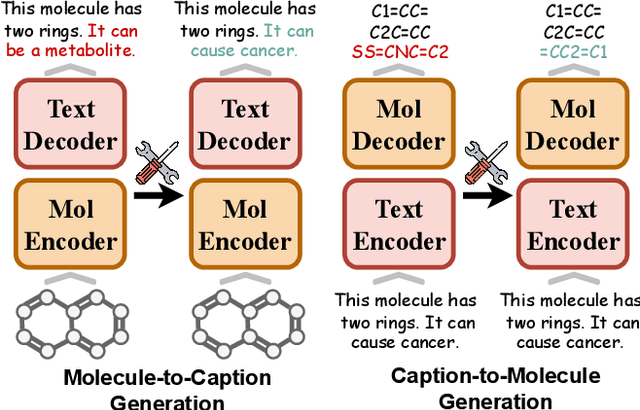



Understanding and continuously refining multimodal molecular knowledge is crucial for advancing biomedicine, chemistry, and materials science. Molecule language models (MoLMs) have become powerful tools in these domains, integrating structural representations (e.g., SMILES strings, molecular graphs) with rich contextual descriptions (e.g., physicochemical properties). However, MoLMs can encode and propagate inaccuracies due to outdated web-mined training corpora or malicious manipulation, jeopardizing downstream discovery pipelines. While knowledge editing has been explored for general-domain AI, its application to MoLMs remains uncharted, presenting unique challenges due to the multifaceted and interdependent nature of molecular knowledge. In this paper, we take the first step toward MoLM editing for two critical tasks: molecule-to-caption generation and caption-to-molecule generation. To address molecule-specific challenges, we propose MolEdit, a powerful framework that enables targeted modifications while preserving unrelated molecular knowledge. MolEdit combines a Multi-Expert Knowledge Adapter that routes edits to specialized experts for different molecular facets with an Expertise-Aware Editing Switcher that activates the adapters only when input closely matches the stored edits across all expertise, minimizing interference with unrelated knowledge. To systematically evaluate editing performance, we introduce MEBench, a comprehensive benchmark assessing multiple dimensions, including Reliability (accuracy of the editing), Locality (preservation of irrelevant knowledge), and Generality (robustness to reformed queries). Across extensive experiments on two popular MoLM backbones, MolEdit delivers up to 18.8% higher Reliability and 12.0% better Locality than baselines while maintaining efficiency. The code is available at: https://github.com/LzyFischer/MolEdit.
GraphTOP: Graph Topology-Oriented Prompting for Graph Neural Networks
Oct 25, 2025Graph Neural Networks (GNNs) have revolutionized the field of graph learning by learning expressive graph representations from massive graph data. As a common pattern to train powerful GNNs, the "pre-training, adaptation" scheme first pre-trains GNNs over unlabeled graph data and subsequently adapts them to specific downstream tasks. In the adaptation phase, graph prompting is an effective strategy that modifies input graph data with learnable prompts while keeping pre-trained GNN models frozen. Typically, existing graph prompting studies mainly focus on *feature-oriented* methods that apply graph prompts to node features or hidden representations. However, these studies often achieve suboptimal performance, as they consistently overlook the potential of *topology-oriented* prompting, which adapts pre-trained GNNs by modifying the graph topology. In this study, we conduct a pioneering investigation of graph prompting in terms of graph topology. We propose the first **Graph** **T**opology-**O**riented **P**rompting (GraphTOP) framework to effectively adapt pre-trained GNN models for downstream tasks. More specifically, we reformulate topology-oriented prompting as an edge rewiring problem within multi-hop local subgraphs and relax it into the continuous probability space through reparameterization while ensuring tight relaxation and preserving graph sparsity. Extensive experiments on five graph datasets under four pre-training strategies demonstrate that our proposed GraphTOP outshines six baselines on multiple node classification datasets. Our code is available at https://github.com/xbfu/GraphTOP.
Learning from Diverse Reasoning Paths with Routing and Collaboration
Aug 23, 2025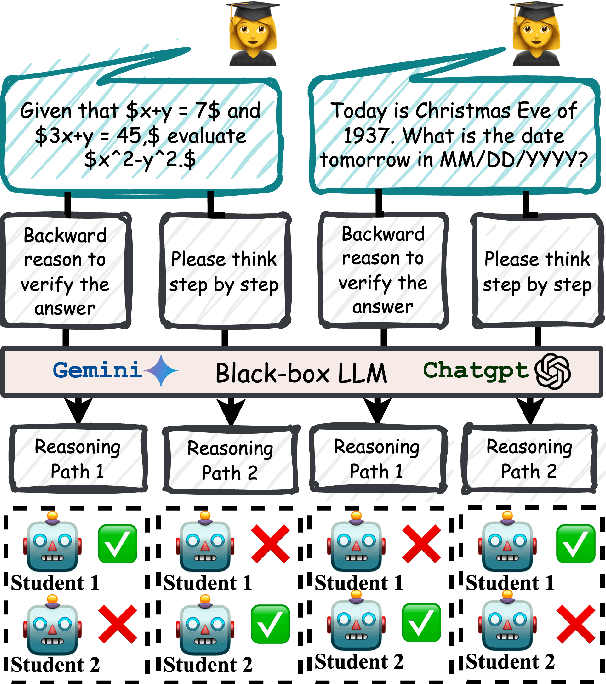
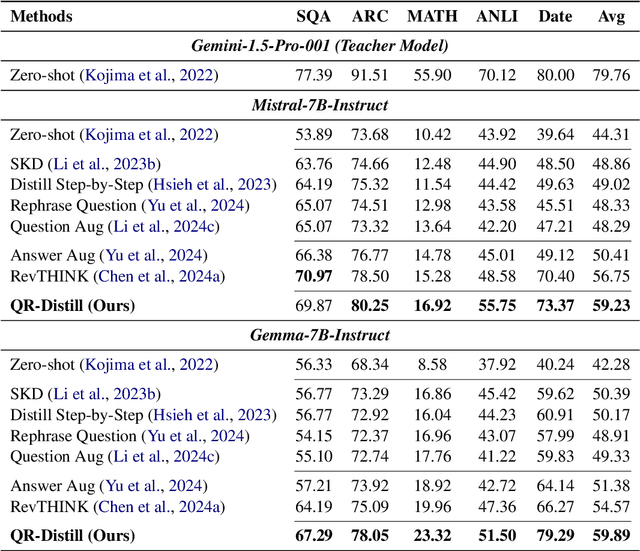
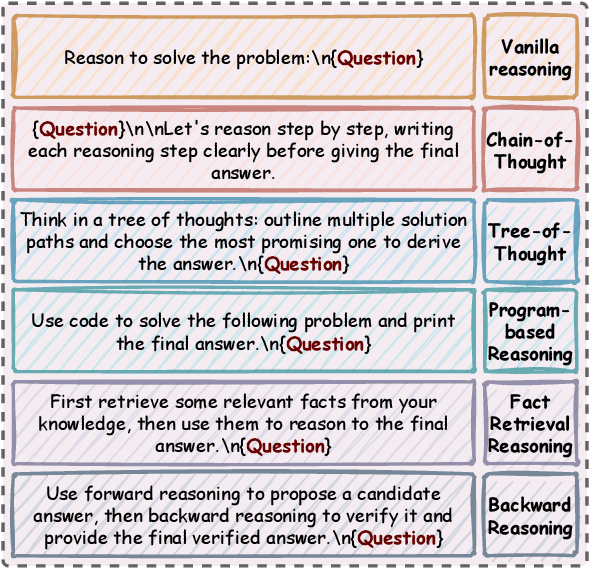
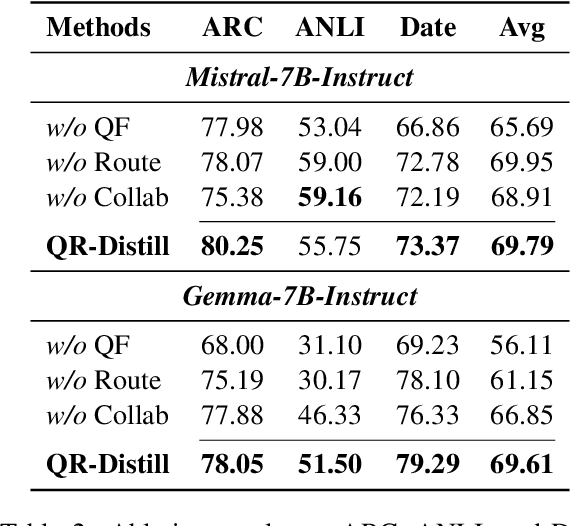
Advances in large language models (LLMs) significantly enhance reasoning capabilities but their deployment is restricted in resource-constrained scenarios. Knowledge distillation addresses this by transferring knowledge from powerful teacher models to compact and transparent students. However, effectively capturing the teacher's comprehensive reasoning is challenging due to conventional token-level supervision's limited scope. Using multiple reasoning paths per query alleviates this problem, but treating each path identically is suboptimal as paths vary widely in quality and suitability across tasks and models. We propose Quality-filtered Routing with Cooperative Distillation (QR-Distill), combining path quality filtering, conditional routing, and cooperative peer teaching. First, quality filtering retains only correct reasoning paths scored by an LLM-based evaluation. Second, conditional routing dynamically assigns paths tailored to each student's current learning state. Finally, cooperative peer teaching enables students to mutually distill diverse insights, addressing knowledge gaps and biases toward specific reasoning styles. Experiments demonstrate QR-Distill's superiority over traditional single- and multi-path distillation methods. Ablation studies further highlight the importance of each component including quality filtering, conditional routing, and peer teaching in effective knowledge transfer. Our code is available at https://github.com/LzyFischer/Distill.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025



Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
Jun 10, 2025


Graph learning models have demonstrated great prowess in learning expressive representations from large-scale graph data in a wide variety of real-world scenarios. As a prevalent strategy for training powerful graph learning models, the "pre-training, adaptation" scheme first pre-trains graph learning models on unlabeled graph data in a self-supervised manner and then adapts them to specific downstream tasks. During the adaptation phase, graph prompting emerges as a promising approach that learns trainable prompts while keeping the pre-trained graph learning models unchanged. In this paper, we present a systematic review of recent advancements in graph prompting. First, we introduce representative graph pre-training methods that serve as the foundation step of graph prompting. Next, we review mainstream techniques in graph prompting and elaborate on how they design learnable prompts for graph prompting. Furthermore, we summarize the real-world applications of graph prompting from different domains. Finally, we discuss several open challenges in existing studies with promising future directions in this field.
MAPLE: Many-Shot Adaptive Pseudo-Labeling for In-Context Learning
May 22, 2025In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle diverse tasks by incorporating multiple input-output examples, known as demonstrations, into the input of LLMs. More recently, advancements in the expanded context windows of LLMs have led to many-shot ICL, which uses hundreds of demonstrations and outperforms few-shot ICL, which relies on fewer examples. However, this approach is often hindered by the high cost of obtaining large amounts of labeled data. To address this challenge, we propose Many-Shot Adaptive Pseudo-LabEling, namely MAPLE, a novel influence-based many-shot ICL framework that utilizes pseudo-labeled samples to compensate for the lack of label information. We first identify a subset of impactful unlabeled samples and perform pseudo-labeling on them by querying LLMs. These pseudo-labeled samples are then adaptively selected and tailored to each test query as input to improve the performance of many-shot ICL, without significant labeling costs. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework, showcasing its ability to enhance LLM adaptability and performance with limited labeled data.
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.
FedHERO: A Federated Learning Approach for Node Classification Task on Heterophilic Graphs
Apr 29, 2025



Federated Graph Learning (FGL) empowers clients to collaboratively train Graph neural networks (GNNs) in a distributed manner while preserving data privacy. However, FGL methods usually require that the graph data owned by all clients is homophilic to ensure similar neighbor distribution patterns of nodes. Such an assumption ensures that the learned knowledge is consistent across the local models from all clients. Therefore, these local models can be properly aggregated as a global model without undermining the overall performance. Nevertheless, when the neighbor distribution patterns of nodes vary across different clients (e.g., when clients hold graphs with different levels of heterophily), their local models may gain different and even conflict knowledge from their node-level predictive tasks. Consequently, aggregating these local models usually leads to catastrophic performance deterioration on the global model. To address this challenge, we propose FedHERO, an FGL framework designed to harness and share insights from heterophilic graphs effectively. At the heart of FedHERO is a dual-channel GNN equipped with a structure learner, engineered to discern the structural knowledge encoded in the local graphs. With this specialized component, FedHERO enables the local model for each client to identify and learn patterns that are universally applicable across graphs with different patterns of node neighbor distributions. FedHERO not only enhances the performance of individual client models by leveraging both local and shared structural insights but also sets a new precedent in this field to effectively handle graph data with various node neighbor distribution patterns. We conduct extensive experiments to validate the superior performance of FedHERO against existing alternatives.