 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIM: Semantic-based Low-bitrate Image compression for Machines by leveraging diffusion
Dec 23, 2025



In recent years, the demand of image compression models for machine vision has increased dramatically. However, the training frameworks of image compression still focus on the vision of human, maintaining the excessive perceptual details, thus have limitations in optimally reducing the bits per pixel in the case of performing machine vision tasks. In this paper, we propose Semantic-based Low-bitrate Image compression for Machines by leveraging diffusion, termed SLIM. This is a new effective training framework of image compression for machine vision, using a pretrained latent diffusion model.The compressor model of our method focuses only on the Region-of-Interest (RoI) areas for machine vision in the image latent, to compress it compactly. Then the pretrained Unet model enhances the decompressed latent, utilizing a RoI-focused text caption which containing semantic information of the image. Therefore, SLIM is able to focus on RoI areas of the image without any guide mask at the inference stage, achieving low bitrate when compressing. And SLIM is also able to enhance a decompressed latent by denoising steps, so the final reconstructed image from the enhanced latent can be optimized for the machine vision task while still containing perceptual details for human vision. Experimental results show that SLIM achieves a higher classification accuracy in the same bits per pixel condition, compared to conventional image compression models for machines.
Progressive Learned Image Compression for Machine Perception
Dec 23, 2025Recent advances in learned image codecs have been extended from human perception toward machine perception. However, progressive image compression with fine granular scalability (FGS)-which enables decoding a single bitstream at multiple quality levels-remains unexplored for machine-oriented codecs. In this work, we propose a novel progressive learned image compression codec for machine perception, PICM-Net, based on trit-plane coding. By analyzing the difference between human- and machine-oriented rate-distortion priorities, we systematically examine the latent prioritization strategies in terms of machine-oriented codecs. To further enhance real-world adaptability, we design an adaptive decoding controller, which dynamically determines the necessary decoding level during inference time to maintain the desired confidence of downstream machine prediction. Extensive experiments demonstrate that our approach enables efficient and adaptive progressive transmission while maintaining high performance in the downstream classification task, establishing a new paradigm for machine-aware progressive image compression.
DESSERT: Diffusion-based Event-driven Single-frame Synthesis via Residual Training
Dec 19, 2025Video frame prediction extrapolates future frames from previous frames, but suffers from prediction errors in dynamic scenes due to the lack of information about the next frame. Event cameras address this limitation by capturing per-pixel brightness changes asynchronously with high temporal resolution. Prior research on event-based video frame prediction has leveraged motion information from event data, often by predicting event-based optical flow and reconstructing frames via pixel warping. However, such approaches introduce holes and blurring when pixel displacement is inaccurate. To overcome this limitation, we propose DESSERT, a diffusion-based event-driven single-frame synthesis framework via residual training. Leveraging a pre-trained Stable Diffusion model, our method is trained on inter-frame residuals to ensure temporal consistency. The training pipeline consists of two stages: (1) an Event-to-Residual Alignment Variational Autoencoder (ER-VAE) that aligns the event frame between anchor and target frames with the corresponding residual, and (2) a diffusion model that denoises the residual latent conditioned on event data. Furthermore, we introduce Diverse-Length Temporal (DLT) augmentation, which improves robustness by training on frame segments of varying temporal lengths. Experimental results demonstrate that our method outperforms existing event-based reconstruction, image-based video frame prediction, event-based video frame prediction, and one-sided event-based video frame interpolation methods, producing sharper and more temporally consistent frame synthesis.
Neural Image Compression with Text-guided Encoding for both Pixel-level and Perceptual Fidelity
Mar 05, 2024Recent advances in text-guided image compression have shown great potential to enhance the perceptual quality of reconstructed images. These methods, however, tend to have significantly degraded pixel-wise fidelity, limiting their practicality. To fill this gap, we develop a new text-guided image compression algorithm that achieves both high perceptual and pixel-wise fidelity. In particular, we propose a compression framework that leverages text information mainly by text-adaptive encoding and training with joint image-text loss. By doing so, we avoid decoding based on text-guided generative models -- known for high generative diversity -- and effectively utilize the semantic information of text at a global level. Experimental results on various datasets show that our method can achieve high pixel-level and perceptual quality, with either human- or machine-generated captions. In particular, our method outperforms all baselines in terms of LPIPS, with some room for even more improvements when we use more carefully generated captions.
Demystifying Randomly Initialized Networks for Evaluating Generative Models
Aug 19, 2022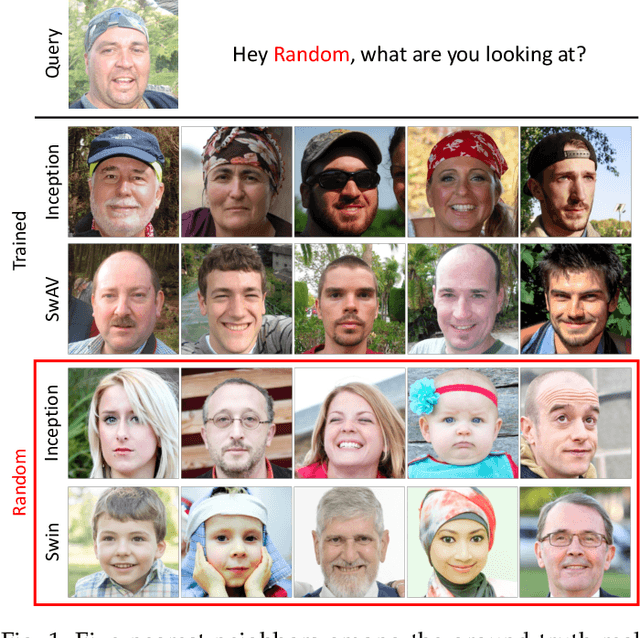
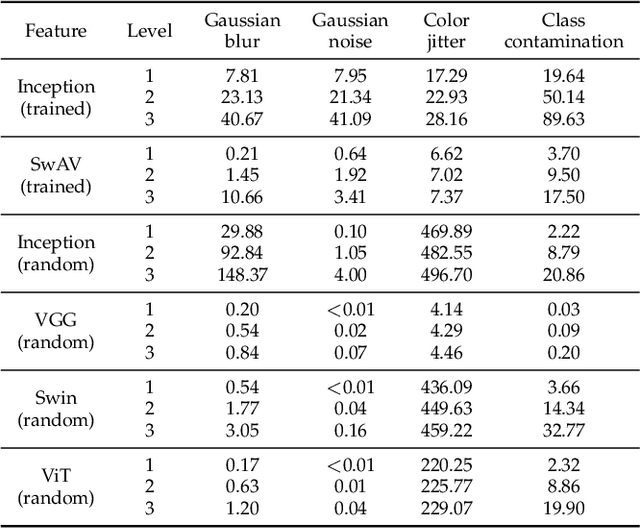

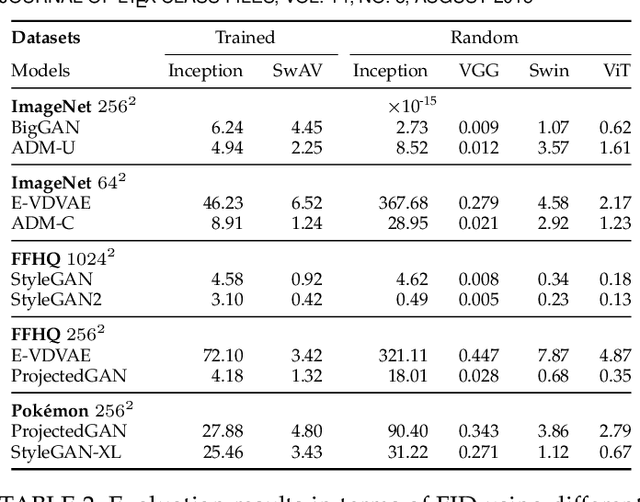
Evaluation of generative models is mostly based on the comparison between the estimated distribution and the ground truth distribution in a certain feature space. To embed samples into informative features, previous works often use convolutional neural networks optimized for classification, which is criticized by recent studies. Therefore, various feature spaces have been explored to discover alternatives. Among them, a surprising approach is to use a randomly initialized neural network for feature embedding. However, the fundamental basis to employ the random features has not been sufficiently justified. In this paper, we rigorously investigate the feature space of models with random weights in comparison to that of trained models. Furthermore, we provide an empirical evidence to choose networks for random features to obtain consistent and reliable results. Our results indicate that the features from random networks can evaluate generative models well similarly to those from trained networks, and furthermore, the two types of features can be used together in a complementary way.
Joint Global and Local Hierarchical Priors for Learned Image Compression
Dec 08, 2021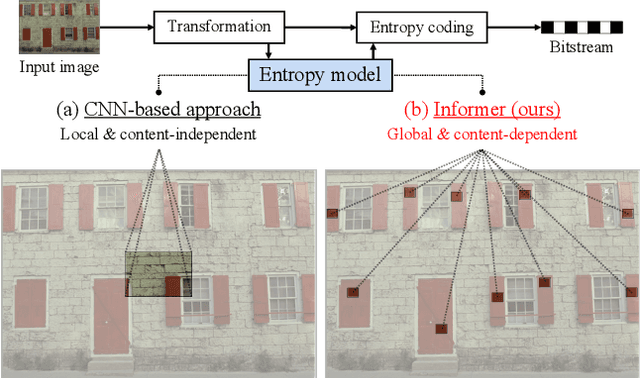


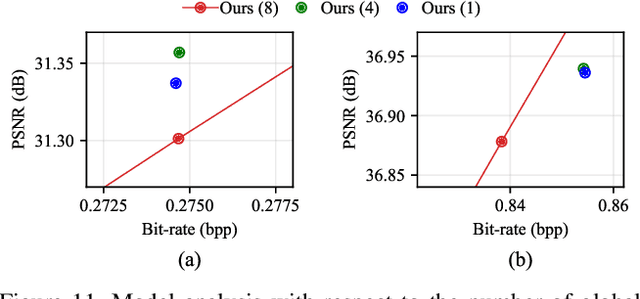
Recently, learned image compression methods have shown superior performance compared to the traditional hand-crafted image codecs including BPG. One of the fundamental research directions in learned image compression is to develop entropy models that accurately estimate the probability distribution of the quantized latent representation. Like other vision tasks, most of the recent learned entropy models are based on convolutional neural networks (CNNs). However, CNNs have a limitation in modeling dependencies between distant regions due to their nature of local connectivity, which can be a significant bottleneck in image compression where reducing spatial redundancy is a key point. To address this issue, we propose a novel entropy model called Information Transformer (Informer) that exploits both local and global information in a content-dependent manner using an attention mechanism. Our experiments demonstrate that Informer improves rate-distortion performance over the state-of-the-art methods on the Kodak and Tecnick datasets without the quadratic computational complexity problem.
Deep Image Destruction: A Comprehensive Study on Vulnerability of Deep Image-to-Image Models against Adversarial Attacks
Apr 30, 2021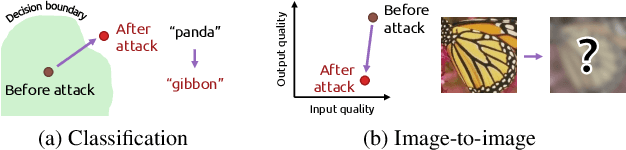
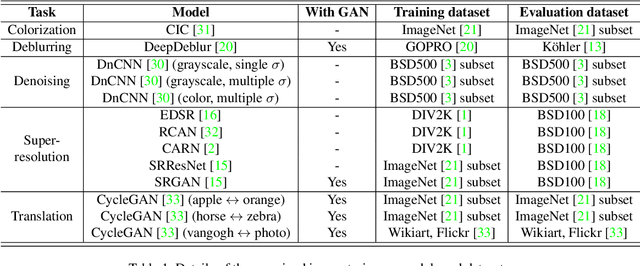
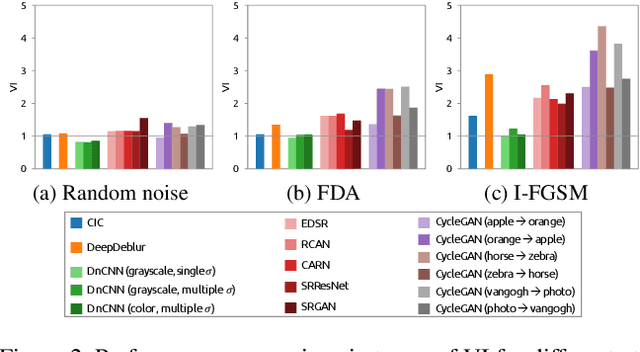

Recently, the vulnerability of deep image classification models to adversarial attacks has been investigated. However, such an issue has not been thoroughly studied for image-to-image models that can have different characteristics in quantitative evaluation, consequences of attacks, and defense strategy. To tackle this, we present comprehensive investigations into the vulnerability of deep image-to-image models to adversarial attacks. For five popular image-to-image tasks, 16 deep models are analyzed from various standpoints such as output quality degradation due to attacks, transferability of adversarial examples across different tasks, and characteristics of perturbations. We show that unlike in image classification tasks, the performance degradation on image-to-image tasks can largely differ depending on various factors, e.g., attack methods and task objectives. In addition, we analyze the effectiveness of conventional defense methods used for classification models in improving the robustness of the image-to-image models.
Just One Moment: Inconspicuous One Frame Attack on Deep Action Recognition
Nov 30, 2020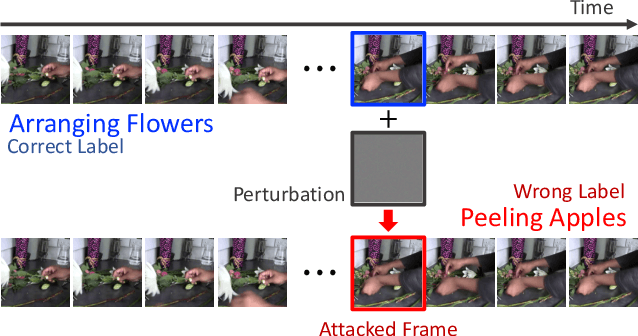
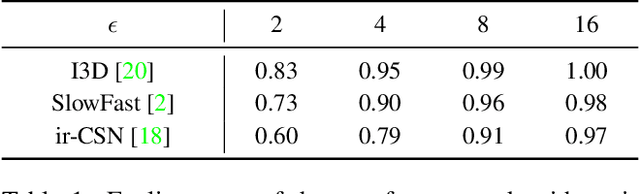
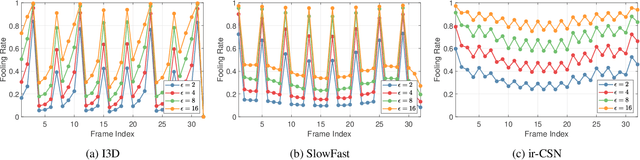
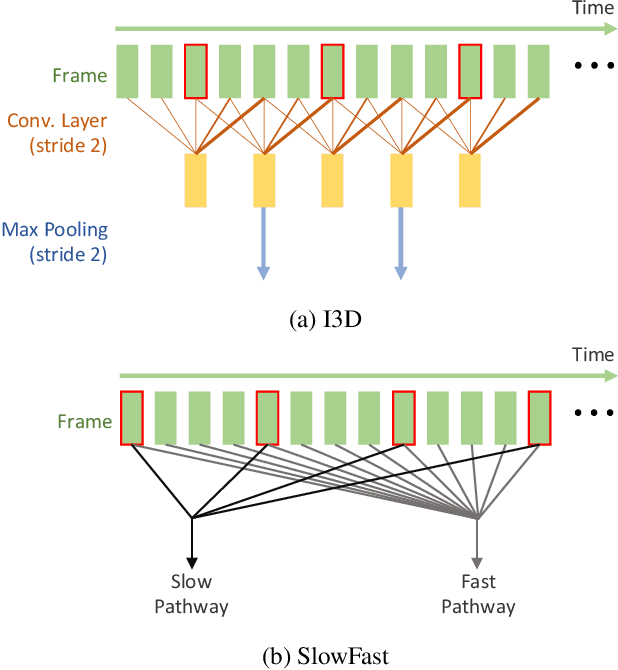
The video-based action recognition task has been extensively studied in recent years. In this paper, we study the vulnerability of deep learning-based action recognition methods against the adversarial attack using a new one frame attack that adds an inconspicuous perturbation to only a single frame of a given video clip. We investigate the effectiveness of our one frame attack on state-of-the-art action recognition models, along with thorough analysis of the vulnerability in terms of their model structure and perceivability of the perturbation. Our method shows high fooling rates and produces hardly perceivable perturbation to human observers, which is evaluated by a subjective test. In addition, we present a video-agnostic approach that finds a universal perturbation.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020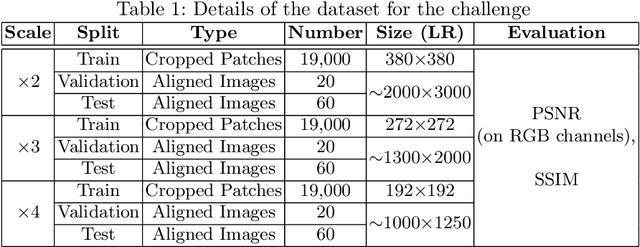
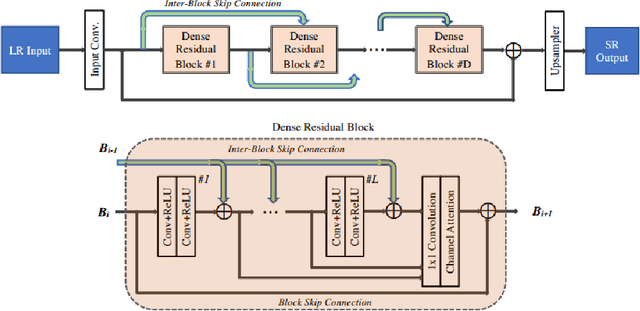
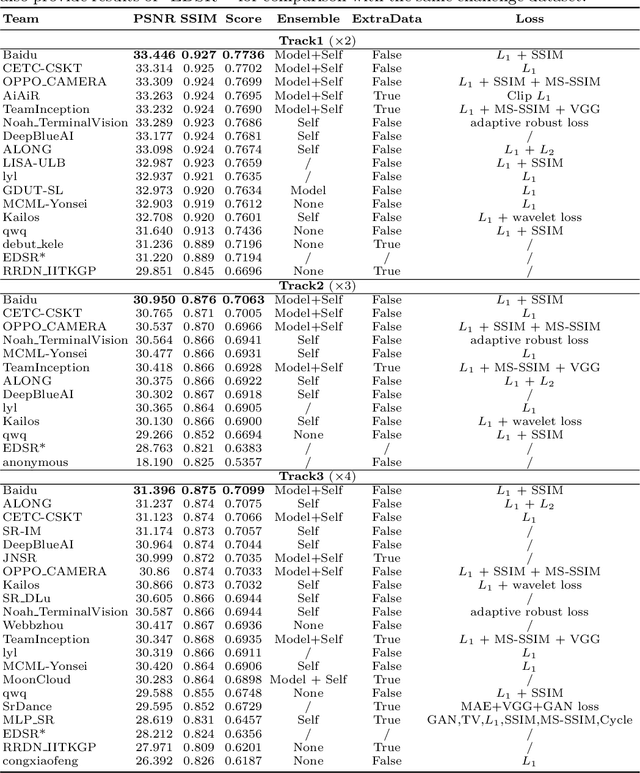
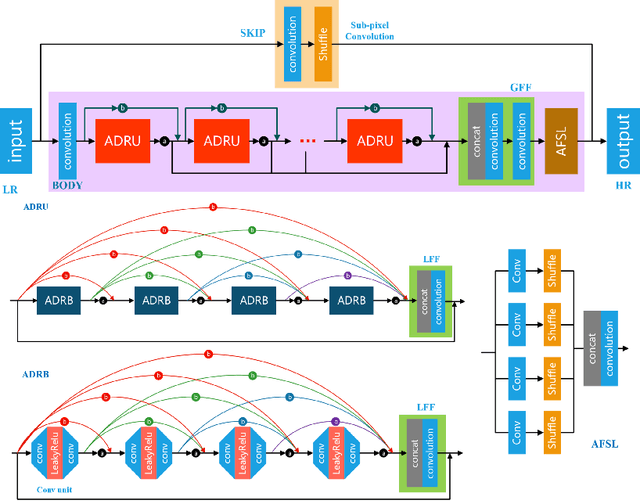
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020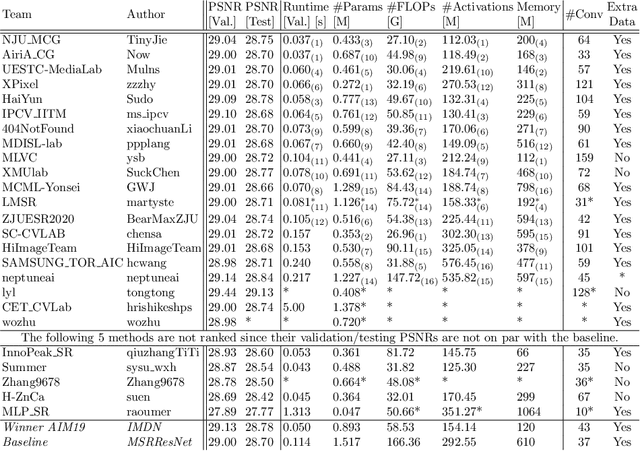
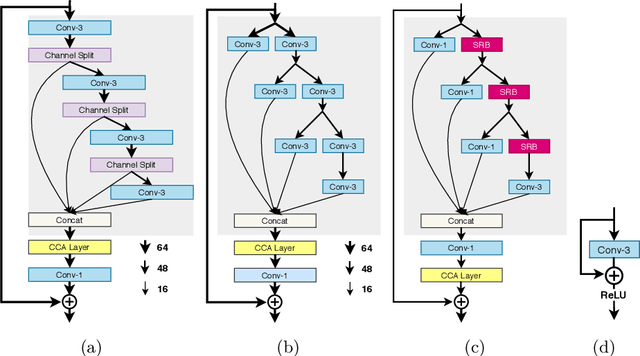
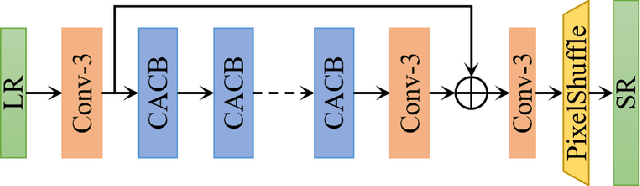
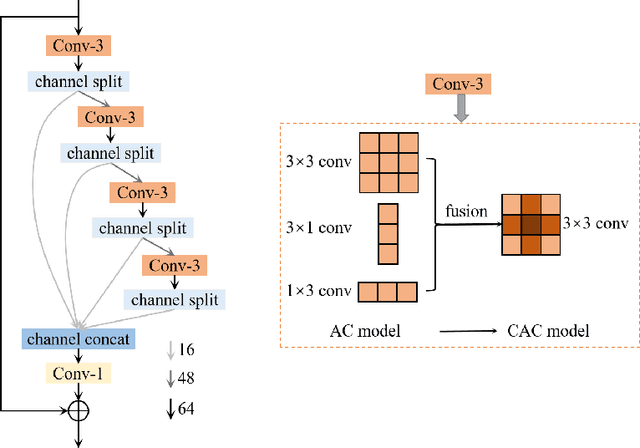
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.