 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAA-Forecast: Anomaly-Aware Forecast for Extreme Events
Aug 21, 2022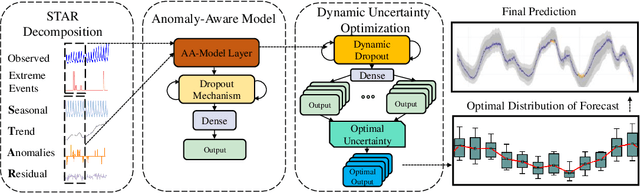
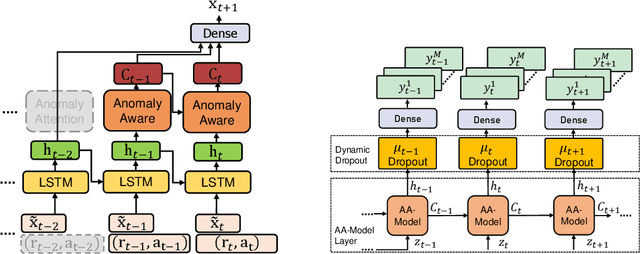

Time series models often deal with extreme events and anomalies, both prevalent in real-world datasets. Such models often need to provide careful probabilistic forecasting, which is vital in risk management for extreme events such as hurricanes and pandemics. However, it is challenging to automatically detect and learn to use extreme events and anomalies for large-scale datasets, which often require manual effort. Hence, we propose an anomaly-aware forecast framework that leverages the previously seen effects of anomalies to improve its prediction accuracy during and after the presence of extreme events. Specifically, the framework automatically extracts anomalies and incorporates them through an attention mechanism to increase its accuracy for future extreme events. Moreover, the framework employs a dynamic uncertainty optimization algorithm that reduces the uncertainty of forecasts in an online manner. The proposed framework demonstrated consistent superior accuracy with less uncertainty on three datasets with different varieties of anomalies over the current prediction models.
TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022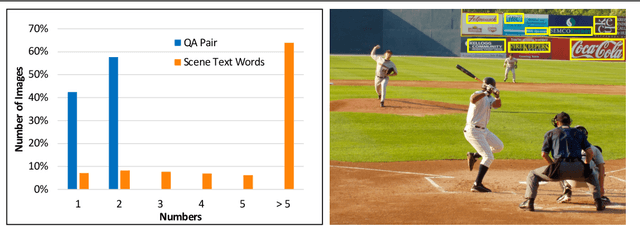
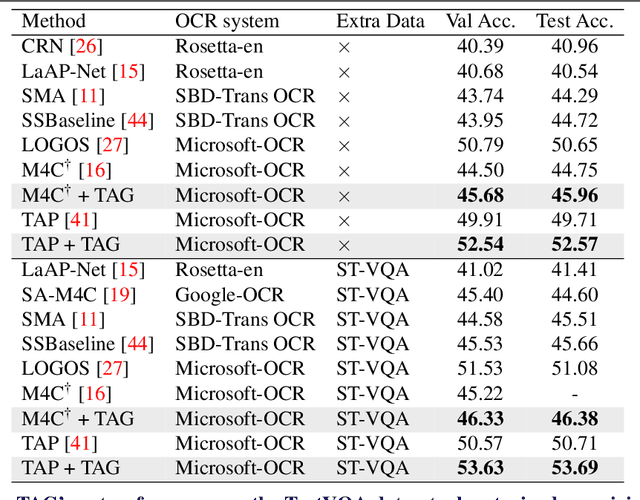

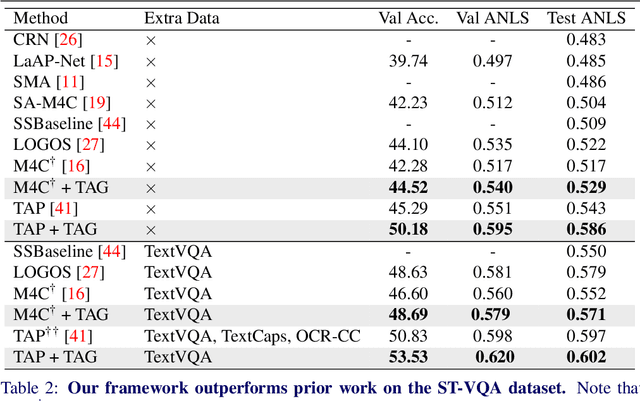
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022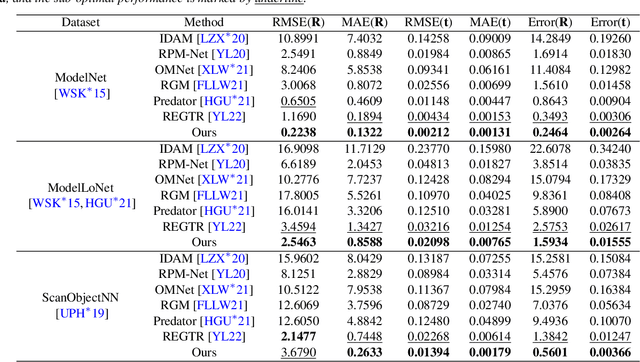
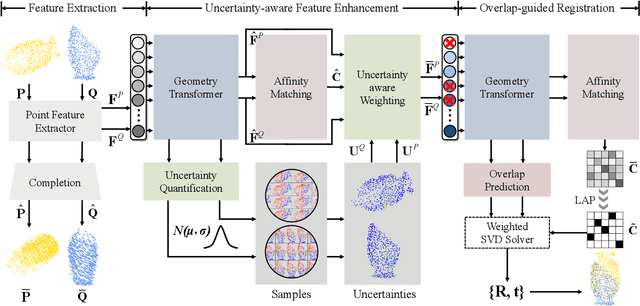
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.
Multi-View Pre-Trained Model for Code Vulnerability Identification
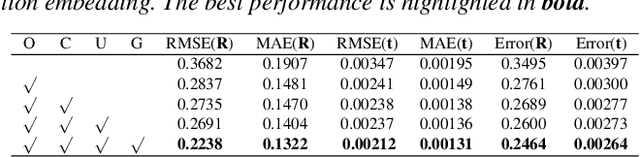
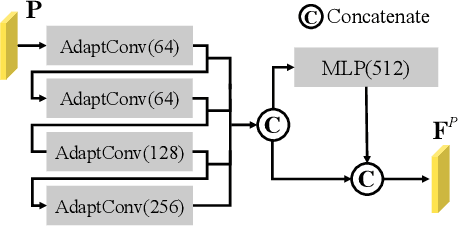
Aug 10, 2022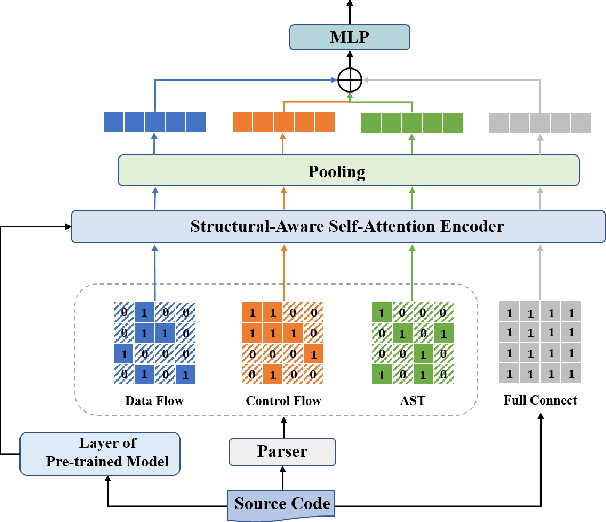
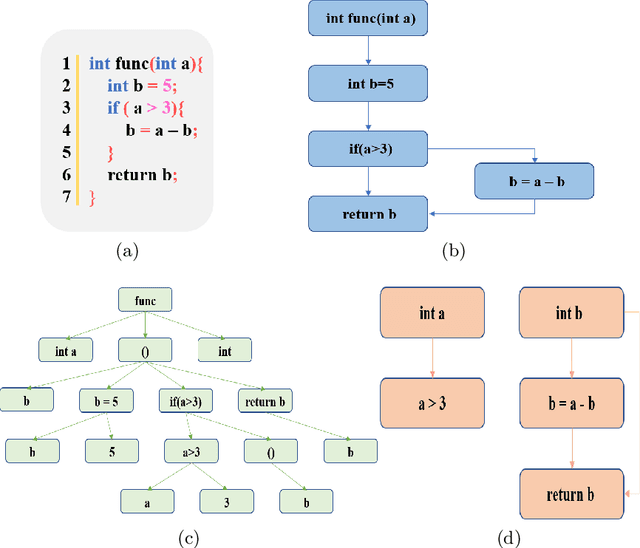
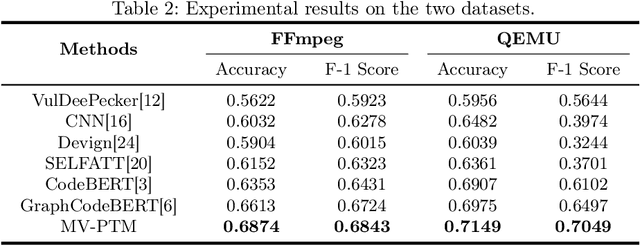
Vulnerability identification is crucial for cyber security in the software-related industry. Early identification methods require significant manual efforts in crafting features or annotating vulnerable code. Although the recent pre-trained models alleviate this issue, they overlook the multiple rich structural information contained in the code itself. In this paper, we propose a novel Multi-View Pre-Trained Model (MV-PTM) that encodes both sequential and multi-type structural information of the source code and uses contrastive learning to enhance code representations. The experiments conducted on two public datasets demonstrate the superiority of MV-PTM. In particular, MV-PTM improves GraphCodeBERT by 3.36\% on average in terms of F1 score.
A high-resolution dynamical view on momentum methods for over-parameterized neural networks
Aug 08, 2022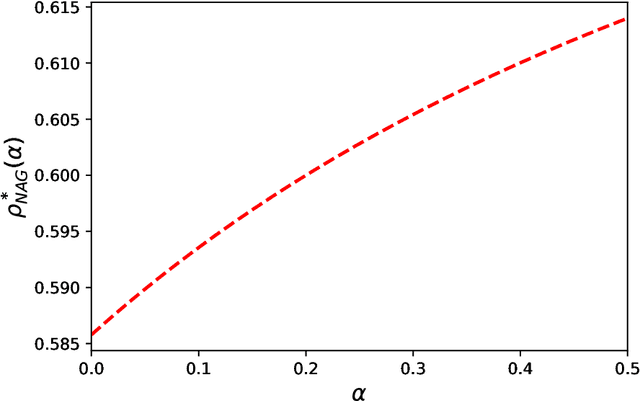
In this paper, we present the convergence analysis of momentum methods in training a two-layer over-parameterized ReLU neural network, where the number of parameters is significantly larger than that of training instances. Existing works on momentum methods show that the heavy-ball method (HB) and Nesterov's accelerated method (NAG) share the same limiting ordinary differential equation (ODE), which leads to identical convergence rate. From a high-resolution dynamical view, we show that HB differs from NAG in terms of the convergence rate. In addition, our findings provide tighter upper bounds on convergence for the high-resolution ODEs of HB and NAG.
Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL
Aug 02, 2022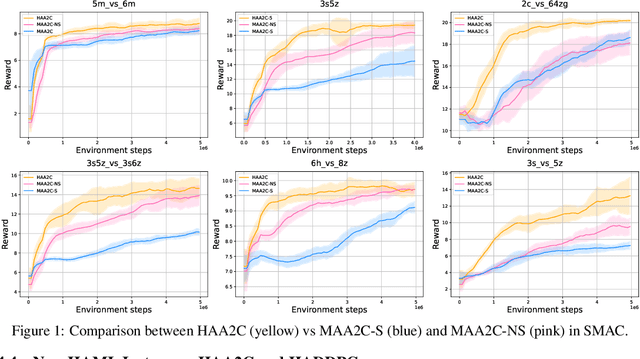


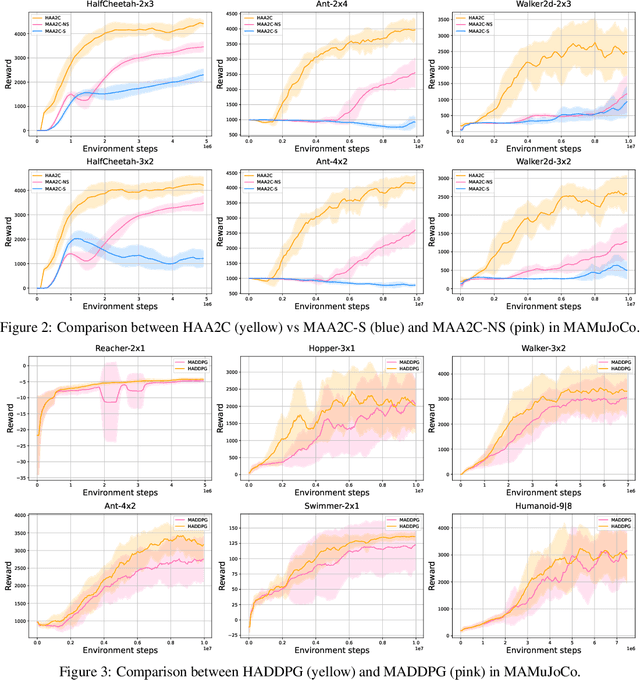
The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in the artificial intelligence (AI) research community. However, many research endeavors have been focused on developing practical MARL algorithms whose effectiveness has been studied only empirically, thereby lacking theoretical guarantees. As recent studies have revealed, MARL methods often achieve performance that is unstable in terms of reward monotonicity or suboptimal at convergence. To resolve these issues, in this paper, we introduce a novel framework named Heterogeneous-Agent Mirror Learning (HAML) that provides a general template for MARL algorithmic designs. We prove that algorithms derived from the HAML template satisfy the desired properties of the monotonic improvement of the joint reward and the convergence to Nash equilibrium. We verify the practicality of HAML by proving that the current state-of-the-art cooperative MARL algorithms, HATRPO and HAPPO, are in fact HAML instances. Next, as a natural outcome of our theory, we propose HAML extensions of two well-known RL algorithms, HAA2C (for A2C) and HADDPG (for DDPG), and demonstrate their effectiveness against strong baselines on StarCraftII and Multi-Agent MuJoCo tasks.
CSDN: Cross-modal Shape-transfer Dual-refinement Network for Point Cloud Completion
Aug 01, 2022
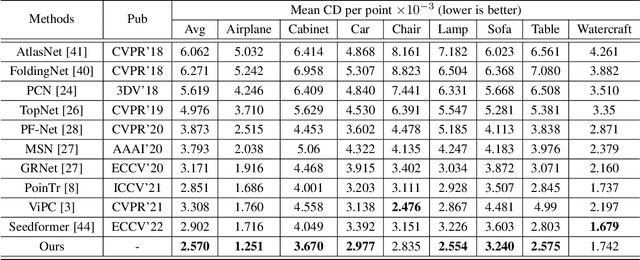
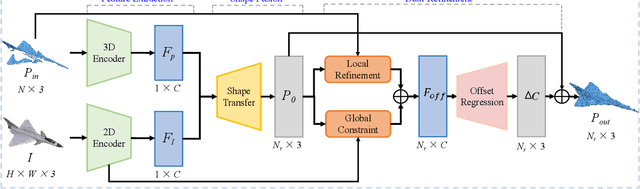
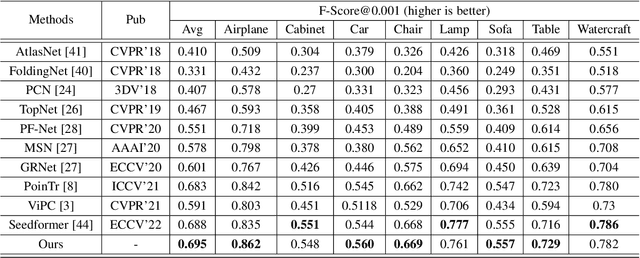
How will you repair a physical object with some missings? You may imagine its original shape from previously captured images, recover its overall (global) but coarse shape first, and then refine its local details. We are motivated to imitate the physical repair procedure to address point cloud completion. To this end, we propose a cross-modal shape-transfer dual-refinement network (termed CSDN), a coarse-to-fine paradigm with images of full-cycle participation, for quality point cloud completion. CSDN mainly consists of "shape fusion" and "dual-refinement" modules to tackle the cross-modal challenge. The first module transfers the intrinsic shape characteristics from single images to guide the geometry generation of the missing regions of point clouds, in which we propose IPAdaIN to embed the global features of both the image and the partial point cloud into completion. The second module refines the coarse output by adjusting the positions of the generated points, where the local refinement unit exploits the geometric relation between the novel and the input points by graph convolution, and the global constraint unit utilizes the input image to fine-tune the generated offset. Different from most existing approaches, CSDN not only explores the complementary information from images but also effectively exploits cross-modal data in the whole coarse-to-fine completion procedure. Experimental results indicate that CSDN performs favorably against ten competitors on the cross-modal benchmark.
Branch Ranking for Efficient Mixed-Integer Programming via Offline Ranking-based Policy Learning
Jul 26, 2022
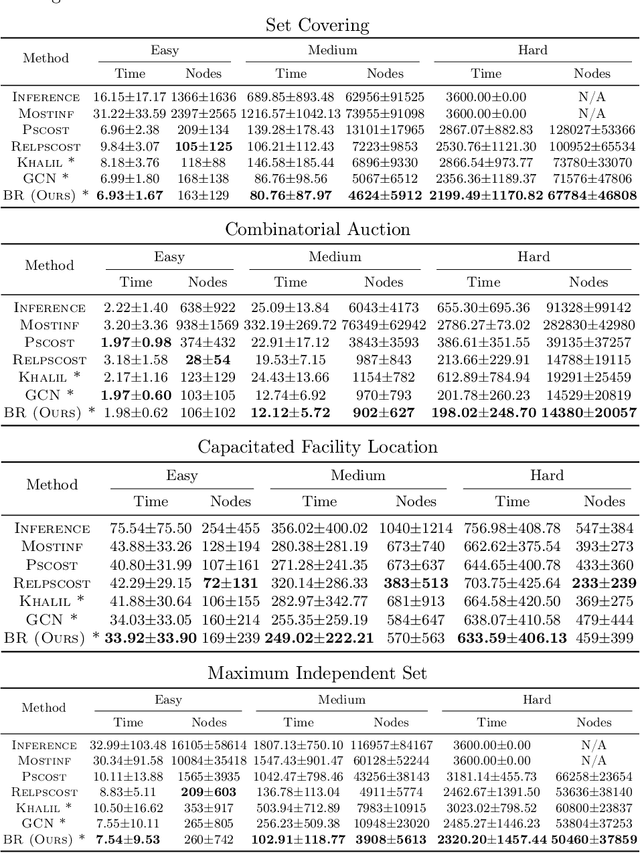
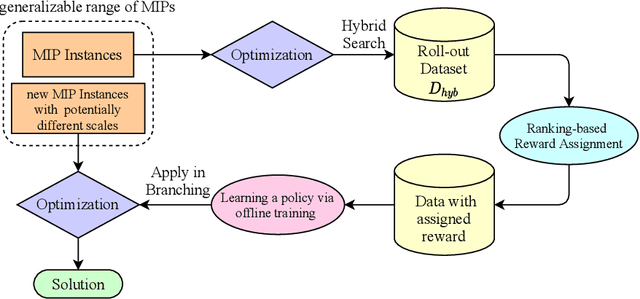

Deriving a good variable selection strategy in branch-and-bound is essential for the efficiency of modern mixed-integer programming (MIP) solvers. With MIP branching data collected during the previous solution process, learning to branch methods have recently become superior over heuristics. As branch-and-bound is naturally a sequential decision making task, one should learn to optimize the utility of the whole MIP solving process instead of being myopic on each step. In this work, we formulate learning to branch as an offline reinforcement learning (RL) problem, and propose a long-sighted hybrid search scheme to construct the offline MIP dataset, which values the long-term utilities of branching decisions. During the policy training phase, we deploy a ranking-based reward assignment scheme to distinguish the promising samples from the long-term or short-term view, and train the branching model named Branch Ranking via offline policy learning. Experiments on synthetic MIP benchmarks and real-world tasks demonstrate that Branch Rankink is more efficient and robust, and can better generalize to large scales of MIP instances compared to the widely used heuristics and state-of-the-art learning-based branching models.
A simple normalization technique using window statistics to improve the out-of-distribution generalization on medical images
Jul 14, 2022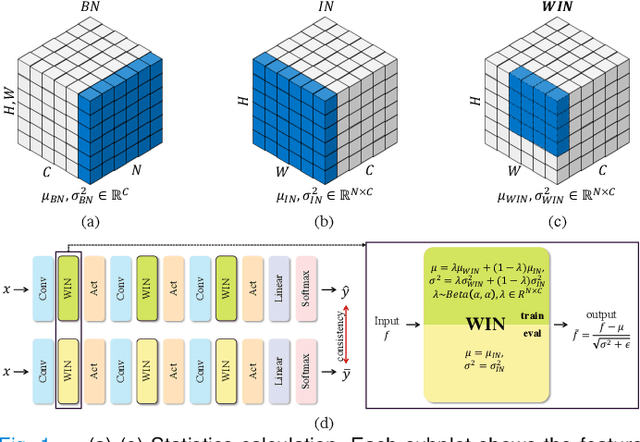
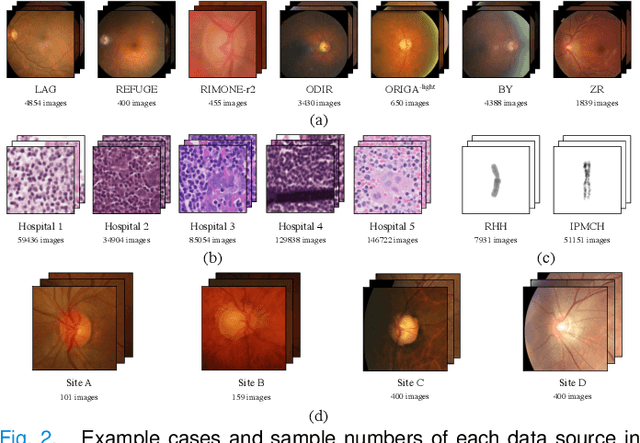

Since data scarcity and data heterogeneity are prevailing for medical images, well-trained Convolutional Neural Networks (CNNs) using previous normalization methods may perform poorly when deployed to a new site. However, a reliable model for real-world clinical applications should be able to generalize well both on in-distribution (IND) and out-of-distribution (OOD) data (e.g., the new site data). In this study, we present a novel normalization technique called window normalization (WIN) to improve the model generalization on heterogeneous medical images, which is a simple yet effective alternative to existing normalization methods. Specifically, WIN perturbs the normalizing statistics with the local statistics computed on the window of features. This feature-level augmentation technique regularizes the models well and improves their OOD generalization significantly. Taking its advantage, we propose a novel self-distillation method called WIN-WIN for classification tasks. WIN-WIN is easily implemented with twice forward passes and a consistency constraint, which can be a simple extension for existing methods. Extensive experimental results on various tasks (6 tasks) and datasets (24 datasets) demonstrate the generality and effectiveness of our methods.
Fully Decentralized Model-based Policy Optimization for Networked Systems
Jul 13, 2022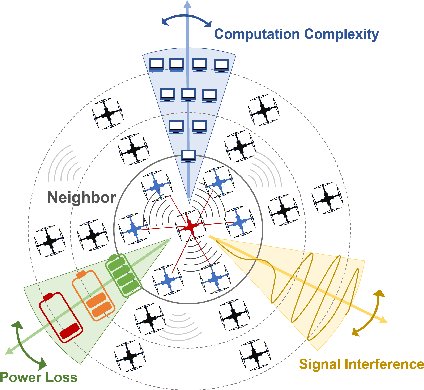
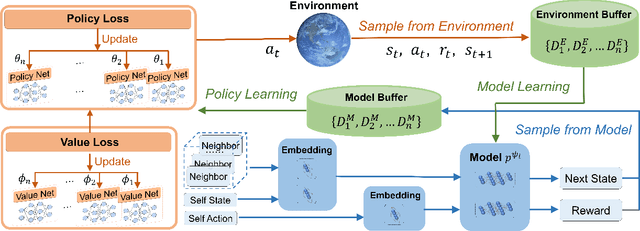
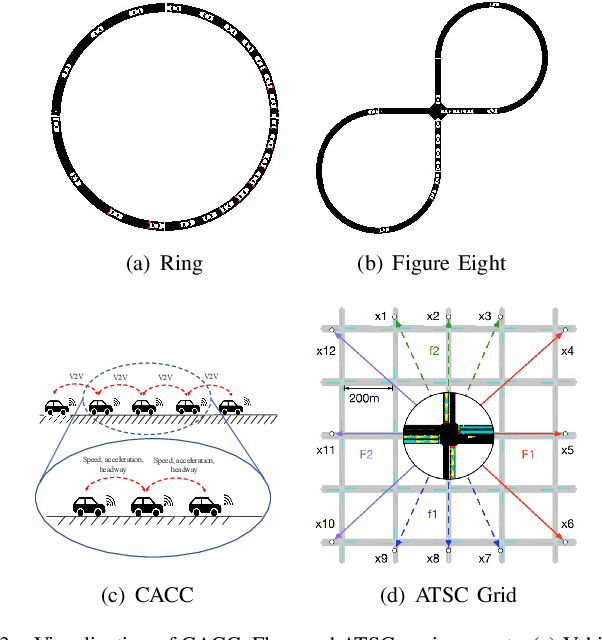
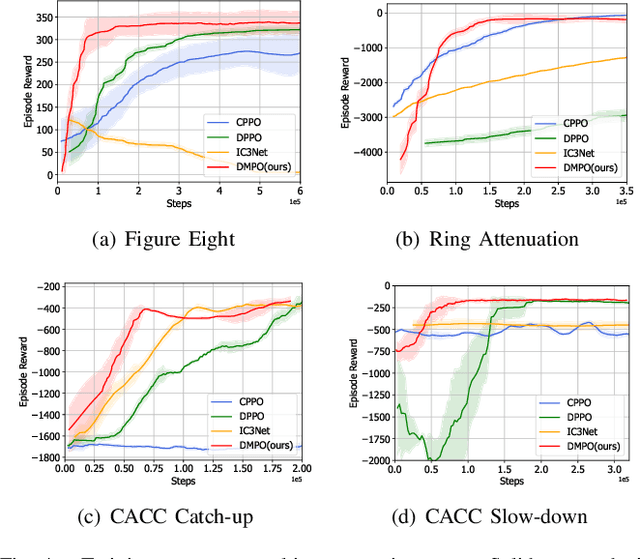
Reinforcement learning algorithms require a large amount of samples; this often limits their real-world applications on even simple tasks. Such a challenge is more outstanding in multi-agent tasks, as each step of operation is more costly requiring communications or shifting or resources. This work aims to improve data efficiency of multi-agent control by model-based learning. We consider networked systems where agents are cooperative and communicate only locally with their neighbors, and propose the decentralized model-based policy optimization framework (DMPO). In our method, each agent learns a dynamic model to predict future states and broadcast their predictions by communication, and then the policies are trained under the model rollouts. To alleviate the bias of model-generated data, we restrain the model usage for generating myopic rollouts, thus reducing the compounding error of model generation. To pertain the independence of policy update, we introduce extended value function and theoretically prove that the resulting policy gradient is a close approximation to true policy gradients. We evaluate our algorithm on several benchmarks for intelligent transportation systems, which are connected autonomous vehicle control tasks (Flow and CACC) and adaptive traffic signal control (ATSC). Empirically results show that our method achieves superior data efficiency and matches the performance of model-free methods using true models.