 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stages attention Breast cancer classification based on nonlinear spiking neural P neurons with autapses
Jan 04, 2024



Breast cancer(BC) is a prevalent type of malignant tumor in women. Early diagnosis and treatment are vital for enhancing the patients' survival rate. Downsampling in deep networks may lead to loss of information, so for compensating the detail and edge information and allowing convolutional neural networks to pay more attention to seek the lesion region, we propose a multi-stages attention architecture based on NSNP neurons with autapses. First, unlike the single-scale attention acquisition methods of existing methods, we set up spatial attention acquisition at each feature map scale of the convolutional network to obtain an fusion global information on attention guidance. Then we introduce a new type of NSNP variants called NSNP neurons with autapses. Specifically, NSNP systems are modularized as feature encoders, recoding the features extracted from convolutional neural network as well as the fusion of attention information and preserve the key characteristic elements in feature maps. This ensures the retention of valuable data while gradually transforming high-dimensional complicated info into low-dimensional ones. The proposed method is evaluated on the public dataset BreakHis at various magnifications and classification tasks. It achieves a classification accuracy of 96.32% at all magnification cases, outperforming state-of-the-art methods. Ablation studies are also performed, verifying the proposed model's efficacy. The source code is available at XhuBobYoung/Breast-cancer-Classification.
SLP-Net:An efficient lightweight network for segmentation of skin lesions
Jan 04, 2024Prompt treatment for melanoma is crucial. To assist physicians in identifying lesion areas precisely in a quick manner, we propose a novel skin lesion segmentation technique namely SLP-Net, an ultra-lightweight segmentation network based on the spiking neural P(SNP) systems type mechanism. Most existing convolutional neural networks achieve high segmentation accuracy while neglecting the high hardware cost. SLP-Net, on the contrary, has a very small number of parameters and a high computation speed. We design a lightweight multi-scale feature extractor without the usual encoder-decoder structure. Rather than a decoder, a feature adaptation module is designed to replace it and implement multi-scale information decoding. Experiments at the ISIC2018 challenge demonstrate that the proposed model has the highest Acc and DSC among the state-of-the-art methods, while experiments on the PH2 dataset also demonstrate a favorable generalization ability. Finally, we compare the computational complexity as well as the computational speed of the models in experiments, where SLP-Net has the highest overall superiority
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Jan 04, 2024



The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.
Learning-based agricultural management in partially observable environments subject to climate variability
Jan 02, 2024Agricultural management, with a particular focus on fertilization strategies, holds a central role in shaping crop yield, economic profitability, and environmental sustainability. While conventional guidelines offer valuable insights, their efficacy diminishes when confronted with extreme weather conditions, such as heatwaves and droughts. In this study, we introduce an innovative framework that integrates Deep Reinforcement Learning (DRL) with Recurrent Neural Networks (RNNs). Leveraging the Gym-DSSAT simulator, we train an intelligent agent to master optimal nitrogen fertilization management. Through a series of simulation experiments conducted on corn crops in Iowa, we compare Partially Observable Markov Decision Process (POMDP) models with Markov Decision Process (MDP) models. Our research underscores the advantages of utilizing sequential observations in developing more efficient nitrogen input policies. Additionally, we explore the impact of climate variability, particularly during extreme weather events, on agricultural outcomes and management. Our findings demonstrate the adaptability of fertilization policies to varying climate conditions. Notably, a fixed policy exhibits resilience in the face of minor climate fluctuations, leading to commendable corn yields, cost-effectiveness, and environmental conservation. However, our study illuminates the need for agent retraining to acquire new optimal policies under extreme weather events. This research charts a promising course toward adaptable fertilization strategies that can seamlessly align with dynamic climate scenarios, ultimately contributing to the optimization of crop management practices.
Maximum Likelihood CFO Estimation for High-Mobility OFDM Systems: A Chinese Remainder Theorem Based Method
Dec 27, 2023Orthogonal frequency division multiplexing (OFDM) is a widely adopted wireless communication technique but is sensitive to the carrier frequency offset (CFO). For high-mobility environments, severe Doppler shifts cause the CFO to extend well beyond the subcarrier spacing. Traditional algorithms generally estimate the integer and fractional parts of the CFO separately, which is time-consuming and requires high additional computations. To address these issues, this paper proposes a Chinese remainder theorem-based CFO Maximum Likelihood Estimation (CCMLE) approach for jointly estimating the integer and fractional parts. With CCMLE, the MLE of the CFO can be obtained directly from multiple estimates of sequences with varying lengths. This approach can achieve a wide estimation range up to the total number of subcarriers, without significant additional computations. Furthermore, we show that the CCMLE can approach the Cram$\acute{\text{e}}$r-Rao Bound (CRB), and give an analytic expression for the signal-to-noise ratio (SNR) threshold approaching the CRB, enabling an efficient waveform design. Accordingly, a parameter configuration guideline for the CCMLE is presented to achieve a better MSE performance and a lower SNR threshold. Finally, experiments show that our proposed method is highly consistent with the theoretical analysis and advantageous regarding estimated range and error performance compared to baselines.
Enhanced Latent Multi-view Subspace Clustering
Dec 22, 2023Latent multi-view subspace clustering has been demonstrated to have desirable clustering performance. However, the original latent representation method vertically concatenates the data matrices from multiple views into a single matrix along the direction of dimensionality to recover the latent representation matrix, which may result in an incomplete information recovery. To fully recover the latent space representation, we in this paper propose an Enhanced Latent Multi-view Subspace Clustering (ELMSC) method. The ELMSC method involves constructing an augmented data matrix that enhances the representation of multi-view data. Specifically, we stack the data matrices from various views into the block-diagonal locations of the augmented matrix to exploit the complementary information. Meanwhile, the non-block-diagonal entries are composed based on the similarity between different views to capture the consistent information. In addition, we enforce a sparse regularization for the non-diagonal blocks of the augmented self-representation matrix to avoid redundant calculations of consistency information. Finally, a novel iterative algorithm based on the framework of Alternating Direction Method of Multipliers (ADMM) is developed to solve the optimization problem for ELMSC. Extensive experiments on real-world datasets demonstrate that our proposed ELMSC is able to achieve higher clustering performance than some state-of-art multi-view clustering methods.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Decoupling Representation and Knowledge for Few-Shot Intent Classification and Slot Filling
Dec 21, 2023

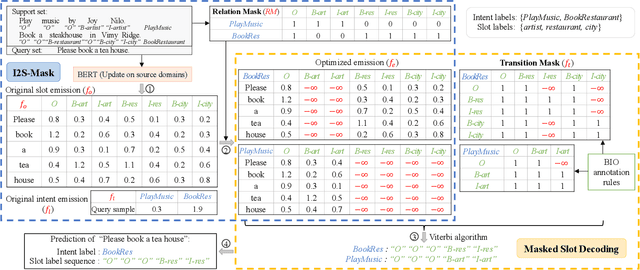
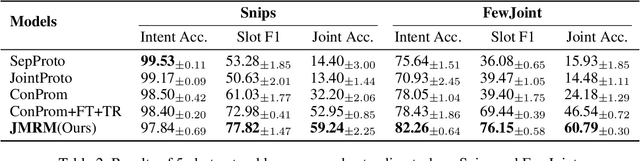
Few-shot intent classification and slot filling are important but challenging tasks due to the scarcity of finely labeled data. Therefore, current works first train a model on source domains with sufficiently labeled data, and then transfer the model to target domains where only rarely labeled data is available. However, experience transferring as a whole usually suffers from gaps that exist among source domains and target domains. For instance, transferring domain-specific-knowledge-related experience is difficult. To tackle this problem, we propose a new method that explicitly decouples the transferring of general-semantic-representation-related experience and the domain-specific-knowledge-related experience. Specifically, for domain-specific-knowledge-related experience, we design two modules to capture intent-slot relation and slot-slot relation respectively. Extensive experiments on Snips and FewJoint datasets show that our method achieves state-of-the-art performance. The method improves the joint accuracy metric from 27.72% to 42.20% in the 1-shot setting, and from 46.54% to 60.79% in the 5-shot setting.
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
Dec 19, 2023
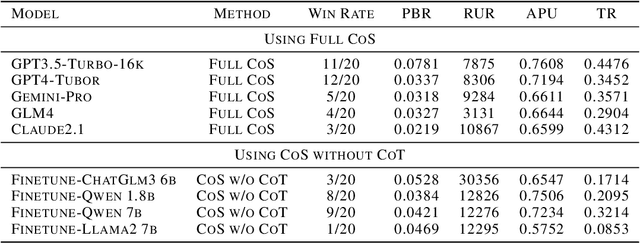


StarCraft II is a challenging benchmark for AI agents due to the necessity of both precise micro level operations and strategic macro awareness. Previous works, such as Alphastar and SCC, achieve impressive performance on tackling StarCraft II , however, still exhibit deficiencies in long term strategic planning and strategy interpretability. Emerging large language model (LLM) agents, such as Voyage and MetaGPT, presents the immense potential in solving intricate tasks. Motivated by this, we aim to validate the capabilities of LLMs on StarCraft II, a highly complex RTS game.To conveniently take full advantage of LLMs` reasoning abilities, we first develop textual StratCraft II environment, called TextStarCraft II, which LLM agent can interact. Secondly, we propose a Chain of Summarization method, including single frame summarization for processing raw observations and multi frame summarization for analyzing game information, providing command recommendations, and generating strategic decisions. Our experiment consists of two parts: first, an evaluation by human experts, which includes assessing the LLMs`s mastery of StarCraft II knowledge and the performance of LLM agents in the game; second, the in game performance of LLM agents, encompassing aspects like win rate and the impact of Chain of Summarization.Experiment results demonstrate that: 1. LLMs possess the relevant knowledge and complex planning abilities needed to address StarCraft II scenarios; 2. Human experts consider the performance of LLM agents to be close to that of an average player who has played StarCraft II for eight years; 3. LLM agents are capable of defeating the built in AI at the Harder(Lv5) difficulty level. We have open sourced the code and released demo videos of LLM agent playing StarCraft II.
DMT: Comprehensive Distillation with Multiple Self-supervised Teachers
Dec 19, 2023Numerous self-supervised learning paradigms, such as contrastive learning and masked image modeling, have been proposed to acquire powerful and general representations from unlabeled data. However, these models are commonly pretrained within their specific framework alone, failing to consider the complementary nature of visual representations. To tackle this issue, we introduce Comprehensive Distillation with Multiple Self-supervised Teachers (DMT) for pretrained model compression, which leverages the strengths of multiple off-the-shelf self-supervised models. Our experimental results on prominent benchmark datasets exhibit that the proposed method significantly surpasses state-of-the-art competitors while retaining favorable efficiency metrics. On classification tasks, our DMT framework utilizing three different self-supervised ViT-Base teachers enhances the performance of both small/tiny models and the base model itself. For dense tasks, DMT elevates the AP/mIoU of standard SSL models on MS-COCO and ADE20K datasets by 4.0%.