 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMs Play StarCraft II: A Benchmark and Multimodal Decision Method
Mar 07, 2025We introduce VLM-Attention, a multimodal StarCraft II environment that aligns artificial agent perception with the human gameplay experience. Traditional frameworks such as SMAC rely on abstract state representations that diverge significantly from human perception, limiting the ecological validity of agent behavior. Our environment addresses this limitation by incorporating RGB visual inputs and natural language observations that more closely simulate human cognitive processes during gameplay. The VLM-Attention framework consists of three integrated components: (1) a vision-language model enhanced with specialized self-attention mechanisms for strategic unit targeting and battlefield assessment, (2) a retrieval-augmented generation system that leverages domain-specific StarCraft II knowledge to inform tactical decisions, and (3) a dynamic role-based task distribution system that enables coordinated multi-agent behavior. Our experimental evaluation across 21 custom scenarios demonstrates that VLM-based agents powered by foundation models (specifically Qwen-VL and GPT-4o) can execute complex tactical maneuvers without explicit training, achieving comparable performance to traditional MARL methods that require substantial training iterations. This work establishes a foundation for developing human-aligned StarCraft II agents and advances the broader research agenda of multimodal game AI. Our implementation is available at https://github.com/camel-ai/VLM-Play-StarCraft2.
SMAC-Hard: Enabling Mixed Opponent Strategy Script and Self-play on SMAC
Dec 24, 2024The availability of challenging simulation environments is pivotal for advancing the field of Multi-Agent Reinforcement Learning (MARL). In cooperative MARL settings, the StarCraft Multi-Agent Challenge (SMAC) has gained prominence as a benchmark for algorithms following centralized training with decentralized execution paradigm. However, with continual advancements in SMAC, many algorithms now exhibit near-optimal performance, complicating the evaluation of their true effectiveness. To alleviate this problem, in this work, we highlight a critical issue: the default opponent policy in these environments lacks sufficient diversity, leading MARL algorithms to overfit and exploit unintended vulnerabilities rather than learning robust strategies. To overcome these limitations, we propose SMAC-HARD, a novel benchmark designed to enhance training robustness and evaluation comprehensiveness. SMAC-HARD supports customizable opponent strategies, randomization of adversarial policies, and interfaces for MARL self-play, enabling agents to generalize to varying opponent behaviors and improve model stability. Furthermore, we introduce a black-box testing framework wherein agents are trained without exposure to the edited opponent scripts but are tested against these scripts to evaluate the policy coverage and adaptability of MARL algorithms. We conduct extensive evaluations of widely used and state-of-the-art algorithms on SMAC-HARD, revealing the substantial challenges posed by edited and mixed strategy opponents. Additionally, the black-box strategy tests illustrate the difficulty of transferring learned policies to unseen adversaries. We envision SMAC-HARD as a critical step toward benchmarking the next generation of MARL algorithms, fostering progress in self-play methods for multi-agent systems. Our code is available at https://github.com/devindeng94/smac-hard.
A New Approach to Solving SMAC Task: Generating Decision Tree Code from Large Language Models
Oct 21, 2024StarCraft Multi-Agent Challenge (SMAC) is one of the most commonly used experimental environments in multi-agent reinforcement learning (MARL), where the specific task is to control a set number of allied units to defeat enemy forces. Traditional MARL algorithms often require interacting with the environment for up to 1 million steps to train a model, and the resulting policies are typically non-interpretable with weak transferability. In this paper, we propose a novel approach to solving SMAC tasks called LLM-SMAC. In our framework, agents leverage large language models (LLMs) to generate decision tree code by providing task descriptions. The model is further self-reflection using feedback from the rewards provided by the environment. We conduct experiments in the SMAC and demonstrate that our method can produce high-quality, interpretable decision trees with minimal environmental exploration. Moreover, these models exhibit strong transferability, successfully applying to similar SMAC environments without modification. We believe this approach offers a new direction for solving decision-making tasks in the future.
Token-level Direct Preference Optimization
Apr 18, 2024



Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
Dec 19, 2023
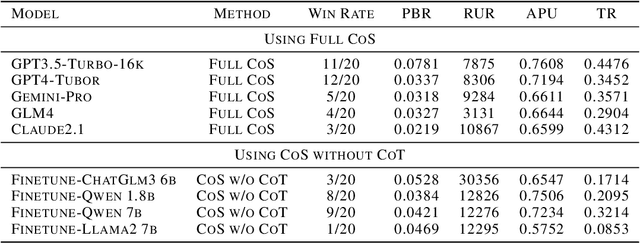


StarCraft II is a challenging benchmark for AI agents due to the necessity of both precise micro level operations and strategic macro awareness. Previous works, such as Alphastar and SCC, achieve impressive performance on tackling StarCraft II , however, still exhibit deficiencies in long term strategic planning and strategy interpretability. Emerging large language model (LLM) agents, such as Voyage and MetaGPT, presents the immense potential in solving intricate tasks. Motivated by this, we aim to validate the capabilities of LLMs on StarCraft II, a highly complex RTS game.To conveniently take full advantage of LLMs` reasoning abilities, we first develop textual StratCraft II environment, called TextStarCraft II, which LLM agent can interact. Secondly, we propose a Chain of Summarization method, including single frame summarization for processing raw observations and multi frame summarization for analyzing game information, providing command recommendations, and generating strategic decisions. Our experiment consists of two parts: first, an evaluation by human experts, which includes assessing the LLMs`s mastery of StarCraft II knowledge and the performance of LLM agents in the game; second, the in game performance of LLM agents, encompassing aspects like win rate and the impact of Chain of Summarization.Experiment results demonstrate that: 1. LLMs possess the relevant knowledge and complex planning abilities needed to address StarCraft II scenarios; 2. Human experts consider the performance of LLM agents to be close to that of an average player who has played StarCraft II for eight years; 3. LLM agents are capable of defeating the built in AI at the Harder(Lv5) difficulty level. We have open sourced the code and released demo videos of LLM agent playing StarCraft II.