 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioinspired Sensing of Undulatory Flow Fields Generated by Leg Kicks in Swimming
Mar 10, 2025



The artificial lateral line (ALL) is a bioinspired flow sensing system for underwater robots, comprising of distributed flow sensors. The ALL has been successfully applied to detect the undulatory flow fields generated by body undulation and tail-flapping of bioinspired robotic fish. However, its feasibility and performance in sensing the undulatory flow fields produced by human leg kicks during swimming has not been systematically tested and studied. This paper presents a novel sensing framework to investigate the undulatory flow field generated by swimmer's leg kicks, leveraging bioinspired ALL sensing. To evaluate the feasibility of using the ALL system for sensing the undulatory flow fields generated by swimmer leg kicks, this paper designs an experimental platform integrating an ALL system and a lab-fabricated human leg model. To enhance the accuracy of flow sensing, this paper proposes a feature extraction method that dynamically fuses time-domain and time-frequency characteristics. Specifically, time-domain features are extracted using one-dimensional convolutional neural networks and bidirectional long short-term memory networks (1DCNN-BiLSTM), while time-frequency features are extracted using short-term Fourier transform and two-dimensional convolutional neural networks (STFT-2DCNN). These features are then dynamically fused based on attention mechanisms to achieve accurate sensing of the undulatory flow field. Furthermore, extensive experiments are conducted to test various scenarios inspired by human swimming, such as leg kick pattern recognition and kicking leg localization, achieving satisfactory results.
Embodied multi-modal sensing with a soft modular arm powered by physical reservoir computing
Mar 09, 2025Soft robots have become increasingly popular for complex manipulation tasks requiring gentle and safe contact. However, their softness makes accurate control challenging, and high-fidelity sensing is a prerequisite to adequate control performance. To this end, many flexible and embedded sensors have been created over the past decade, but they inevitably increase the robot's complexity and stiffness. This study demonstrates a novel approach that uses simple bending strain gauges embedded inside a modular arm to extract complex information regarding its deformation and working conditions. The core idea is based on physical reservoir computing (PRC): A soft body's rich nonlinear dynamic responses, captured by the inter-connected bending sensor network, could be utilized for complex multi-modal sensing with a simple linear regression algorithm. Our results show that the soft modular arm reservoir can accurately predict body posture (bending angle), estimate payload weight, determine payload orientation, and even differentiate two payloads with only minimal difference in weight -- all using minimal digital computing power.
Breaking Free from MMI: A New Frontier in Rationalization by Probing Input Utilization
Mar 08, 2025



Extracting a small subset of crucial rationales from the full input is a key problem in explainability research. The most widely used fundamental criterion for rationale extraction is the maximum mutual information (MMI) criterion. In this paper, we first demonstrate that MMI suffers from diminishing marginal returns. Once part of the rationale has been identified, finding the remaining portions contributes only marginally to increasing the mutual information, making it difficult to use MMI to locate the rest. In contrast to MMI that aims to reproduce the prediction, we seek to identify the parts of the input that the network can actually utilize. This is achieved by comparing how different rationale candidates match the capability space of the weight matrix. The weight matrix of a neural network is typically low-rank, meaning that the linear combinations of its column vectors can only cover part of the directions in a high-dimensional space (high-dimension: the dimensions of an input vector). If an input is fully utilized by the network, {it generally matches these directions (e.g., a portion of a hypersphere), resulting in a representation with a high norm. Conversely, if an input primarily falls outside (orthogonal to) these directions}, its representation norm will approach zero, behaving like noise that the network cannot effectively utilize. Building on this, we propose using the norms of rationale candidates as an alternative objective to MMI. Through experiments on four text classification datasets and one graph classification dataset using three network architectures (GRUs, BERT, and GCN), we show that our method outperforms MMI and its improved variants in identifying better rationales. We also compare our method with a representative LLM (llama-3.1-8b-instruct) and find that our simple method gets comparable results to it and can sometimes even outperform it.
DB-Explore: Automated Database Exploration and Instruction Synthesis for Text-to-SQL
Mar 06, 2025Recent text-to-SQL systems powered by large language models (LLMs) have demonstrated remarkable performance in translating natural language queries into SQL. However, these systems often struggle with complex database structures and domain-specific queries, as they primarily focus on enhancing logical reasoning and SQL syntax while overlooking the critical need for comprehensive database understanding. To address this limitation, we propose DB-Explore, a novel framework that systematically aligns LLMs with database knowledge through automated exploration and instruction synthesis. DB-Explore constructs database graphs to capture complex relational schemas, leverages GPT-4 to systematically mine structural patterns and semantic knowledge, and synthesizes instructions to distill this knowledge for efficient fine-tuning of LLMs. Our framework enables comprehensive database understanding through diverse sampling strategies and automated instruction generation, bridging the gap between database structures and language models. Experiments conducted on the SPIDER and BIRD benchmarks validate the effectiveness of DB-Explore, achieving an execution accuracy of 52.1% on BIRD and 84.0% on SPIDER. Notably, our open-source implementation, based on the Qwen2.5-coder-7B model, outperforms multiple GPT-4-driven text-to-SQL systems in comparative evaluations, and achieves near state-of-the-art performance with minimal computational cost.
AskToAct: Enhancing LLMs Tool Use via Self-Correcting Clarification
Mar 03, 2025Large language models (LLMs) have demonstrated remarkable capabilities in tool learning. In real-world scenarios, user queries are often ambiguous and incomplete, requiring effective clarification. However, existing interactive clarification approaches face two critical limitations: reliance on manually constructed datasets and lack of error correction mechanisms during multi-turn clarification. We present AskToAct, which addresses these challenges by exploiting the structural mapping between queries and their tool invocation solutions. Our key insight is that tool parameters naturally represent explicit user intents. By systematically removing key parameters from queries while retaining them as ground truth, we enable automated construction of high-quality training data. We further enhance model robustness by fine-tuning on error-correction augmented data using selective masking mechanism, enabling dynamic error detection during clarification interactions. Comprehensive experiments demonstrate that AskToAct significantly outperforms existing approaches, achieving above 79% accuracy in recovering critical unspecified intents and enhancing clarification efficiency by an average of 48.34% while maintaining high accuracy in tool invocation. Our framework exhibits robust performance across varying complexity levels and successfully generalizes to entirely unseen APIs without additional training, achieving performance comparable to GPT-4 with substantially fewer computational resources.
Noise-Injected Spiking Graph Convolution for Energy-Efficient 3D Point Cloud Denoising
Feb 27, 2025



Spiking neural networks (SNNs), inspired by the spiking computation paradigm of the biological neural systems, have exhibited superior energy efficiency in 2D classification tasks over traditional artificial neural networks (ANNs). However, the regression potential of SNNs has not been well explored, especially in 3D point cloud processing.In this paper, we propose noise-injected spiking graph convolutional networks to leverage the full regression potential of SNNs in 3D point cloud denoising. Specifically, we first emulate the noise-injected neuronal dynamics to build noise-injected spiking neurons. On this basis, we design noise-injected spiking graph convolution for promoting disturbance-aware spiking representation learning on 3D points. Starting from the spiking graph convolution, we build two SNN-based denoising networks. One is a purely spiking graph convolutional network, which achieves low accuracy loss compared with some ANN-based alternatives, while resulting in significantly reduced energy consumption on two benchmark datasets, PU-Net and PC-Net. The other is a hybrid architecture that combines ANN-based learning with a high performance-efficiency trade-off in just a few time steps. Our work lights up SNN's potential for 3D point cloud denoising, injecting new perspectives of exploring the deployment on neuromorphic chips while paving the way for developing energy-efficient 3D data acquisition devices.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025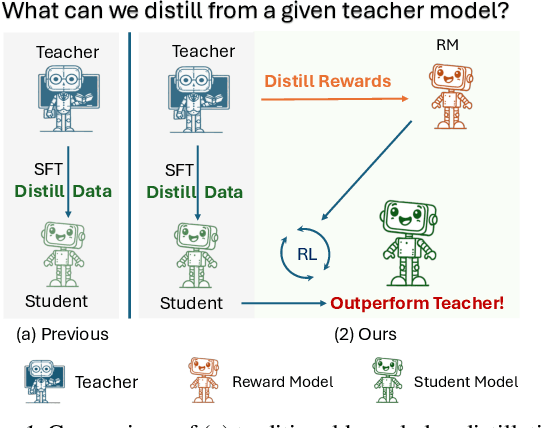

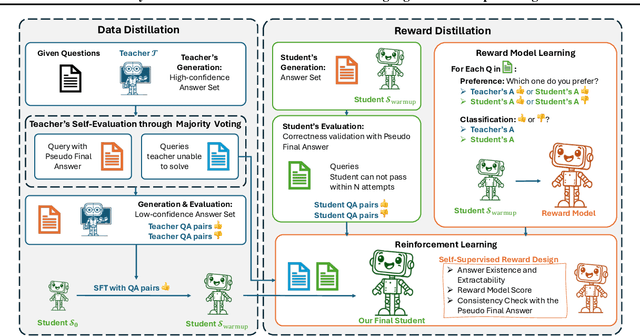
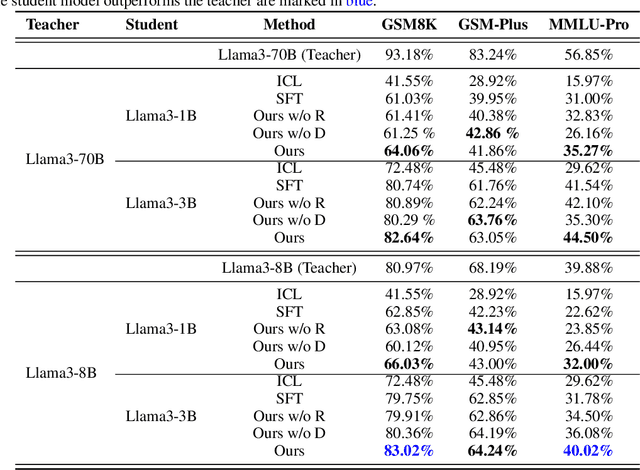
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
Generative Models in Decision Making: A Survey
Feb 25, 2025In recent years, the exceptional performance of generative models in generative tasks has sparked significant interest in their integration into decision-making processes. Due to their ability to handle complex data distributions and their strong model capacity, generative models can be effectively incorporated into decision-making systems by generating trajectories that guide agents toward high-reward state-action regions or intermediate sub-goals. This paper presents a comprehensive review of the application of generative models in decision-making tasks. We classify seven fundamental types of generative models: energy-based models, generative adversarial networks, variational autoencoders, normalizing flows, diffusion models, generative flow networks, and autoregressive models. Regarding their applications, we categorize their functions into three main roles: controllers, modelers and optimizers, and discuss how each role contributes to decision-making. Furthermore, we examine the deployment of these models across five critical real-world decision-making scenarios. Finally, we summarize the strengths and limitations of current approaches and propose three key directions for advancing next-generation generative directive models: high-performance algorithms, large-scale generalized decision-making models, and self-evolving and adaptive models.
Joint Similarity Item Exploration and Overlapped User Guidance for Multi-Modal Cross-Domain Recommendation
Feb 22, 2025Cross-Domain Recommendation (CDR) has been widely investigated for solving long-standing data sparsity problem via knowledge sharing across domains. In this paper, we focus on the Multi-Modal Cross-Domain Recommendation (MMCDR) problem where different items have multi-modal information while few users are overlapped across domains. MMCDR is particularly challenging in two aspects: fully exploiting diverse multi-modal information within each domain and leveraging useful knowledge transfer across domains. However, previous methods fail to cluster items with similar characteristics while filtering out inherit noises within different modalities, hurdling the model performance. What is worse, conventional CDR models primarily rely on overlapped users for domain adaptation, making them ill-equipped to handle scenarios where the majority of users are non-overlapped. To fill this gap, we propose Joint Similarity Item Exploration and Overlapped User Guidance (SIEOUG) for solving the MMCDR problem. SIEOUG first proposes similarity item exploration module, which not only obtains pair-wise and group-wise item-item graph knowledge, but also reduces irrelevant noise for multi-modal modeling. Then SIEOUG proposes user-item collaborative filtering module to aggregate user/item embeddings with the attention mechanism for collaborative filtering. Finally SIEOUG proposes overlapped user guidance module with optimal user matching for knowledge sharing across domains. Our empirical study on Amazon dataset with several different tasks demonstrates that SIEOUG significantly outperforms the state-of-the-art models under the MMCDR setting.
Motion-Coupled Mapping Algorithm for Hybrid Rice Canopy
Feb 22, 2025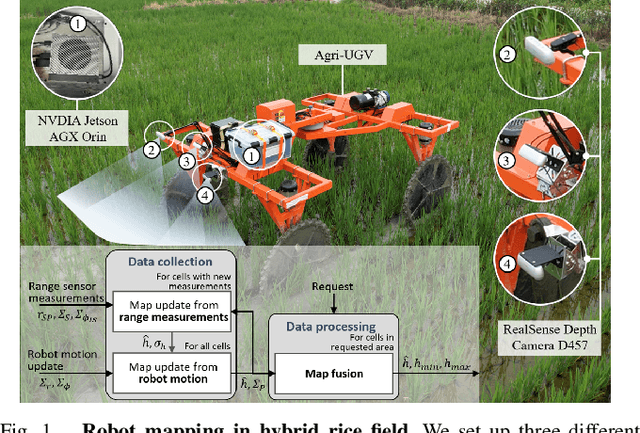
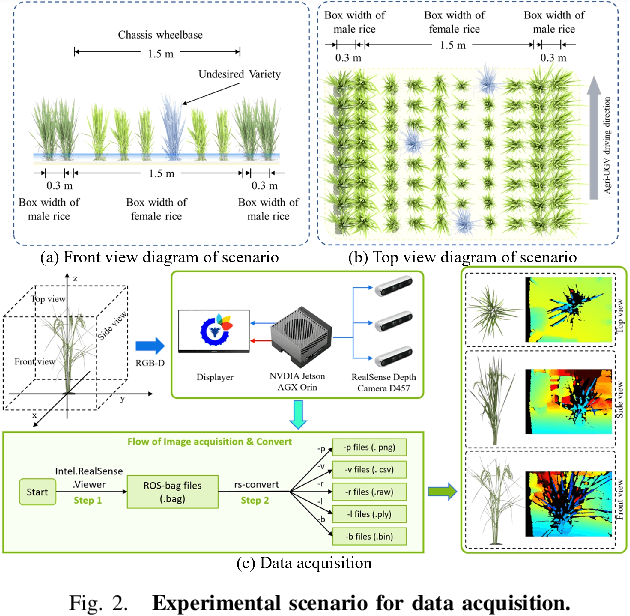
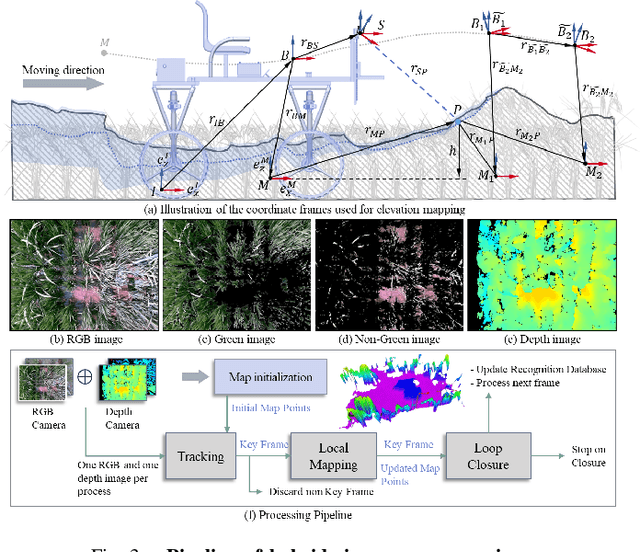
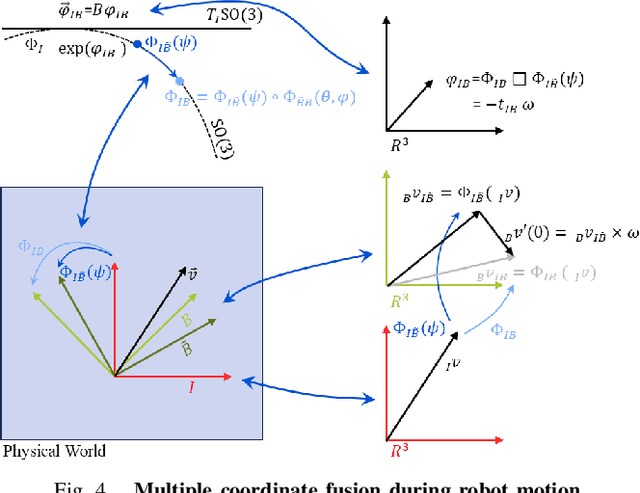
This paper presents a motion-coupled mapping algorithm for contour mapping of hybrid rice canopies, specifically designed for Agricultural Unmanned Ground Vehicles (Agri-UGV) navigating complex and unknown rice fields. Precise canopy mapping is essential for Agri-UGVs to plan efficient routes and avoid protected zones. The motion control of Agri-UGVs, tasked with impurity removal and other operations, depends heavily on accurate estimation of rice canopy height and structure. To achieve this, the proposed algorithm integrates real-time RGB-D sensor data with kinematic and inertial measurements, enabling efficient mapping and proprioceptive localization. The algorithm produces grid-based elevation maps that reflect the probabilistic distribution of canopy contours, accounting for motion-induced uncertainties. It is implemented on a high-clearance Agri-UGV platform and tested in various environments, including both controlled and dynamic rice field settings. This approach significantly enhances the mapping accuracy and operational reliability of Agri-UGVs, contributing to more efficient autonomous agricultural operations.
* Best Paper Award First Place - IROS 2024 Workshop on AI and Robotics For Future Farming