 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Navigation for Legged Manipulators with Learned Arm-Pushing Controller
Mar 03, 2025



Interactive navigation is crucial in scenarios where proactively interacting with objects can yield shorter paths, thus significantly improving traversal efficiency. Existing methods primarily focus on using the robot body to relocate large obstacles (which could be comparable to the size of a robot). However, they prove ineffective in narrow or constrained spaces where the robot's dimensions restrict its manipulation capabilities. This paper introduces a novel interactive navigation framework for legged manipulators, featuring an active arm-pushing mechanism that enables the robot to reposition movable obstacles in space-constrained environments. To this end, we develop a reinforcement learning-based arm-pushing controller with a two-stage reward strategy for large-object manipulation. Specifically, this strategy first directs the manipulator to a designated pushing zone to achieve a kinematically feasible contact configuration. Then, the end effector is guided to maintain its position at appropriate contact points for stable object displacement while preventing toppling. The simulations validate the robustness of the arm-pushing controller, showing that the two-stage reward strategy improves policy convergence and long-term performance. Real-world experiments further demonstrate the effectiveness of the proposed navigation framework, which achieves shorter paths and reduced traversal time. The open-source project can be found at https://github.com/Zhihaibi/Interactive-Navigation-for-legged-manipulator.git.
DifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025



Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
RoboDexVLM: Visual Language Model-Enabled Task Planning and Motion Control for Dexterous Robot Manipulation
Mar 03, 2025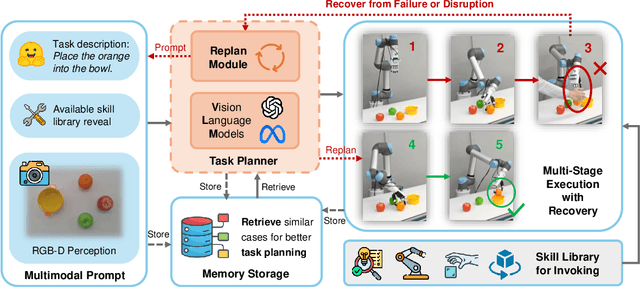
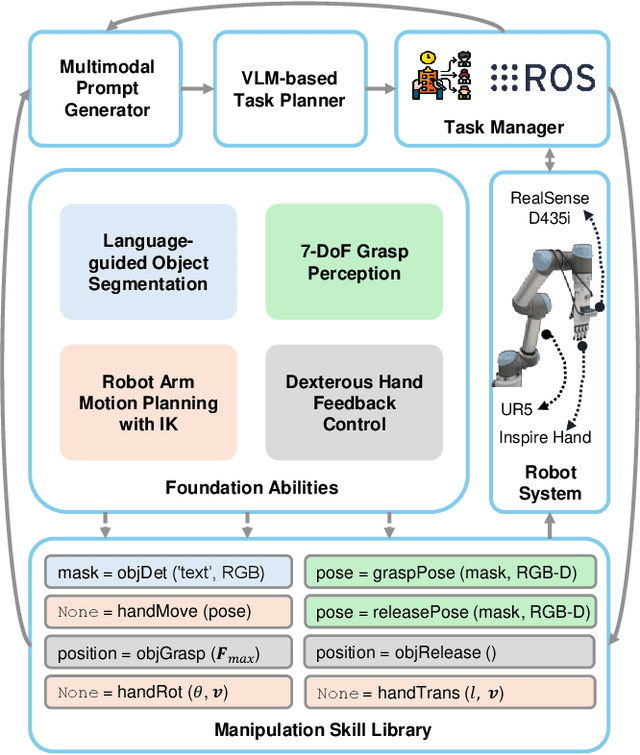
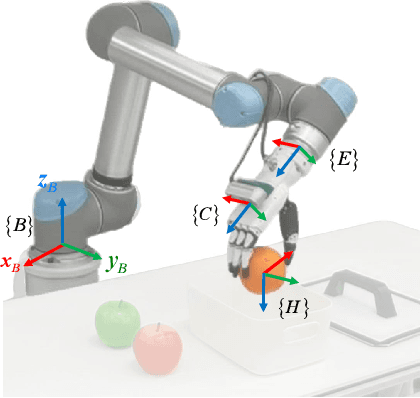

This paper introduces RoboDexVLM, an innovative framework for robot task planning and grasp detection tailored for a collaborative manipulator equipped with a dexterous hand. Previous methods focus on simplified and limited manipulation tasks, which often neglect the complexities associated with grasping a diverse array of objects in a long-horizon manner. In contrast, our proposed framework utilizes a dexterous hand capable of grasping objects of varying shapes and sizes while executing tasks based on natural language commands. The proposed approach has the following core components: First, a robust task planner with a task-level recovery mechanism that leverages vision-language models (VLMs) is designed, which enables the system to interpret and execute open-vocabulary commands for long sequence tasks. Second, a language-guided dexterous grasp perception algorithm is presented based on robot kinematics and formal methods, tailored for zero-shot dexterous manipulation with diverse objects and commands. Comprehensive experimental results validate the effectiveness, adaptability, and robustness of RoboDexVLM in handling long-horizon scenarios and performing dexterous grasping. These results highlight the framework's ability to operate in complex environments, showcasing its potential for open-vocabulary dexterous manipulation. Our open-source project page can be found at https://henryhcliu.github.io/robodexvlm.
VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion
Feb 25, 2025



Human drivers adeptly navigate complex scenarios by utilizing rich attentional semantics, but the current autonomous systems struggle to replicate this ability, as they often lose critical semantic information when converting 2D observations into 3D space. In this sense, it hinders their effective deployment in dynamic and complex environments. Leveraging the superior scene understanding and reasoning abilities of Vision-Language Models (VLMs), we propose VLM-E2E, a novel framework that uses the VLMs to enhance training by providing attentional cues. Our method integrates textual representations into Bird's-Eye-View (BEV) features for semantic supervision, which enables the model to learn richer feature representations that explicitly capture the driver's attentional semantics. By focusing on attentional semantics, VLM-E2E better aligns with human-like driving behavior, which is critical for navigating dynamic and complex environments. Furthermore, we introduce a BEV-Text learnable weighted fusion strategy to address the issue of modality importance imbalance in fusing multimodal information. This approach dynamically balances the contributions of BEV and text features, ensuring that the complementary information from visual and textual modality is effectively utilized. By explicitly addressing the imbalance in multimodal fusion, our method facilitates a more holistic and robust representation of driving environments. We evaluate VLM-E2E on the nuScenes dataset and demonstrate its superiority over state-of-the-art approaches, showcasing significant improvements in performance.
Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Feb 18, 2025



The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.
Occlusion-Aware Contingency Safety-Critical Planning for Autonomous Vehicles
Feb 10, 2025



Ensuring safe driving while maintaining travel efficiency for autonomous vehicles in dynamic and occluded environments is a critical challenge. This paper proposes an occlusion-aware contingency safety-critical planning approach for real-time autonomous driving in such environments. Leveraging reachability analysis for risk assessment, forward reachable sets of occluded phantom vehicles are computed to quantify dynamic velocity boundaries. These velocity boundaries are incorporated into a biconvex nonlinear programming (NLP) formulation, enabling simultaneous optimization of exploration and fallback trajectories within a receding horizon planning framework. To facilitate real-time optimization and ensure coordination between trajectories, we employ the consensus alternating direction method of multipliers (ADMM) to decompose the biconvex NLP problem into low-dimensional convex subproblems. The effectiveness of the proposed approach is validated through simulation studies and real-world experiments in occluded intersections. Experimental results demonstrate enhanced safety and improved travel efficiency, enabling real-time safe trajectory generation in dynamic occluded intersections under varying obstacle conditions. A video showcasing the experimental results is available at https://youtu.be/CHayG7NChqM.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
Bilevel Multi-Armed Bandit-Based Hierarchical Reinforcement Learning for Interaction-Aware Self-Driving at Unsignalized Intersections
Feb 06, 2025



In this work, we present BiM-ACPPO, a bilevel multi-armed bandit-based hierarchical reinforcement learning framework for interaction-aware decision-making and planning at unsignalized intersections. Essentially, it proactively takes the uncertainties associated with surrounding vehicles (SVs) into consideration, which encompass those stemming from the driver's intention, interactive behaviors, and the varying number of SVs. Intermediate decision variables are introduced to enable the high-level RL policy to provide an interaction-aware reference, for guiding low-level model predictive control (MPC) and further enhancing the generalization ability of the proposed framework. By leveraging the structured nature of self-driving at unsignalized intersections, the training problem of the RL policy is modeled as a bilevel curriculum learning task, which is addressed by the proposed Exp3.S-based BiMAB algorithm. It is noteworthy that the training curricula are dynamically adjusted, thereby facilitating the sample efficiency of the RL training process. Comparative experiments are conducted in the high-fidelity CARLA simulator, and the results indicate that our approach achieves superior performance compared to all baseline methods. Furthermore, experimental results in two new urban driving scenarios clearly demonstrate the commendable generalization performance of the proposed method.
Rethinking the Residual Distribution of Locate-then-Editing Methods in Model Editing
Feb 06, 2025Model editing is a powerful technique for updating the knowledge of Large Language Models (LLMs). Locate-then-edit methods are a popular class of approaches that first identify the critical layers storing knowledge, then compute the residual of the last critical layer based on the edited knowledge, and finally perform multi-layer updates using a least-squares solution by evenly distributing the residual from the first critical layer to the last. Although these methods achieve promising results, they have been shown to degrade the original knowledge of LLMs. We argue that residual distribution leads to this issue. To explore this, we conduct a comprehensive analysis of residual distribution in locate-then-edit methods from both empirical and theoretical perspectives, revealing that residual distribution introduces editing errors, leading to inaccurate edits. To address this issue, we propose the Boundary Layer UpdatE (BLUE) strategy to enhance locate-then-edit methods. Sequential batch editing experiments on three LLMs and two datasets demonstrate that BLUE not only delivers an average performance improvement of 35.59\%, significantly advancing the state of the art in model editing, but also enhances the preservation of LLMs' general capabilities. Our code is available at https://github.com/xpq-tech/BLUE.
MedRAX: Medical Reasoning Agent for Chest X-ray
Feb 04, 2025



Chest X-rays (CXRs) play an integral role in driving critical decisions in disease management and patient care. While recent innovations have led to specialized models for various CXR interpretation tasks, these solutions often operate in isolation, limiting their practical utility in clinical practice. We present MedRAX, the first versatile AI agent that seamlessly integrates state-of-the-art CXR analysis tools and multimodal large language models into a unified framework. MedRAX dynamically leverages these models to address complex medical queries without requiring additional training. To rigorously evaluate its capabilities, we introduce ChestAgentBench, a comprehensive benchmark containing 2,500 complex medical queries across 7 diverse categories. Our experiments demonstrate that MedRAX achieves state-of-the-art performance compared to both open-source and proprietary models, representing a significant step toward the practical deployment of automated CXR interpretation systems. Data and code have been publicly available at https://github.com/bowang-lab/MedRAX