 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetRoller: Interfacing General and Specialized Models for End-to-End Autonomous Driving
Jun 17, 2025Integrating General Models (GMs) such as Large Language Models (LLMs), with Specialized Models (SMs) in autonomous driving tasks presents a promising approach to mitigating challenges in data diversity and model capacity of existing specialized driving models. However, this integration leads to problems of asynchronous systems, which arise from the distinct characteristics inherent in GMs and SMs. To tackle this challenge, we propose NetRoller, an adapter that incorporates a set of novel mechanisms to facilitate the seamless integration of GMs and specialized driving models. Specifically, our mechanisms for interfacing the asynchronous GMs and SMs are organized into three key stages. NetRoller first harvests semantically rich and computationally efficient representations from the reasoning processes of LLMs using an early stopping mechanism, which preserves critical insights on driving context while maintaining low overhead. It then applies learnable query embeddings, nonsensical embeddings, and positional layer embeddings to facilitate robust and efficient cross-modality translation. At last, it employs computationally efficient Query Shift and Feature Shift mechanisms to enhance the performance of SMs through few-epoch fine-tuning. Based on the mechanisms formalized in these three stages, NetRoller enables specialized driving models to operate at their native frequencies while maintaining situational awareness of the GM. Experiments conducted on the nuScenes dataset demonstrate that integrating GM through NetRoller significantly improves human similarity and safety in planning tasks, and it also achieves noticeable precision improvements in detection and mapping tasks for end-to-end autonomous driving. The code and models are available at https://github.com/Rex-sys-hk/NetRoller .
Abstract, Align, Predict: Zero-Shot Stance Detection via Cognitive Inductive Reasoning
Jun 16, 2025Zero-shot stance detection (ZSSD) aims to identify the stance of text toward previously unseen targets, a setting where conventional supervised models often fail due to reliance on labeled data and shallow lexical cues. Inspired by human cognitive reasoning, we propose the Cognitive Inductive Reasoning Framework (CIRF), which abstracts transferable reasoning schemas from unlabeled text and encodes them as concept-level logic. To integrate these schemas with input arguments, we introduce a Schema-Enhanced Graph Kernel Model (SEGKM) that dynamically aligns local and global reasoning structures. Experiments on SemEval-2016, VAST, and COVID-19-Stance benchmarks show that CIRF establishes new state-of-the-art results, outperforming strong ZSSD baselines by 1.0, 4.5, and 3.3 percentage points in macro-F1, respectively, and achieving comparable accuracy with 70\% fewer labeled examples. We will release the full code upon publication.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
Any Large Language Model Can Be a Reliable Judge: Debiasing with a Reasoning-based Bias Detector
May 21, 2025



LLM-as-a-Judge has emerged as a promising tool for automatically evaluating generated outputs, but its reliability is often undermined by potential biases in judgment. Existing efforts to mitigate these biases face key limitations: in-context learning-based methods fail to address rooted biases due to the evaluator's limited capacity for self-reflection, whereas fine-tuning is not applicable to all evaluator types, especially closed-source models. To address this challenge, we introduce the Reasoning-based Bias Detector (RBD), which is a plug-in module that identifies biased evaluations and generates structured reasoning to guide evaluator self-correction. Rather than modifying the evaluator itself, RBD operates externally and engages in an iterative process of bias detection and feedback-driven revision. To support its development, we design a complete pipeline consisting of biased dataset construction, supervision collection, distilled reasoning-based fine-tuning of RBD, and integration with LLM evaluators. We fine-tune four sizes of RBD models, ranging from 1.5B to 14B, and observe consistent performance improvements across all scales. Experimental results on 4 bias types--verbosity, position, bandwagon, and sentiment--evaluated using 8 LLM evaluators demonstrate RBD's strong effectiveness. For example, the RBD-8B model improves evaluation accuracy by an average of 18.5% and consistency by 10.9%, and surpasses prompting-based baselines and fine-tuned judges by 12.8% and 17.2%, respectively. These results highlight RBD's effectiveness and scalability. Additional experiments further demonstrate its strong generalization across biases and domains, as well as its efficiency.
LD-Scene: LLM-Guided Diffusion for Controllable Generation of Adversarial Safety-Critical Driving Scenarios
May 16, 2025



Ensuring the safety and robustness of autonomous driving systems necessitates a comprehensive evaluation in safety-critical scenarios. However, these safety-critical scenarios are rare and difficult to collect from real-world driving data, posing significant challenges to effectively assessing the performance of autonomous vehicles. Typical existing methods often suffer from limited controllability and lack user-friendliness, as extensive expert knowledge is essentially required. To address these challenges, we propose LD-Scene, a novel framework that integrates Large Language Models (LLMs) with Latent Diffusion Models (LDMs) for user-controllable adversarial scenario generation through natural language. Our approach comprises an LDM that captures realistic driving trajectory distributions and an LLM-based guidance module that translates user queries into adversarial loss functions, facilitating the generation of scenarios aligned with user queries. The guidance module integrates an LLM-based Chain-of-Thought (CoT) code generator and an LLM-based code debugger, enhancing the controllability and robustness in generating guidance functions. Extensive experiments conducted on the nuScenes dataset demonstrate that LD-Scene achieves state-of-the-art performance in generating realistic, diverse, and effective adversarial scenarios. Furthermore, our framework provides fine-grained control over adversarial behaviors, thereby facilitating more effective testing tailored to specific driving scenarios.
DSDrive: Distilling Large Language Model for Lightweight End-to-End Autonomous Driving with Unified Reasoning and Planning
May 08, 2025We present DSDrive, a streamlined end-to-end paradigm tailored for integrating the reasoning and planning of autonomous vehicles into a unified framework. DSDrive leverages a compact LLM that employs a distillation method to preserve the enhanced reasoning capabilities of a larger-sized vision language model (VLM). To effectively align the reasoning and planning tasks, a waypoint-driven dual-head coordination module is further developed, which synchronizes dataset structures, optimization objectives, and the learning process. By integrating these tasks into a unified framework, DSDrive anchors on the planning results while incorporating detailed reasoning insights, thereby enhancing the interpretability and reliability of the end-to-end pipeline. DSDrive has been thoroughly tested in closed-loop simulations, where it performs on par with benchmark models and even outperforms in many key metrics, all while being more compact in size. Additionally, the computational efficiency of DSDrive (as reflected in its time and memory requirements during inference) has been significantly enhanced. Evidently thus, this work brings promising aspects and underscores the potential of lightweight systems in delivering interpretable and efficient solutions for AD.
ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion
Apr 22, 2025



Navigating unknown environments to find a target object is a significant challenge. While semantic information is crucial for navigation, relying solely on it for decision-making may not always be efficient, especially in environments with weak semantic cues. Additionally, many methods are susceptible to misdetections, especially in environments with visually similar objects. To address these limitations, we propose ApexNav, a zero-shot object navigation framework that is both more efficient and reliable. For efficiency, ApexNav adaptively utilizes semantic information by analyzing its distribution in the environment, guiding exploration through semantic reasoning when cues are strong, and switching to geometry-based exploration when they are weak. For reliability, we propose a target-centric semantic fusion method that preserves long-term memory of the target object and similar objects, reducing false detections and minimizing task failures. We evaluate ApexNav on the HM3Dv1, HM3Dv2, and MP3D datasets, where it outperforms state-of-the-art methods in both SR and SPL metrics. Comprehensive ablation studies further demonstrate the effectiveness of each module. Furthermore, real-world experiments validate the practicality of ApexNav in physical environments. Project page is available at https://robotics-star.com/ApexNav.
FERMI: Flexible Radio Mapping with a Hybrid Propagation Model and Scalable Autonomous Data Collection
Apr 21, 2025Communication is fundamental for multi-robot collaboration, with accurate radio mapping playing a crucial role in predicting signal strength between robots. However, modeling radio signal propagation in large and occluded environments is challenging due to complex interactions between signals and obstacles. Existing methods face two key limitations: they struggle to predict signal strength for transmitter-receiver pairs not present in the training set, while also requiring extensive manual data collection for modeling, making them impractical for large, obstacle-rich scenarios. To overcome these limitations, we propose FERMI, a flexible radio mapping framework. FERMI combines physics-based modeling of direct signal paths with a neural network to capture environmental interactions with radio signals. This hybrid model learns radio signal propagation more efficiently, requiring only sparse training data. Additionally, FERMI introduces a scalable planning method for autonomous data collection using a multi-robot team. By increasing parallelism in data collection and minimizing robot travel costs between regions, overall data collection efficiency is significantly improved. Experiments in both simulation and real-world scenarios demonstrate that FERMI enables accurate signal prediction and generalizes well to unseen positions in complex environments. It also supports fully autonomous data collection and scales to different team sizes, offering a flexible solution for creating radio maps. Our code is open-sourced at https://github.com/ymLuo1214/Flexible-Radio-Mapping.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
HM-RAG: Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation
Apr 13, 2025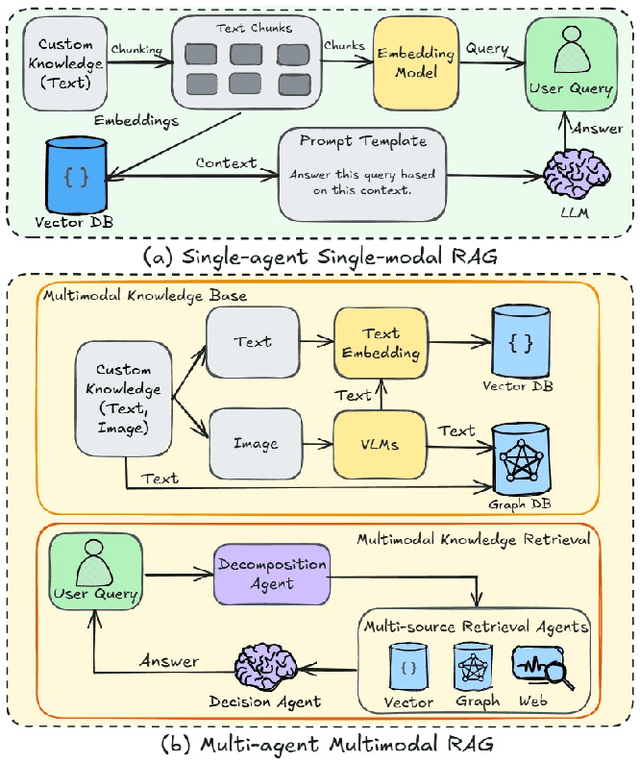
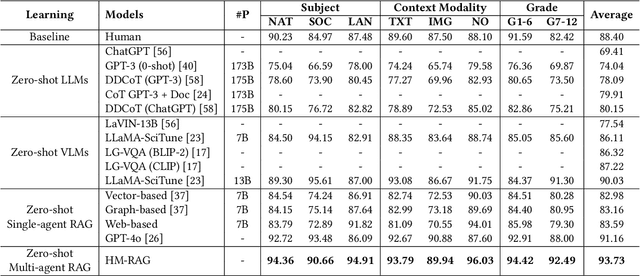
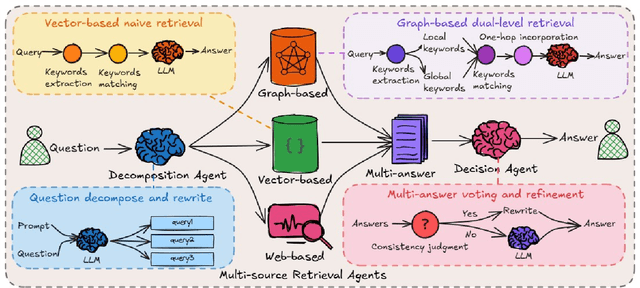
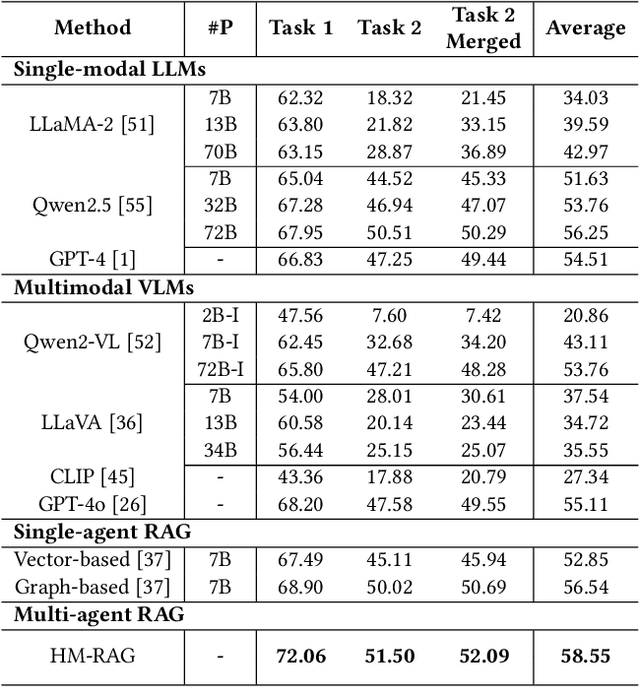
While Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge, conventional single-agent RAG remains fundamentally limited in resolving complex queries demanding coordinated reasoning across heterogeneous data ecosystems. We present HM-RAG, a novel Hierarchical Multi-agent Multimodal RAG framework that pioneers collaborative intelligence for dynamic knowledge synthesis across structured, unstructured, and graph-based data. The framework is composed of three-tiered architecture with specialized agents: a Decomposition Agent that dissects complex queries into contextually coherent sub-tasks via semantic-aware query rewriting and schema-guided context augmentation; Multi-source Retrieval Agents that carry out parallel, modality-specific retrieval using plug-and-play modules designed for vector, graph, and web-based databases; and a Decision Agent that uses consistency voting to integrate multi-source answers and resolve discrepancies in retrieval results through Expert Model Refinement. This architecture attains comprehensive query understanding by combining textual, graph-relational, and web-derived evidence, resulting in a remarkable 12.95% improvement in answer accuracy and a 3.56% boost in question classification accuracy over baseline RAG systems on the ScienceQA and CrisisMMD benchmarks. Notably, HM-RAG establishes state-of-the-art results in zero-shot settings on both datasets. Its modular architecture ensures seamless integration of new data modalities while maintaining strict data governance, marking a significant advancement in addressing the critical challenges of multimodal reasoning and knowledge synthesis in RAG systems. Code is available at https://github.com/ocean-luna/HMRAG.