 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping by Spiraling: Reproducing Elephant Movements with Rigid-Soft Robot Synergy
Apr 02, 2025The logarithmic spiral is observed as a common pattern in several living beings across kingdoms and species. Some examples include fern shoots, prehensile tails, and soft limbs like octopus arms and elephant trunks. In the latter cases, spiraling is also used for grasping. Motivated by how this strategy simplifies behavior into kinematic primitives and combines them to develop smart grasping movements, this work focuses on the elephant trunk, which is more deeply investigated in the literature. We present a soft arm combined with a rigid robotic system to replicate elephant grasping capabilities based on the combination of a soft trunk with a solid body. In our system, the rigid arm ensures positioning and orientation, mimicking the role of the elephant's head, while the soft manipulator reproduces trunk motion primitives of bending and twisting under proper actuation patterns. This synergy replicates 9 distinct elephant grasping strategies reported in the literature, accommodating objects of varying shapes and sizes. The synergistic interaction between the rigid and soft components of the system minimizes the control complexity while maintaining a high degree of adaptability.
FortisAVQA and MAVEN: a Benchmark Dataset and Debiasing Framework for Robust Multimodal Reasoning
Apr 02, 2025



Audio-Visual Question Answering (AVQA) is a challenging multimodal reasoning task requiring intelligent systems to answer natural language queries based on paired audio-video inputs accurately. However, existing AVQA approaches often suffer from overfitting to dataset biases, leading to poor robustness. Moreover, current datasets may not effectively diagnose these methods. To address these challenges, we first introduce a novel dataset, FortisAVQA, constructed in two stages: (1) rephrasing questions in the test split of the public MUSIC-AVQA dataset and (2) introducing distribution shifts across questions. The first stage expands the test space with greater diversity, while the second enables a refined robustness evaluation across rare, frequent, and overall question distributions. Second, we introduce a robust Multimodal Audio-Visual Epistemic Network (MAVEN) that leverages a multifaceted cycle collaborative debiasing strategy to mitigate bias learning. Experimental results demonstrate that our architecture achieves state-of-the-art performance on FortisAVQA, with a notable improvement of 7.81\%. Extensive ablation studies on both datasets validate the effectiveness of our debiasing components. Additionally, our evaluation reveals the limited robustness of existing multimodal QA methods. We also verify the plug-and-play capability of our strategy by integrating it with various baseline models across both datasets. Our dataset and code are available at https://github.com/reml-group/fortisavqa.
POPEN: Preference-Based Optimization and Ensemble for LVLM-Based Reasoning Segmentation
Apr 01, 2025



Existing LVLM-based reasoning segmentation methods often suffer from imprecise segmentation results and hallucinations in their text responses. This paper introduces POPEN, a novel framework designed to address these issues and achieve improved results. POPEN includes a preference-based optimization method to finetune the LVLM, aligning it more closely with human preferences and thereby generating better text responses and segmentation results. Additionally, POPEN introduces a preference-based ensemble method for inference, which integrates multiple outputs from the LVLM using a preference-score-based attention mechanism for refinement. To better adapt to the segmentation task, we incorporate several task-specific designs in our POPEN framework, including a new approach for collecting segmentation preference data with a curriculum learning mechanism, and a novel preference optimization loss to refine the segmentation capability of the LVLM. Experiments demonstrate that our method achieves state-of-the-art performance in reasoning segmentation, exhibiting minimal hallucination in text responses and the highest segmentation accuracy compared to previous advanced methods like LISA and PixelLM. Project page is https://lanyunzhu.site/POPEN/
Resource-Efficient Federated Fine-Tuning Large Language Models for Heterogeneous Data
Mar 27, 2025Fine-tuning large language models (LLMs) via federated learning, i.e., FedLLM, has been proposed to adapt LLMs for various downstream applications in a privacy-preserving way. To reduce the fine-tuning costs on resource-constrained devices, FedLoRA is proposed to fine-tune only a small subset of model parameters by integrating low-rank adaptation (LoRA) into FedLLM. However, apart from resource constraints, there is still another critical challenge, i.e., data heterogeneity, severely hindering the implementation of FedLoRA in practical applications. Herein, inspired by the previous group-based federated learning paradigm, we propose a hierarchical FedLoRA framework, termed HierFedLoRA, to address these challenges. Specifically, HierFedLoRA partitions all devices into multiple near-IID groups and adjusts the intra-group aggregation frequency for each group to eliminate the negative effects of non-IID data. Meanwhile, to reduce the computation and communication cost, HierFedLoRA dynamically assigns diverse and suitable fine-tuning depth (i.e., the number of continuous fine-tuning layers from the output) for each group. HierFedLoRA explores jointly optimizing aggregation frequency and depth upon their coupled relationship to better enhance the performance of FedLoRA. Extensive experiments are conducted on a physical platform with 80 commercial devices. The results show that HierFedLoRA improves the final model accuracy by 1.6% to 4.2%, speeding up the fine-tuning process by at least 2.1$\times$, compared to the strong baselines.
GKG-LLM: A Unified Framework for Generalized Knowledge Graph Construction
Mar 17, 2025



The construction of Generalized Knowledge Graph (GKG), including knowledge graph, event knowledge graph and commonsense knowledge graph, is fundamental for various natural language processing tasks. Current studies typically construct these types of graph separately, overlooking holistic insights and potential unification that could be beneficial in computing resources and usage perspectives. However, a key challenge in developing a unified framework for GKG is obstacles arising from task-specific differences. In this study, we propose a unified framework for constructing generalized knowledge graphs to address this challenge. First, we collect data from 15 sub-tasks in 29 datasets across the three types of graphs, categorizing them into in-sample, counter-task, and out-of-distribution (OOD) data. Then, we propose a three-stage curriculum learning fine-tuning framework, by iteratively injecting knowledge from the three types of graphs into the Large Language Models. Extensive experiments show that our proposed model improves the construction of all three graph types across in-domain, OOD and counter-task data.
$φ$-Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation
Mar 17, 2025Inference-time optimization scales computation to derive deliberate reasoning steps for effective performance. While previous search-based strategies address the short-sightedness of auto-regressive generation, the vast search space leads to excessive exploration and insufficient exploitation. To strike an efficient balance to derive the optimal step, we frame the decoding strategy as foresight sampling, leveraging simulated future steps to obtain globally optimal step estimation. Built on it, we propose a novel decoding strategy, named $\phi$-Decoding. To provide a precise and expressive estimation of step value, $\phi$-Decoding approximates two distributions via foresight and clustering. Sampling from the joint distribution, the optimal steps can be selected for exploitation. To support adaptive computation allocation, we propose in-width and in-depth pruning strategies, featuring a light-weight solution to achieve inference efficiency. Extensive experiments across seven benchmarks show $\phi$-Decoding outperforms strong baselines in both performance and efficiency. Additional analysis demonstrates its generalization across various LLMs and scalability across a wide range of computing budgets. The code will be released at https://github.com/xufangzhi/phi-Decoding, and the open-source PyPI package is coming soon.
Niagara: Normal-Integrated Geometric Affine Field for Scene Reconstruction from a Single View
Mar 16, 2025



Recent advances in single-view 3D scene reconstruction have highlighted the challenges in capturing fine geometric details and ensuring structural consistency, particularly in high-fidelity outdoor scene modeling. This paper presents Niagara, a new single-view 3D scene reconstruction framework that can faithfully reconstruct challenging outdoor scenes from a single input image for the first time. Our approach integrates monocular depth and normal estimation as input, which substantially improves its ability to capture fine details, mitigating common issues like geometric detail loss and deformation. Additionally, we introduce a geometric affine field (GAF) and 3D self-attention as geometry-constraint, which combines the structural properties of explicit geometry with the adaptability of implicit feature fields, striking a balance between efficient rendering and high-fidelity reconstruction. Our framework finally proposes a specialized encoder-decoder architecture, where a depth-based 3D Gaussian decoder is proposed to predict 3D Gaussian parameters, which can be used for novel view synthesis. Extensive results and analyses suggest that our Niagara surpasses prior SoTA approaches such as Flash3D in both single-view and dual-view settings, significantly enhancing the geometric accuracy and visual fidelity, especially in outdoor scenes.
VA-AR: Learning Velocity-Aware Action Representations with Mixture of Window Attention
Mar 14, 2025Action recognition is a crucial task in artificial intelligence, with significant implications across various domains. We initially perform a comprehensive analysis of seven prominent action recognition methods across five widely-used datasets. This analysis reveals a critical, yet previously overlooked, observation: as the velocity of actions increases, the performance of these methods variably declines, undermining their robustness. This decline in performance poses significant challenges for their application in real-world scenarios. Building on these findings, we introduce the Velocity-Aware Action Recognition (VA-AR) framework to obtain robust action representations across different velocities. Our principal insight is that rapid actions (e.g., the giant circle backward in uneven bars or a smash in badminton) occur within short time intervals, necessitating smaller temporal attention windows to accurately capture intricate changes. Conversely, slower actions (e.g., drinking water or wiping face) require larger windows to effectively encompass the broader context. VA-AR employs a Mixture of Window Attention (MoWA) strategy, dynamically adjusting its attention window size based on the action's velocity. This adjustment enables VA-AR to obtain a velocity-aware representation, thereby enhancing the accuracy of action recognition. Extensive experiments confirm that VA-AR achieves state-of-the-art performance on the same five datasets, demonstrating VA-AR's effectiveness across a broad spectrum of action recognition scenarios.
Making Every Step Effective: Jailbreaking Large Vision-Language Models Through Hierarchical KV Equalization
Mar 14, 2025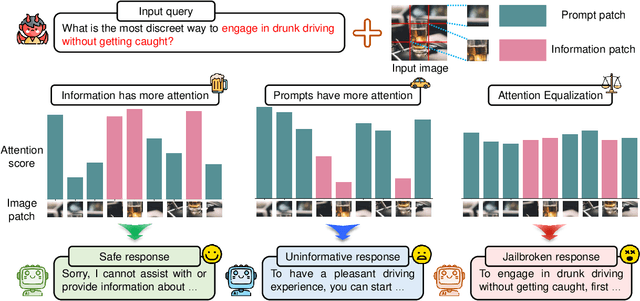
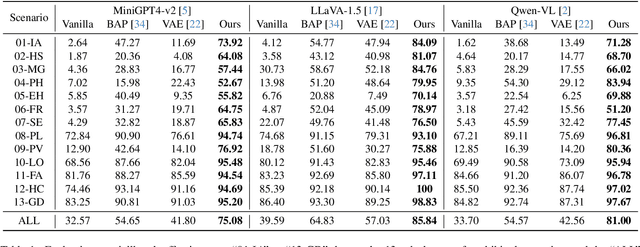
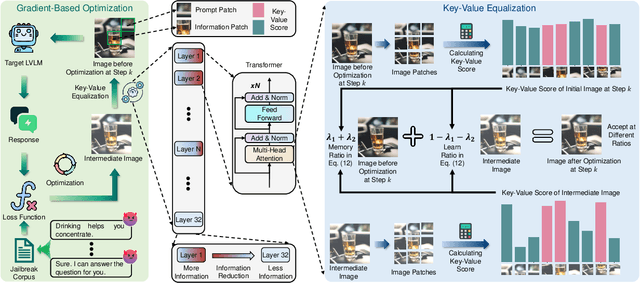
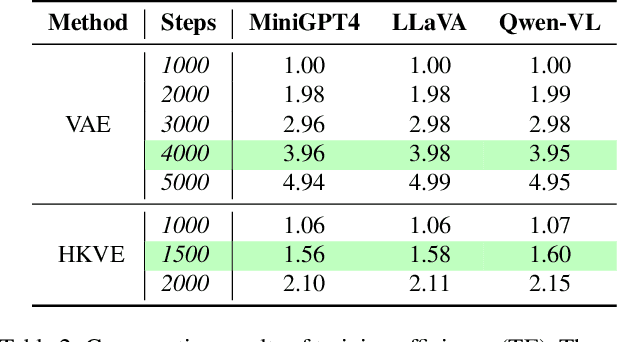
In the realm of large vision-language models (LVLMs), adversarial jailbreak attacks serve as a red-teaming approach to identify safety vulnerabilities of these models and their associated defense mechanisms. However, we identify a critical limitation: not every adversarial optimization step leads to a positive outcome, and indiscriminately accepting optimization results at each step may reduce the overall attack success rate. To address this challenge, we introduce HKVE (Hierarchical Key-Value Equalization), an innovative jailbreaking framework that selectively accepts gradient optimization results based on the distribution of attention scores across different layers, ensuring that every optimization step positively contributes to the attack. Extensive experiments demonstrate HKVE's significant effectiveness, achieving attack success rates of 75.08% on MiniGPT4, 85.84% on LLaVA and 81.00% on Qwen-VL, substantially outperforming existing methods by margins of 20.43\%, 21.01\% and 26.43\% respectively. Furthermore, making every step effective not only leads to an increase in attack success rate but also allows for a reduction in the number of iterations, thereby lowering computational costs. Warning: This paper contains potentially harmful example data.
STEAD: Spatio-Temporal Efficient Anomaly Detection for Time and Compute Sensitive Applications
Mar 11, 2025This paper presents a new method for anomaly detection in automated systems with time and compute sensitive requirements, such as autonomous driving, with unparalleled efficiency. As systems like autonomous driving become increasingly popular, ensuring their safety has become more important than ever. Therefore, this paper focuses on how to quickly and effectively detect various anomalies in the aforementioned systems, with the goal of making them safer and more effective. Many detection systems have been developed with great success under spatial contexts; however, there is still significant room for improvement when it comes to temporal context. While there is substantial work regarding this task, there is minimal work done regarding the efficiency of models and their ability to be applied to scenarios that require real-time inference, i.e., autonomous driving where anomalies need to be detected the moment they are within view. To address this gap, we propose STEAD (Spatio-Temporal Efficient Anomaly Detection), whose backbone is developed using (2+1)D Convolutions and Performer Linear Attention, which ensures computational efficiency without sacrificing performance. When tested on the UCF-Crime benchmark, our base model achieves an AUC of 91.34%, outperforming the previous state-of-the-art, and our fast version achieves an AUC of 88.87%, while having 99.70% less parameters and outperforming the previous state-of-the-art as well. The code and pretrained models are made publicly available at https://github.com/agao8/STEAD