 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoTalk: Speech-driven emotional disentanglement for 3D face animation
Mar 20, 2023



Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion. However, existing methods often neglect emotional facial expressions or fail to disentangle them from speech content. To address this issue, this paper proposes an end-to-end neural network to disentangle different emotions in speech so as to generate rich 3D facial expressions. Specifically, we introduce the emotion disentangling encoder (EDE) to disentangle the emotion and content in the speech by cross-reconstructed speech signals with different emotion labels. Then an emotion-guided feature fusion decoder is employed to generate a 3D talking face with enhanced emotion. The decoder is driven by the disentangled identity, emotional, and content embeddings so as to generate controllable personal and emotional styles. Finally, considering the scarcity of the 3D emotional talking face data, we resort to the supervision of facial blendshapes, which enables the reconstruction of plausible 3D faces from 2D emotional data, and contribute a large-scale 3D emotional talking face dataset (3D-ETF) to train the network. Our experiments and user studies demonstrate that our approach outperforms state-of-the-art methods and exhibits more diverse facial movements. We recommend watching the supplementary video: https://ziqiaopeng.github.io/emotalk
SHLE: Devices Tracking and Depth Filtering for Stereo-based Height Limit Estimation
Dec 22, 2022



Recently, over-height vehicle strike frequently occurs, causing great economic cost and serious safety problems. Hence, an alert system which can accurately discover any possible height limiting devices in advance is necessary to be employed in modern large or medium sized cars, such as touring cars. Detecting and estimating the height limiting devices act as the key point of a successful height limit alert system. Though there are some works research height limit estimation, existing methods are either too computational expensive or not accurate enough. In this paper, we propose a novel stereo-based pipeline named SHLE for height limit estimation. Our SHLE pipeline consists of two stages. In stage 1, a novel devices detection and tracking scheme is introduced, which accurately locate the height limit devices in the left or right image. Then, in stage 2, the depth is temporally measured, extracted and filtered to calculate the height limit device. To benchmark the height limit estimation task, we build a large-scale dataset named "Disparity Height", where stereo images, pre-computed disparities and ground-truth height limit annotations are provided. We conducted extensive experiments on "Disparity Height" and the results show that SHLE achieves an average error below than 10cm though the car is 70m away from the devices. Our method also outperforms all compared baselines and achieves state-of-the-art performance. Code is available at https://github.com/Yang-Kaixing/SHLE.
FuRPE: Learning Full-body Reconstruction from Part Experts
Nov 30, 2022Full-body reconstruction is a fundamental but challenging task. Owing to the lack of annotated data, the performances of existing methods are largely limited. In this paper, we propose a novel method named Full-body Reconstruction from Part Experts~(FuRPE) to tackle this issue. In FuRPE, the network is trained using pseudo labels and features generated from part-experts. An simple yet effective pseudo ground-truth selection scheme is proposed to extract high-quality pseudo labels. In this way, a large-scale of existing human body reconstruction datasets can be leveraged and contribute to the model training. In addition, an exponential moving average training strategy is introduced to train the network in a self-supervised manner, further boosting the performance of the model. Extensive experiments on several widely used datasets demonstrate the effectiveness of our method over the baseline. Our method achieves the state-of-the-art performance. Code will be publicly available for further research.
GIDP: Learning a Good Initialization and Inducing Descriptor Post-enhancing for Large-scale Place Recognition
Sep 23, 2022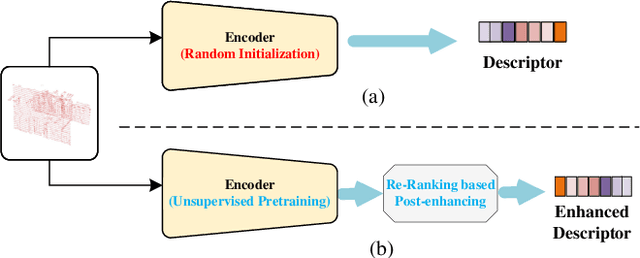
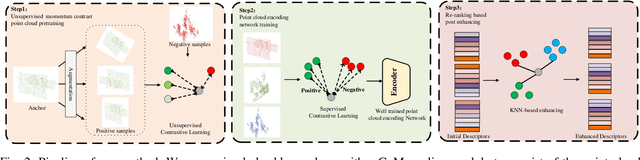
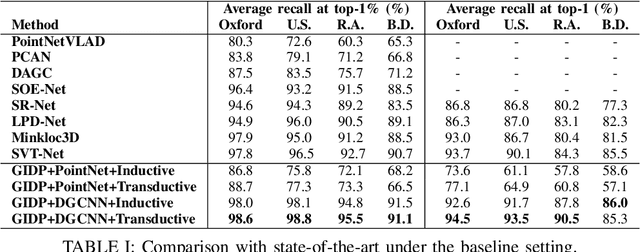
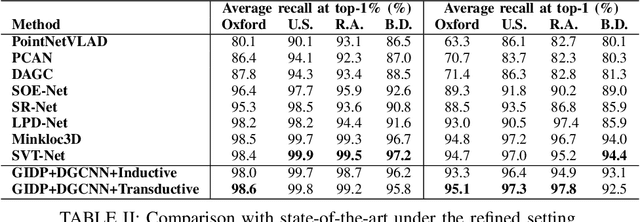
Large-scale place recognition is a fundamental but challenging task, which plays an increasingly important role in autonomous driving and robotics. Existing methods have achieved acceptable good performance, however, most of them are concentrating on designing elaborate global descriptor learning network structures. The importance of feature generalization and descriptor post-enhancing has long been neglected. In this work, we propose a novel method named GIDP to learn a Good Initialization and Inducing Descriptor Poseenhancing for Large-scale Place Recognition. In particular, an unsupervised momentum contrast point cloud pretraining module and a reranking-based descriptor post-enhancing module are proposed respectively in GIDP. The former aims at learning a good initialization for the point cloud encoding network before training the place recognition model, while the later aims at post-enhancing the predicted global descriptor through reranking at inference time. Extensive experiments on both indoor and outdoor datasets demonstrate that our method can achieve state-of-the-art performance using simple and general point cloud encoding backbones.
Human Pose Driven Object Effects Recommendation
Sep 17, 2022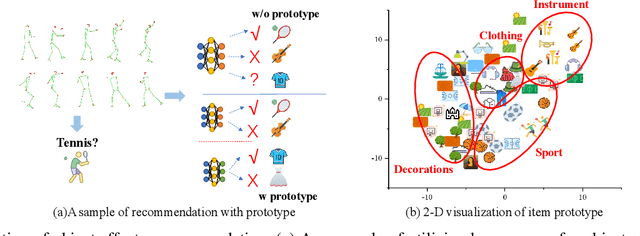
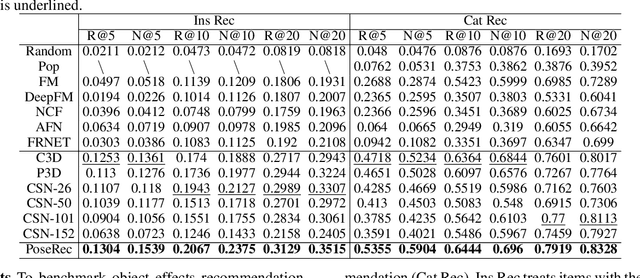
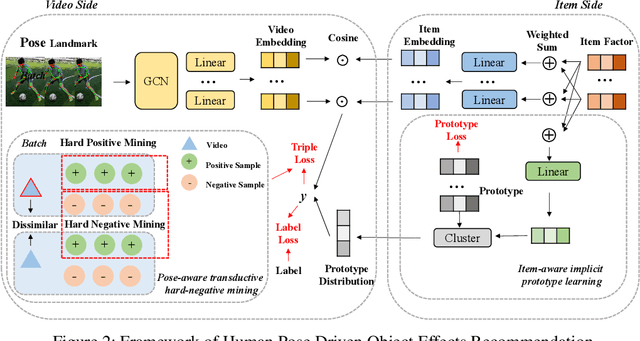
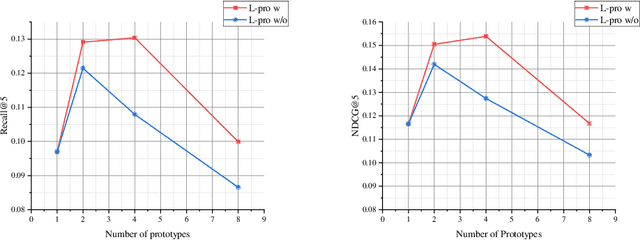
In this paper, we research the new topic of object effects recommendation in micro-video platforms, which is a challenging but important task for many practical applications such as advertisement insertion. To avoid the problem of introducing background bias caused by directly learning video content from image frames, we propose to utilize the meaningful body language hidden in 3D human pose for recommendation. To this end, in this work, a novel human pose driven object effects recommendation network termed PoseRec is introduced. PoseRec leverages the advantages of 3D human pose detection and learns information from multi-frame 3D human pose for video-item registration, resulting in high quality object effects recommendation performance. Moreover, to solve the inherent ambiguity and sparsity issues that exist in object effects recommendation, we further propose a novel item-aware implicit prototype learning module and a novel pose-aware transductive hard-negative mining module to better learn pose-item relationships. What's more, to benchmark methods for the new research topic, we build a new dataset for object effects recommendation named Pose-OBE. Extensive experiments on Pose-OBE demonstrate that our method can achieve superior performance than strong baselines.
Domain Gap Estimation for Source Free Unsupervised Domain Adaptation with Many Classifiers
Jul 12, 2022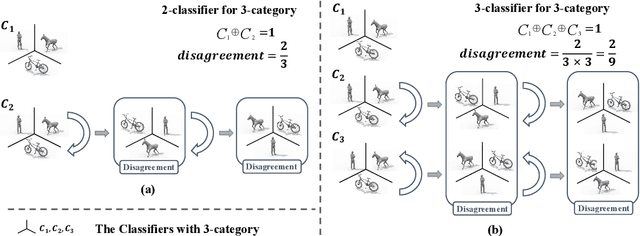
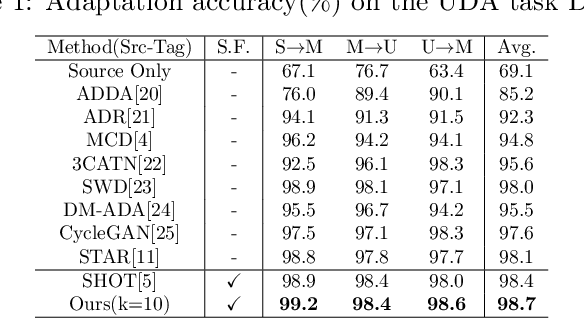
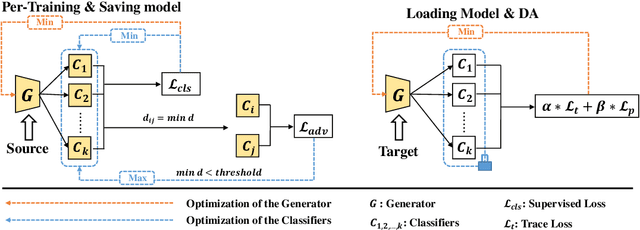
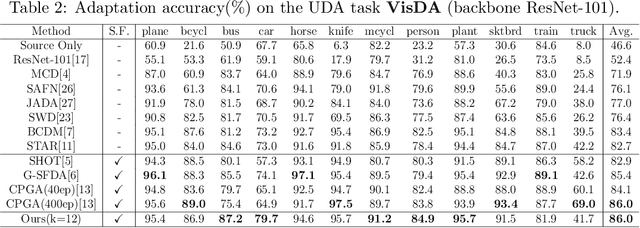
In theory, the success of unsupervised domain adaptation (UDA) largely relies on domain gap estimation. However, for source free UDA, the source domain data can not be accessed during adaptation, which poses great challenge of measuring the domain gap. In this paper, we propose to use many classifiers to learn the source domain decision boundaries, which provides a tighter upper bound of the domain gap, even if both of the domain data can not be simultaneously accessed. The source model is trained to push away each pair of classifiers whilst ensuring the correctness of the decision boundaries. In this sense, our many classifiers model separates the source different categories as far as possible which induces the maximum disagreement of many classifiers in the target domain, thus the transferable source domain knowledge is maximized. For adaptation, the source model is adapted to maximize the agreement among pairs of the classifiers. Thus the target features are pushed away from the decision boundaries. Experiments on several datasets of UDA show that our approach achieves state of the art performance among source free UDA approaches and can even compete to source available UDA methods.
Deep Neural Network for Blind Visual Quality Assessment of 4K Content
Jun 09, 2022
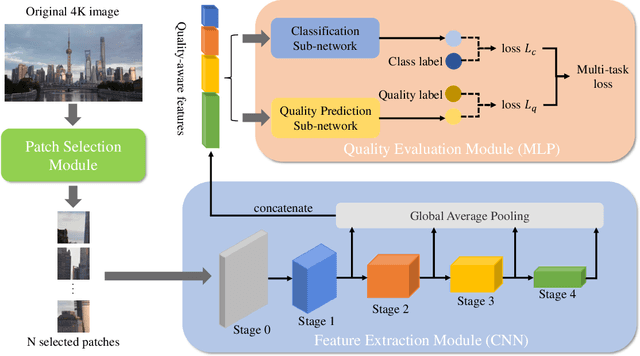
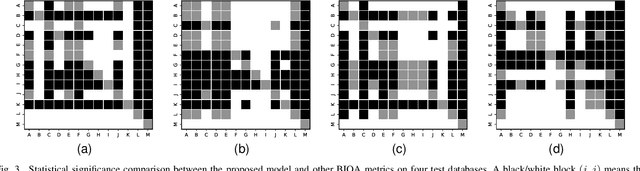

The 4K content can deliver a more immersive visual experience to consumers due to the huge improvement of spatial resolution. However, existing blind image quality assessment (BIQA) methods are not suitable for the original and upscaled 4K contents due to the expanded resolution and specific distortions. In this paper, we propose a deep learning-based BIQA model for 4K content, which on one hand can recognize true and pseudo 4K content and on the other hand can evaluate their perceptual visual quality. Considering the characteristic that high spatial resolution can represent more abundant high-frequency information, we first propose a Grey-level Co-occurrence Matrix (GLCM) based texture complexity measure to select three representative image patches from a 4K image, which can reduce the computational complexity and is proven to be very effective for the overall quality prediction through experiments. Then we extract different kinds of visual features from the intermediate layers of the convolutional neural network (CNN) and integrate them into the quality-aware feature representation. Finally, two multilayer perception (MLP) networks are utilized to map the quality-aware features into the class probability and the quality score for each patch respectively. The overall quality index is obtained through the average pooling of patch results. The proposed model is trained through the multi-task learning manner and we introduce an uncertainty principle to balance the losses of the classification and regression tasks. The experimental results show that the proposed model outperforms all compared BIQA metrics on four 4K content quality assessment databases.
Reconstruction-Aware Prior Distillation for Semi-supervised Point Cloud Completion
Apr 21, 2022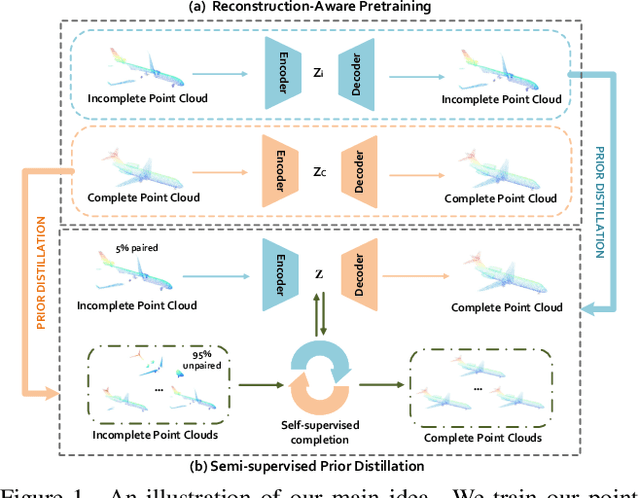
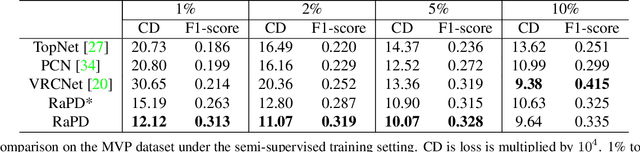
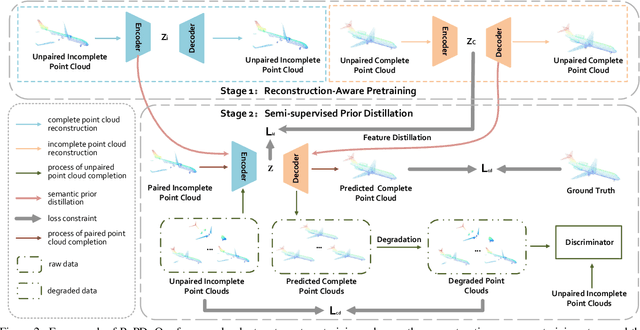
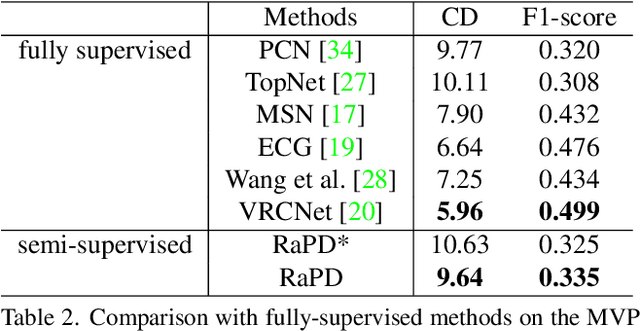
Point clouds scanned by real-world sensors are always incomplete, irregular, and noisy, making the point cloud completion task become increasingly more important. Though many point cloud completion methods have been proposed, most of them require a large number of paired complete-incomplete point clouds for training, which is labor exhausted. In contrast, this paper proposes a novel Reconstruction-Aware Prior Distillation semi-supervised point cloud completion method named RaPD, which takes advantage of a two-stage training scheme to reduce the dependence on a large-scale paired dataset. In training stage 1, the so-called deep semantic prior is learned from both unpaired complete and unpaired incomplete point clouds using a reconstruction-aware pretraining process. While in training stage 2, we introduce a semi-supervised prior distillation process, where an encoder-decoder-based completion network is trained by distilling the prior into the network utilizing only a small number of paired training samples. A self-supervised completion module is further introduced, excavating the value of a large number of unpaired incomplete point clouds, leading to an increase in the network's performance. Extensive experiments on several widely used datasets demonstrate that RaPD, the first semi-supervised point cloud completion method, achieves superior performance to previous methods on both homologous and heterologous scenarios.
Object Level Depth Reconstruction for Category Level 6D Object Pose Estimation From Monocular RGB Image
Apr 04, 2022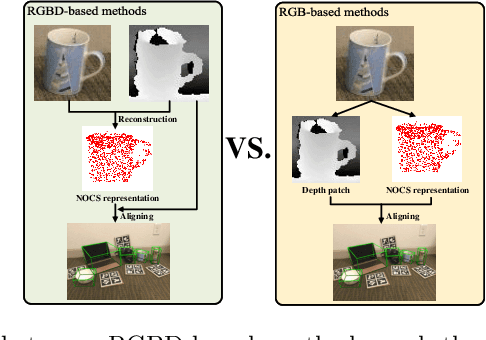
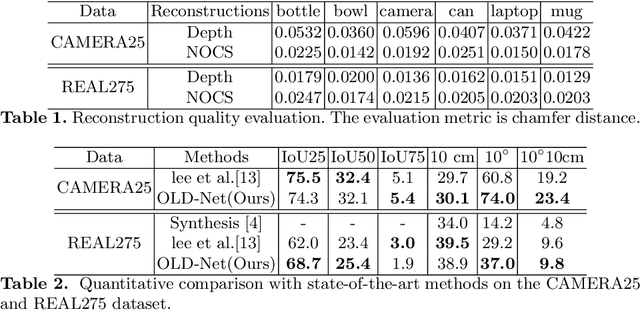
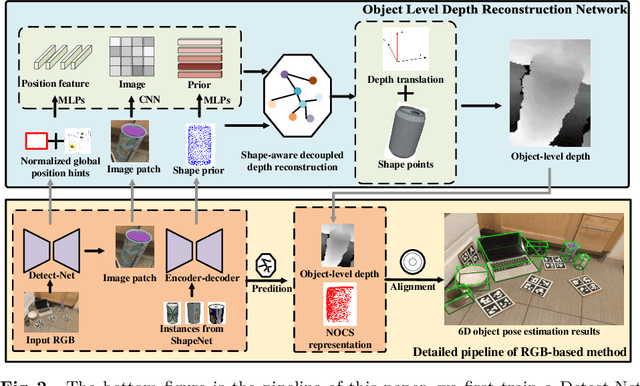

Recently, RGBD-based category-level 6D object pose estimation has achieved promising improvement in performance, however, the requirement of depth information prohibits broader applications. In order to relieve this problem, this paper proposes a novel approach named Object Level Depth reconstruction Network (OLD-Net) taking only RGB images as input for category-level 6D object pose estimation. We propose to directly predict object-level depth from a monocular RGB image by deforming the category-level shape prior into object-level depth and the canonical NOCS representation. Two novel modules named Normalized Global Position Hints (NGPH) and Shape-aware Decoupled Depth Reconstruction (SDDR) module are introduced to learn high fidelity object-level depth and delicate shape representations. At last, the 6D object pose is solved by aligning the predicted canonical representation with the back-projected object-level depth. Extensive experiments on the challenging CAMERA25 and REAL275 datasets indicate that our model, though simple, achieves state-of-the-art performance.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021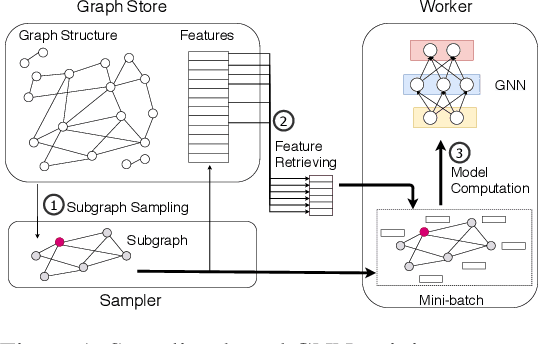
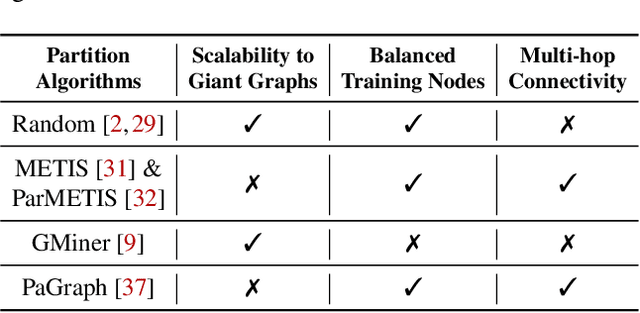
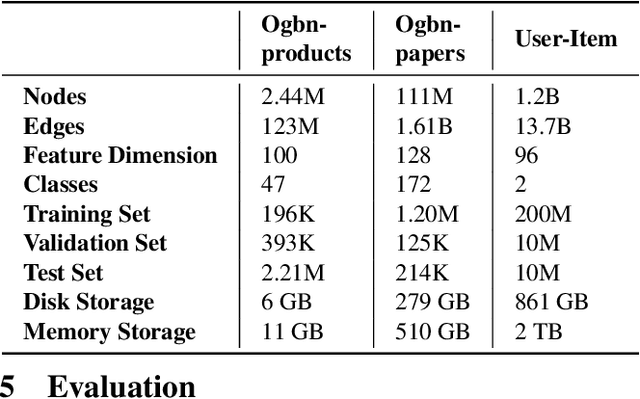
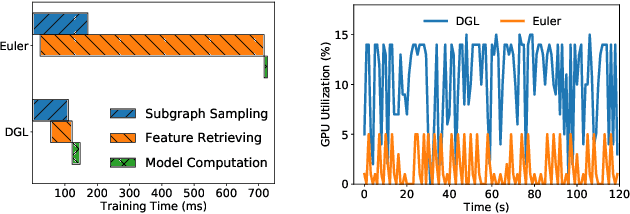
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.