 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization
Feb 19, 2020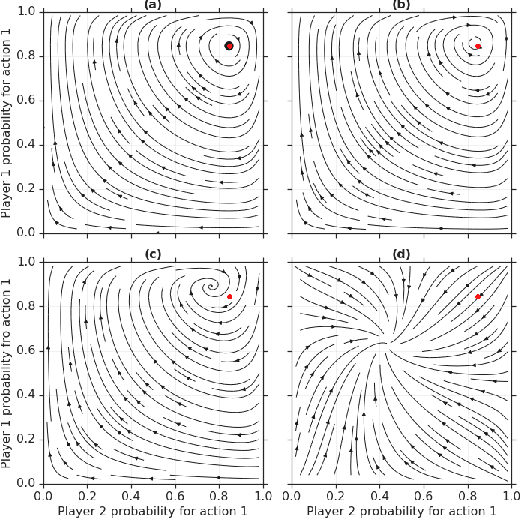
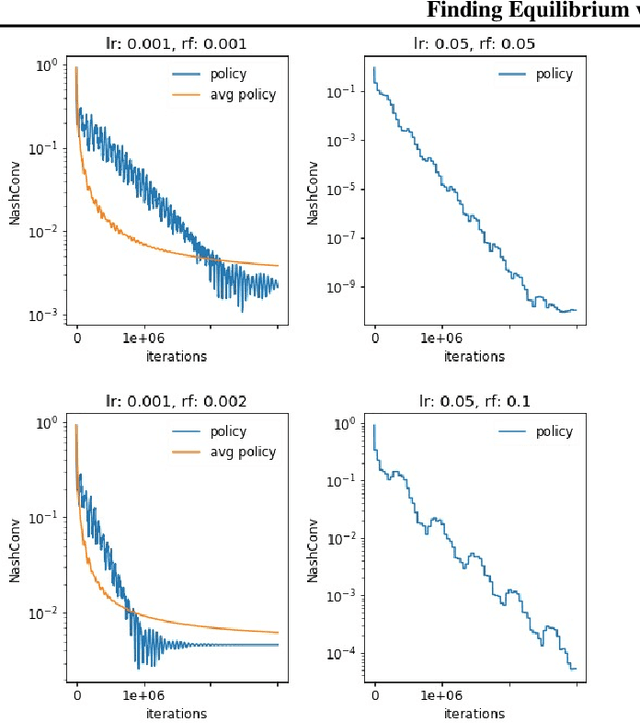
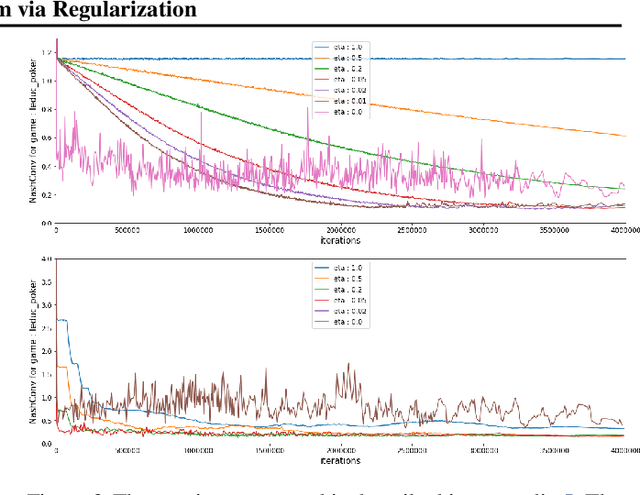

In this paper we investigate the Follow the Regularized Leader dynamics in sequential imperfect information games (IIG). We generalize existing results of Poincar\'e recurrence from normal-form games to zero-sum two-player imperfect information games and other sequential game settings. We then investigate how adapting the reward (by adding a regularization term) of the game can give strong convergence guarantees in monotone games. We continue by showing how this reward adaptation technique can be leveraged to build algorithms that converge exactly to the Nash equilibrium. Finally, we show how these insights can be directly used to build state-of-the-art model-free algorithms for zero-sum two-player Imperfect Information Games (IIG).
Multiagent Evaluation under Incomplete Information
Oct 30, 2019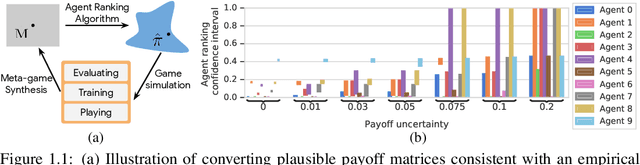
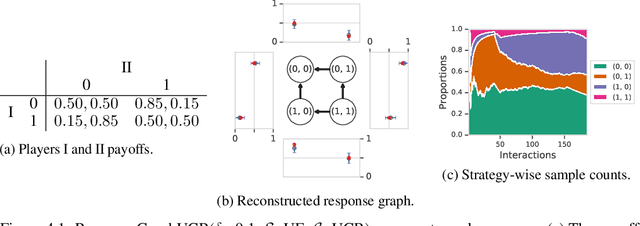
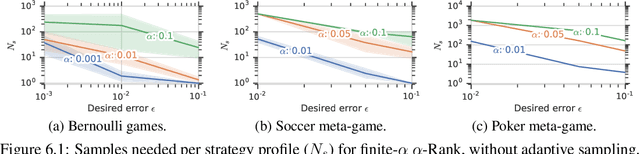
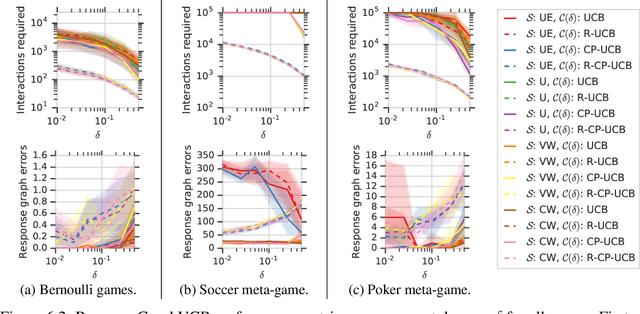
This paper investigates the evaluation of learned multiagent strategies in the incomplete information setting, which plays a critical role in ranking and training of agents. Traditionally, researchers have relied on Elo ratings for this purpose, with recent works also using methods based on Nash equilibria. Unfortunately, Elo is unable to handle intransitive agent interactions, and other techniques are restricted to zero-sum, two-player settings or are limited by the fact that the Nash equilibrium is intractable to compute. Recently, a ranking method called {\alpha}-Rank, relying on a new graph-based game-theoretic solution concept, was shown to tractably apply to general games. However, evaluations based on Elo or {\alpha}-Rank typically assume noise-free game outcomes, despite the data often being collected from noisy simulations, making this assumption unrealistic in practice. This paper investigates multiagent evaluation in the incomplete information regime, involving general-sum many-player games with noisy outcomes. We derive sample complexity guarantees required to confidently rank agents in this setting. We propose adaptive algorithms for accurate ranking, provide correctness and sample complexity guarantees, then introduce a means of connecting uncertainties in noisy match outcomes to uncertainties in rankings. We evaluate the performance of these approaches in several domains, including Bernoulli games, a soccer meta-game, and Kuhn poker.
A Generalized Training Approach for Multiagent Learning
Sep 27, 2019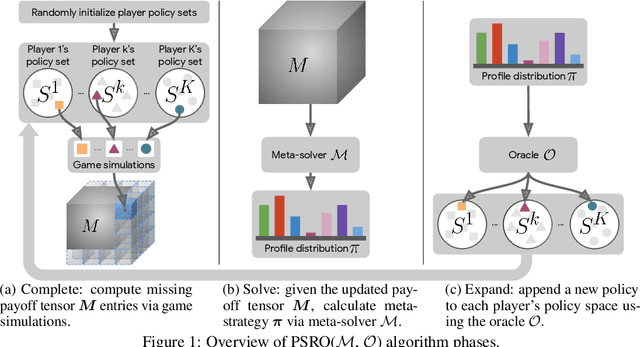
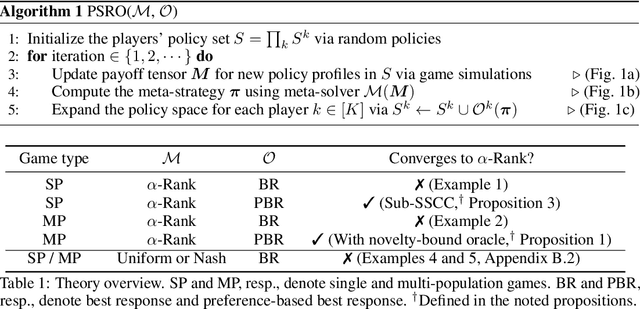
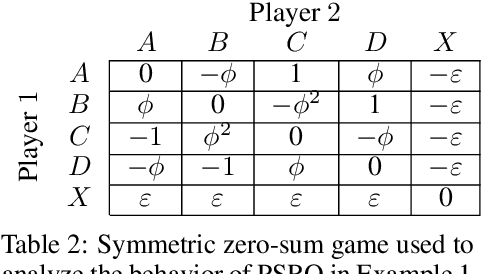
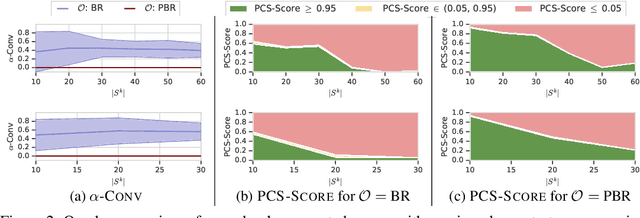
This paper investigates a population-based training regime based on game-theoretic principles called Policy-Spaced Response Oracles (PSRO). PSRO is general in the sense that it (1) encompasses well-known algorithms such as fictitious play and double oracle as special cases, and (2) in principle applies to general-sum, many-player games. Despite this, prior studies of PSRO have been focused on two-player zero-sum games, a regime wherein Nash equilibria are tractably computable. In moving from two-player zero-sum games to more general settings, computation of Nash equilibria quickly becomes infeasible. Here, we extend the theoretical underpinnings of PSRO by considering an alternative solution concept, {\alpha}-Rank, which is unique (thus faces no equilibrium selection issues, unlike Nash) and tractable to compute in general-sum, many-player settings. We establish convergence guarantees in several games classes, and identify links between Nash equilibria and {\alpha}-Rank. We demonstrate the competitive performance of {\alpha}-Rank-based PSRO against an exact Nash solver-based PSRO in 2-player Kuhn and Leduc Poker. We then go beyond the reach of prior PSRO applications by considering 3- to 5-player poker games, yielding instances where {\alpha}-Rank achieves faster convergence than approximate Nash solvers, thus establishing it as a favorable general games solver. We also carry out an initial empirical validation in MuJoCo soccer, illustrating the feasibility of the proposed approach in another complex domain.
Foolproof Cooperative Learning
Jun 24, 2019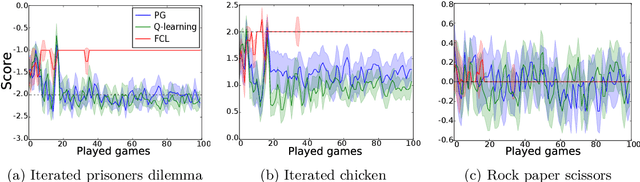
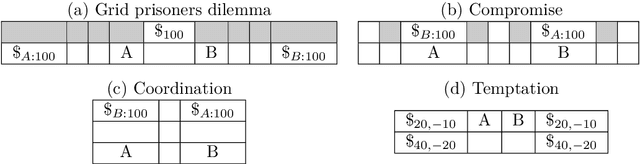
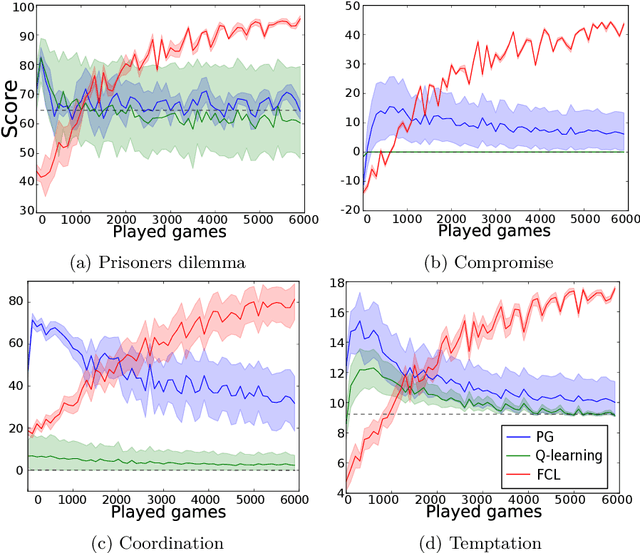
This paper extends the notion of equilibrium in game theory to learning algorithms in repeated stochastic games. We define a learning equilibrium as an algorithm used by a population of players, such that no player can individually use an alternative algorithm and increase its asymptotic score. We introduce Foolproof Cooperative Learning (FCL), an algorithm that converges to a Tit-for-Tat behavior. It allows cooperative strategies when played against itself while being not exploitable by selfish players. We prove that in repeated symmetric games, this algorithm is a learning equilibrium. We illustrate the behavior of FCL on symmetric matrix and grid games, and its robustness to selfish learners.
Neural Replicator Dynamics
Jun 01, 2019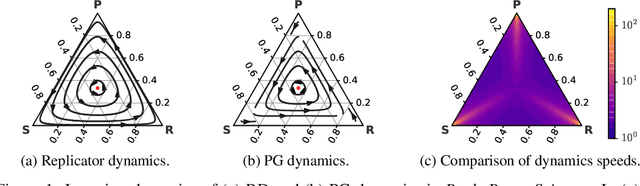

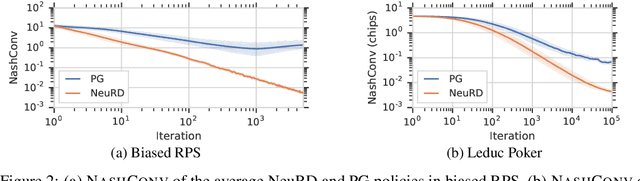
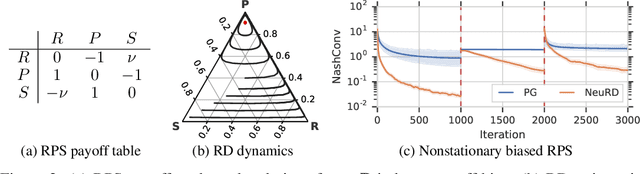
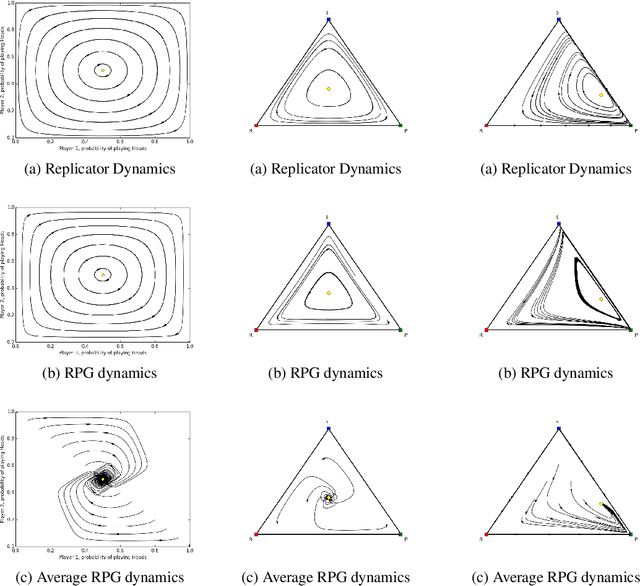
In multiagent learning, agents interact in inherently nonstationary environments due to their concurrent policy updates. It is, therefore, paramount to develop and analyze algorithms that learn effectively despite these nonstationarities. A number of works have successfully conducted this analysis under the lens of evolutionary game theory (EGT), wherein a population of individuals interact and evolve based on biologically-inspired operators. These studies have mainly focused on establishing connections to value-iteration based approaches in stateless or tabular games. We extend this line of inquiry to formally establish links between EGT and policy gradient (PG) methods, which have been extensively applied in single and multiagent learning. We pinpoint weaknesses of the commonly-used softmax PG algorithm in adversarial and nonstationary settings and contrast PG's behavior to that predicted by replicator dynamics (RD), a central model in EGT. We consequently provide theoretical results that establish links between EGT and PG methods, then derive Neural Replicator Dynamics (NeuRD), a parameterized version of RD that constitutes a novel method with several advantages. First, as NeuRD reduces to the well-studied no-regret Hedge algorithm in the tabular setting, it inherits no-regret guarantees that enable convergence to equilibria in games. Second, NeuRD is shown to be more adaptive to nonstationarity, in comparison to PG, when learning in canonical games and imperfect information benchmarks including Poker. Thirdly, modifying any PG-based algorithm to use the NeuRD update rule is straightforward and incurs no added computational costs. Finally, while single-agent learning is not the main focus of the paper, we verify empirically that NeuRD is competitive in these settings with a recent baseline algorithm.
Open-ended Learning in Symmetric Zero-sum Games
Jan 23, 2019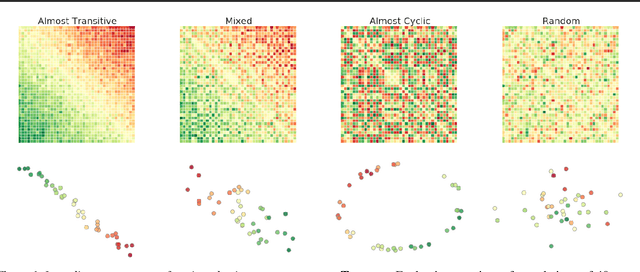
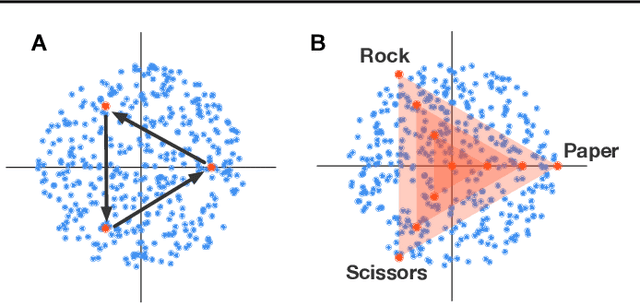
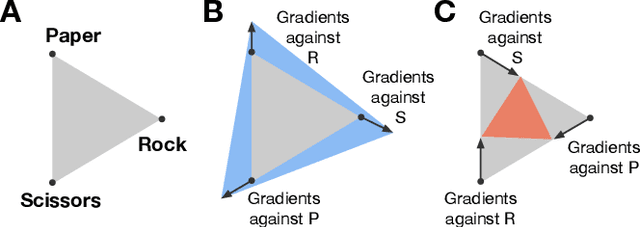
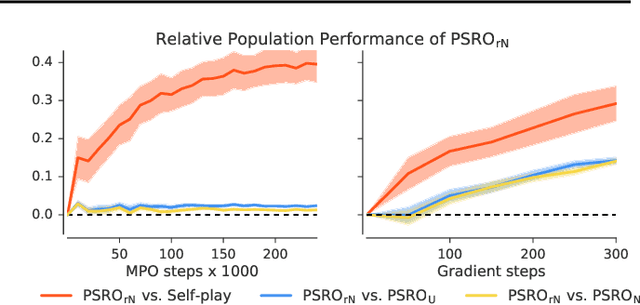
Zero-sum games such as chess and poker are, abstractly, functions that evaluate pairs of agents, for example labeling them `winner' and `loser'. If the game is approximately transitive, then self-play generates sequences of agents of increasing strength. However, nontransitive games, such as rock-paper-scissors, can exhibit strategic cycles, and there is no longer a clear objective -- we want agents to increase in strength, but against whom is unclear. In this paper, we introduce a geometric framework for formulating agent objectives in zero-sum games, in order to construct adaptive sequences of objectives that yield open-ended learning. The framework allows us to reason about population performance in nontransitive games, and enables the development of a new algorithm (rectified Nash response, PSRO_rN) that uses game-theoretic niching to construct diverse populations of effective agents, producing a stronger set of agents than existing algorithms. We apply PSRO_rN to two highly nontransitive resource allocation games and find that PSRO_rN consistently outperforms the existing alternatives.
Malthusian Reinforcement Learning
Dec 17, 2018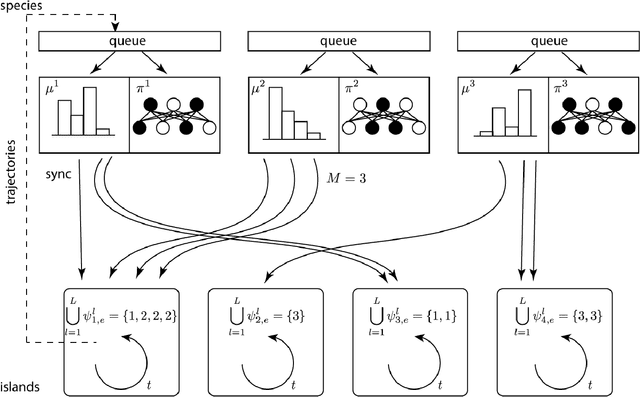
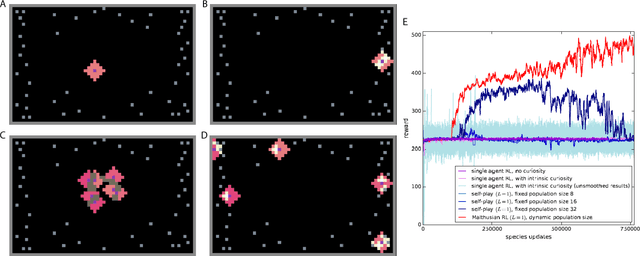
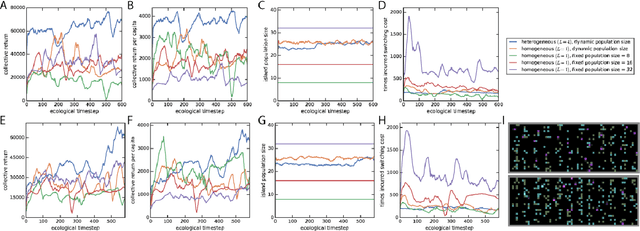
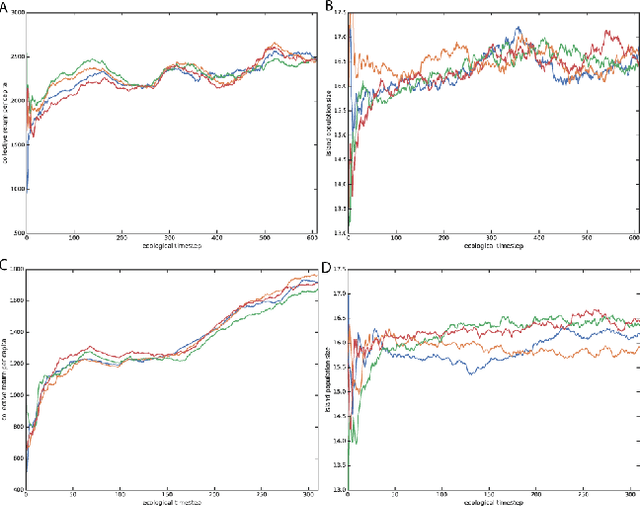
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.
Re-evaluating Evaluation
Oct 30, 2018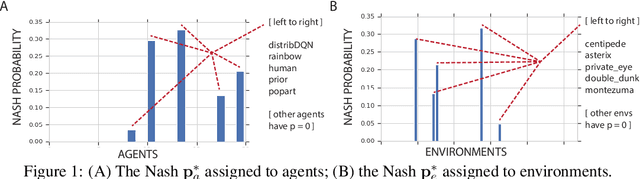
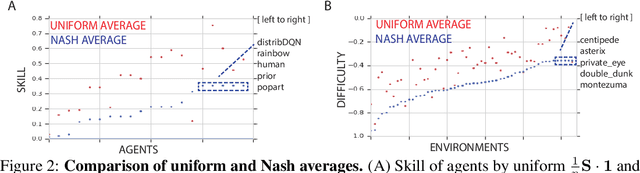
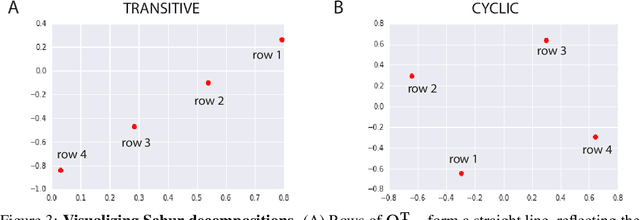
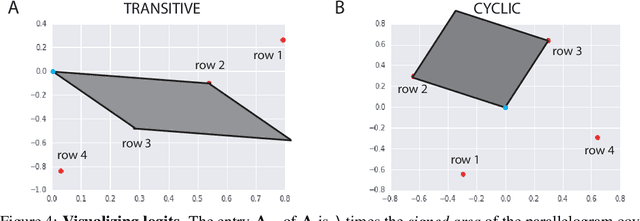
Progress in machine learning is measured by careful evaluation on problems of outstanding common interest. However, the proliferation of benchmark suites and environments, adversarial attacks, and other complications has diluted the basic evaluation model by overwhelming researchers with choices. Deliberate or accidental cherry picking is increasingly likely, and designing well-balanced evaluation suites requires increasing effort. In this paper we take a step back and propose Nash averaging. The approach builds on a detailed analysis of the algebraic structure of evaluation in two basic scenarios: agent-vs-agent and agent-vs-task. The key strength of Nash averaging is that it automatically adapts to redundancies in evaluation data, so that results are not biased by the incorporation of easy tasks or weak agents. Nash averaging thus encourages maximally inclusive evaluation -- since there is no harm (computational cost aside) from including all available tasks and agents.
Actor-Critic Policy Optimization in Partially Observable Multiagent Environments
Oct 21, 2018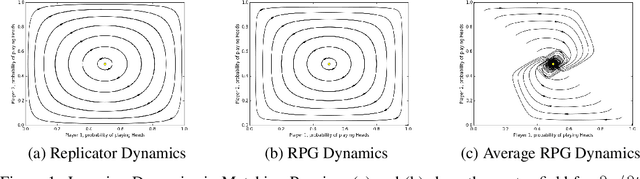
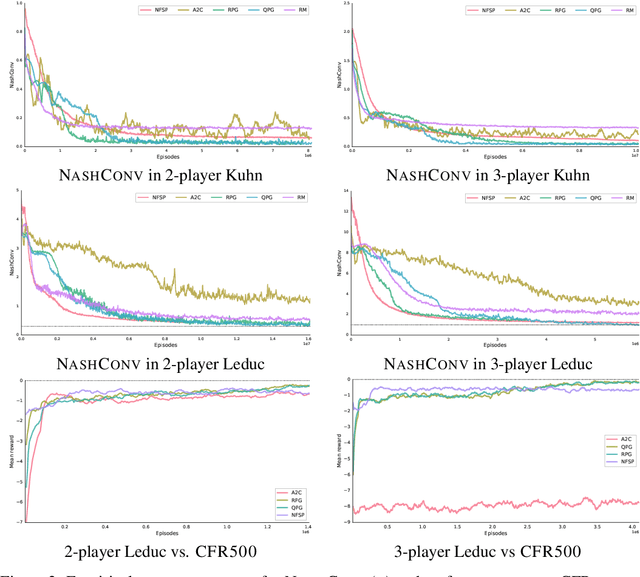
Optimization of parameterized policies for reinforcement learning (RL) is an important and challenging problem in artificial intelligence. Among the most common approaches are algorithms based on gradient ascent of a score function representing discounted return. In this paper, we examine the role of these policy gradient and actor-critic algorithms in partially-observable multiagent environments. We show several candidate policy update rules and relate them to a foundation of regret minimization and multiagent learning techniques for the one-shot and tabular cases, leading to previously unknown convergence guarantees. We apply our method to model-free multiagent reinforcement learning in adversarial sequential decision problems (zero-sum imperfect information games), using RL-style function approximation. We evaluate on commonly used benchmark Poker domains, showing performance against fixed policies and empirical convergence to approximate Nash equilibria in self-play with rates similar to or better than a baseline model-free algorithm for zero sum games, without any domain-specific state space reductions.
Playing the Game of Universal Adversarial Perturbations
Sep 25, 2018

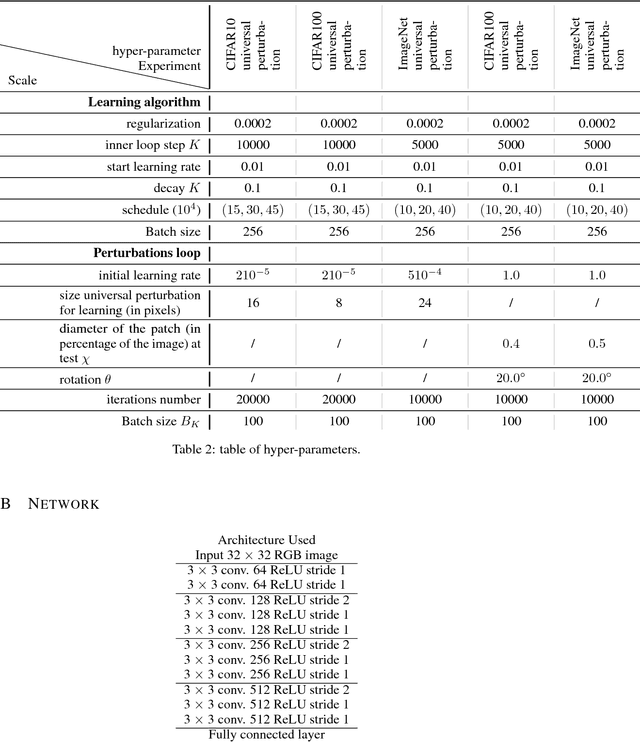
We study the problem of learning classifiers robust to universal adversarial perturbations. While prior work approaches this problem via robust optimization, adversarial training, or input transformation, we instead phrase it as a two-player zero-sum game. In this new formulation, both players simultaneously play the same game, where one player chooses a classifier that minimizes a classification loss whilst the other player creates an adversarial perturbation that increases the same loss when applied to every sample in the training set. By observing that performing a classification (respectively creating adversarial samples) is the best response to the other player, we propose a novel extension of a game-theoretic algorithm, namely fictitious play, to the domain of training robust classifiers. Finally, we empirically show the robustness and versatility of our approach in two defence scenarios where universal attacks are performed on several image classification datasets -- CIFAR10, CIFAR100 and ImageNet.