 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics Models for Model Predictive Agents
Sep 29, 2021
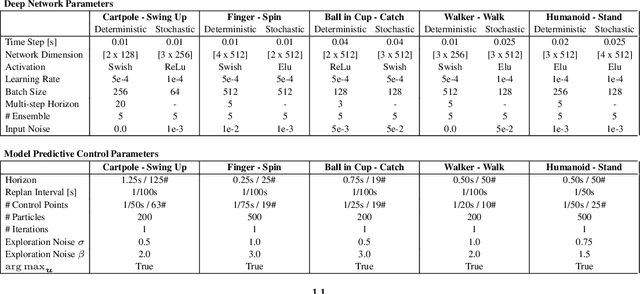
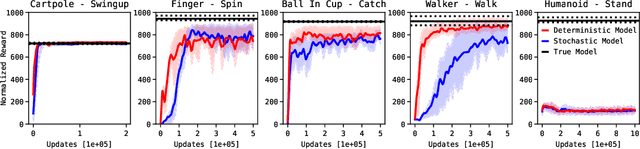
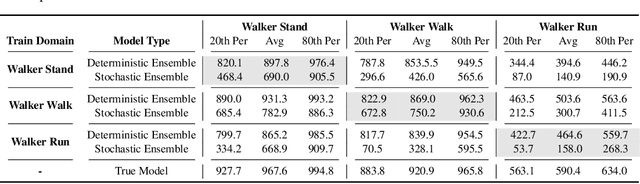
Model-Based Reinforcement Learning involves learning a \textit{dynamics model} from data, and then using this model to optimise behaviour, most often with an online \textit{planner}. Much of the recent research along these lines presents a particular set of design choices, involving problem definition, model learning and planning. Given the multiple contributions, it is difficult to evaluate the effects of each. This paper sets out to disambiguate the role of different design choices for learning dynamics models, by comparing their performance to planning with a ground-truth model -- the simulator. First, we collect a rich dataset from the training sequence of a model-free agent on 5 domains of the DeepMind Control Suite. Second, we train feed-forward dynamics models in a supervised fashion, and evaluate planner performance while varying and analysing different model design choices, including ensembling, stochasticity, multi-step training and timestep size. Besides the quantitative analysis, we describe a set of qualitative findings, rules of thumb, and future research directions for planning with learned dynamics models. Videos of the results are available at https://sites.google.com/view/learning-better-models.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021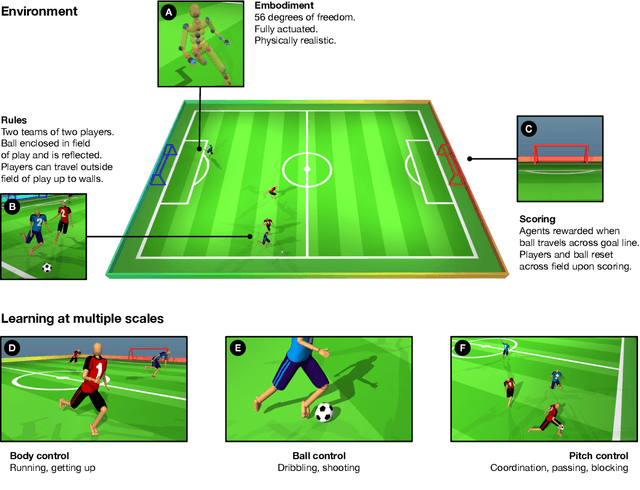

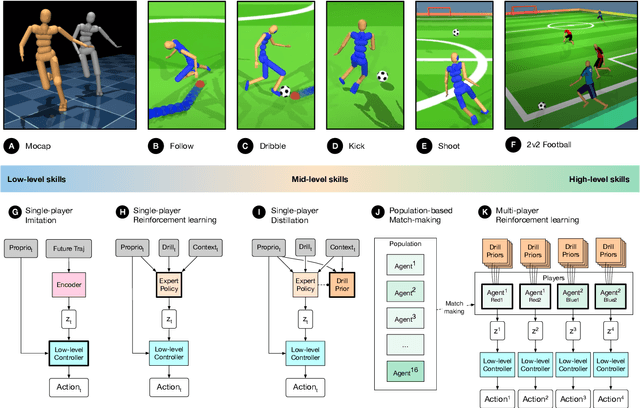

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Local Search for Policy Iteration in Continuous Control
Oct 12, 2020
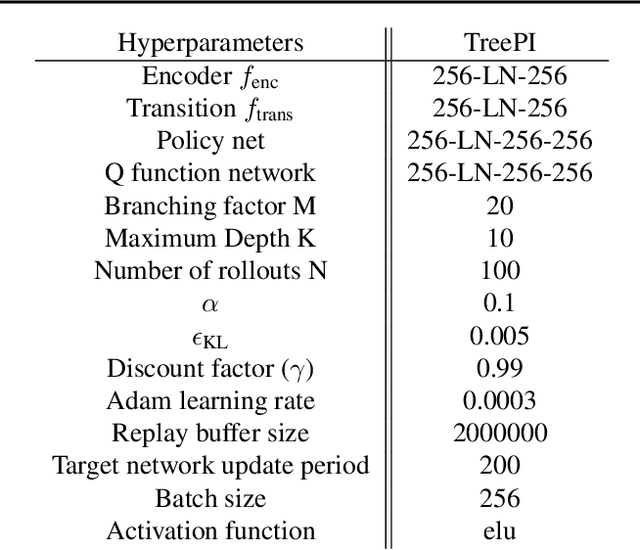
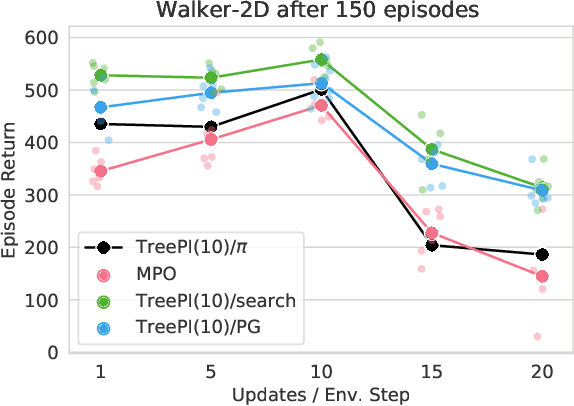

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
Learning to swim in potential flow
Sep 30, 2020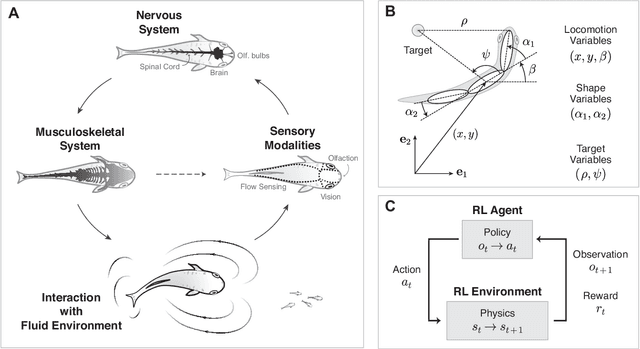
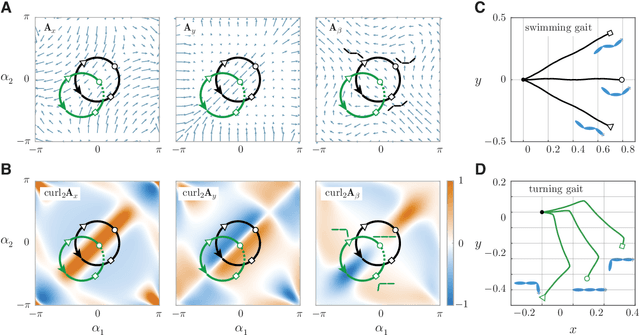
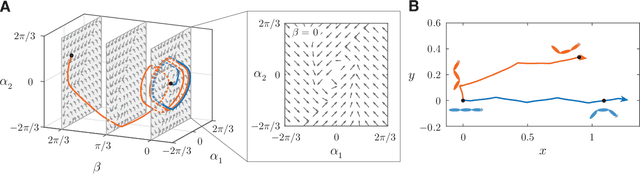
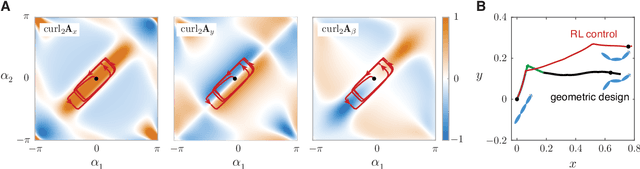
Fish swim by undulating their bodies. These propulsive motions require coordinated shape changes of a body that interacts with its fluid environment, but the specific shape coordination that leads to robust turning and swimming motions remains unclear. We propose a simple model of a three-link fish swimming in a potential flow environment and we use model-free reinforcement learning to arrive at optimal shape changes for two swimming tasks: swimming in a desired direction and swimming towards a known target. This fish model belongs to a class of problems in geometric mechanics, known as driftless dynamical systems, which allow us to analyze the swimming behavior in terms of geometric phases over the shape space of the fish. These geometric methods are less intuitive in the presence of drift. Here, we use the shape space analysis as a tool for assessing, visualizing, and interpreting the control policies obtained via reinforcement learning in the absence of drift. We then examine the robustness of these policies to drift-related perturbations. Although the fish has no direct control over the drift itself, it learns to take advantage of the presence of moderate drift to reach its target.
RL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
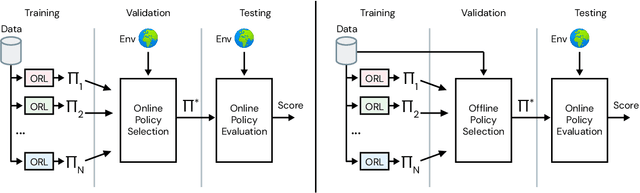
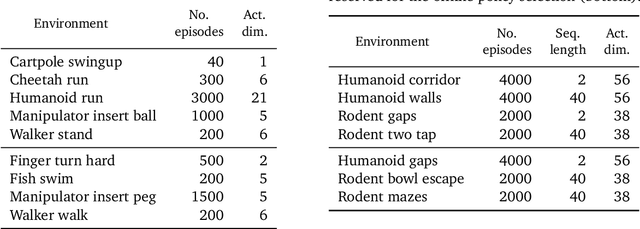
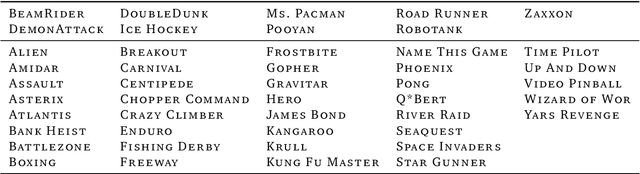
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Critic Regularized Regression
Jun 26, 2020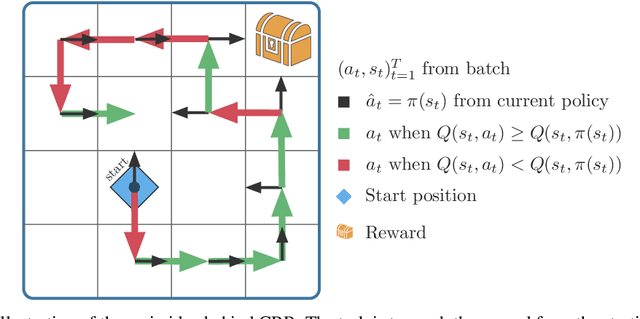


Offline reinforcement learning (RL), also known as batch RL, offers the prospect of policy optimization from large pre-recorded datasets without online environment interaction. It addresses challenges with regard to the cost of data collection and safety, both of which are particularly pertinent to real-world applications of RL. Unfortunately, most off-policy algorithms perform poorly when learning from a fixed dataset. In this paper, we propose a novel offline RL algorithm to learn policies from data using a form of critic-regularized regression (CRR). We find that CRR performs surprisingly well and scales to tasks with high-dimensional state and action spaces -- outperforming several state-of-the-art offline RL algorithms by a significant margin on a wide range of benchmark tasks.
dm_control: Software and Tasks for Continuous Control
Jun 22, 2020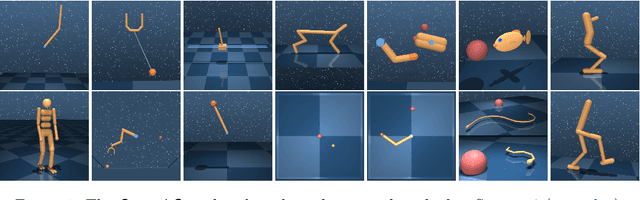

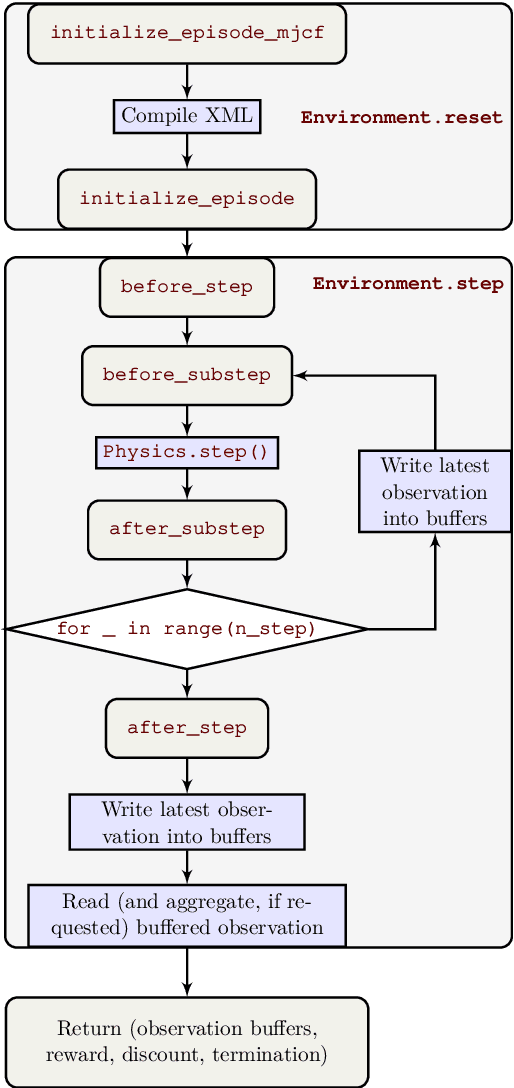
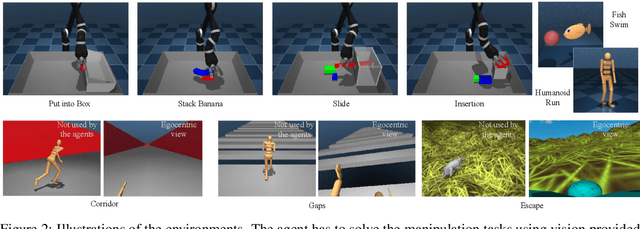
The dm_control software package is a collection of Python libraries and task suites for reinforcement learning agents in an articulated-body simulation. A MuJoCo wrapper provides convenient bindings to functions and data structures. The PyMJCF and Composer libraries enable procedural model manipulation and task authoring. The Control Suite is a fixed set of tasks with standardised structure, intended to serve as performance benchmarks. The Locomotion framework provides high-level abstractions and examples of locomotion tasks. A set of configurable manipulation tasks with a robot arm and snap-together bricks is also included. dm_control is publicly available at https://www.github.com/deepmind/dm_control
Divide-and-Conquer Monte Carlo Tree Search For Goal-Directed Planning
Apr 23, 2020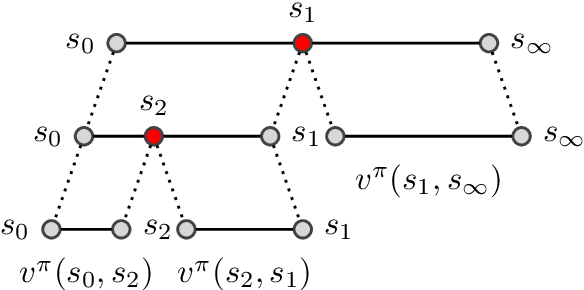


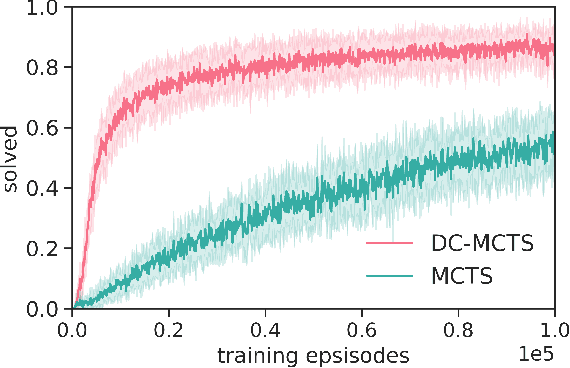
Standard planners for sequential decision making (including Monte Carlo planning, tree search, dynamic programming, etc.) are constrained by an implicit sequential planning assumption: The order in which a plan is constructed is the same in which it is executed. We consider alternatives to this assumption for the class of goal-directed Reinforcement Learning (RL) problems. Instead of an environment transition model, we assume an imperfect, goal-directed policy. This low-level policy can be improved by a plan, consisting of an appropriate sequence of sub-goals that guide it from the start to the goal state. We propose a planning algorithm, Divide-and-Conquer Monte Carlo Tree Search (DC-MCTS), for approximating the optimal plan by means of proposing intermediate sub-goals which hierarchically partition the initial tasks into simpler ones that are then solved independently and recursively. The algorithm critically makes use of a learned sub-goal proposal for finding appropriate partitions trees of new tasks based on prior experience. Different strategies for learning sub-goal proposals give rise to different planning strategies that strictly generalize sequential planning. We show that this algorithmic flexibility over planning order leads to improved results in navigation tasks in grid-worlds as well as in challenging continuous control environments.
Reusable neural skill embeddings for vision-guided whole body movement and object manipulation
Nov 15, 2019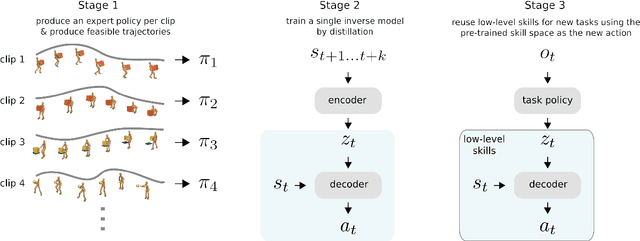
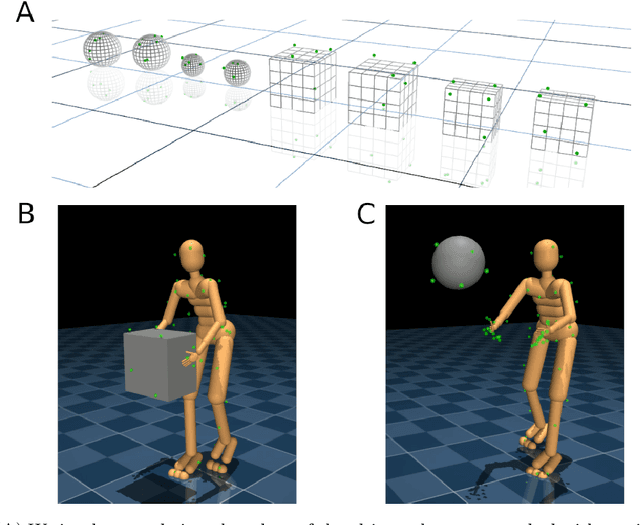
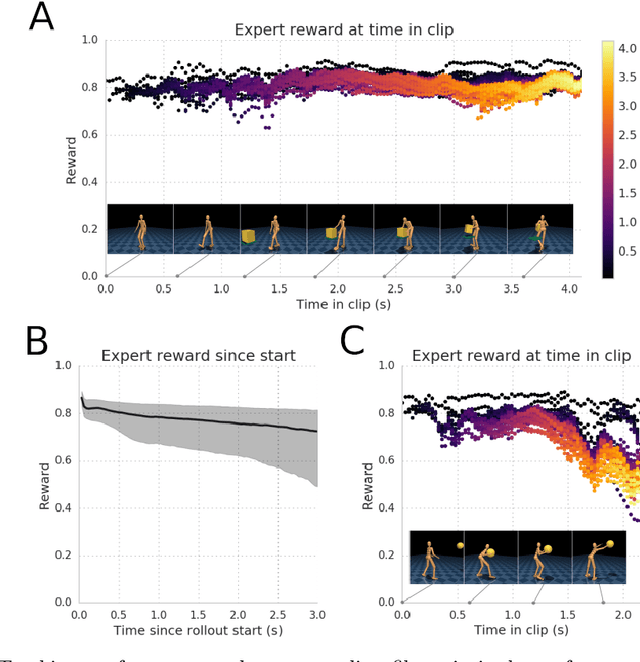
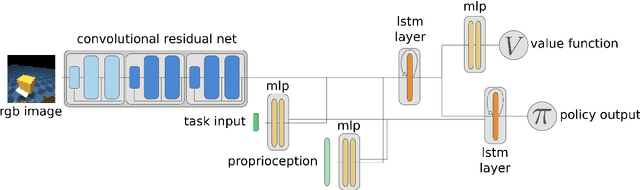
Both in simulation settings and robotics, there is an ambition to produce flexible control systems that can enable complex bodies to perform dynamic locomotion and natural object manipulation. In previous work, we developed a framework to train locomotor skills and reuse these skills for whole-body visuomotor tasks. Here, we extend this line of work to tasks involving whole body movement as well as visually guided manipulation of objects. This setting poses novel challenges in terms of task specification, exploration, and generalization. We develop an integrated approach consisting of a flexible motor primitive module, demonstrations, an instructed training regime as well as curricula in the form of task variations. We demonstrate the utility of our approach for solving challenging whole body tasks that require joint locomotion and manipulation, and characterize its behavioral robustness. We also provide a high-level overview video, see https://youtu.be/t0RDGSnE3cM .
Emergent Coordination Through Competition
Feb 21, 2019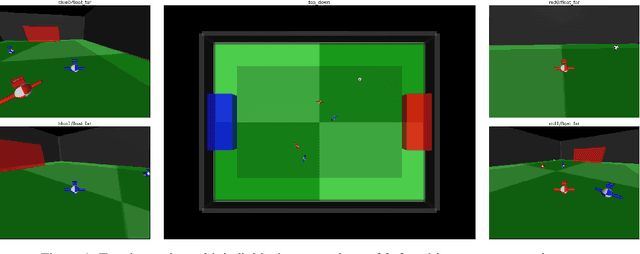
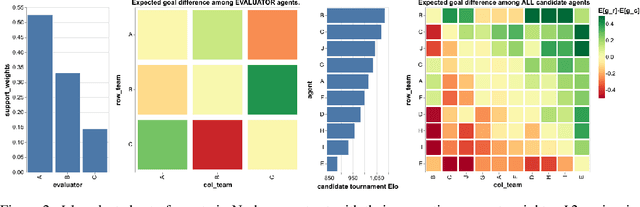
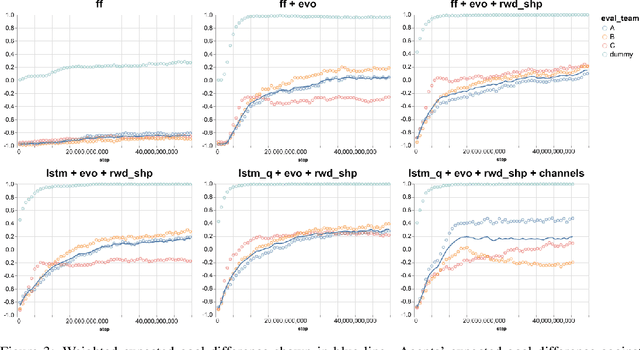
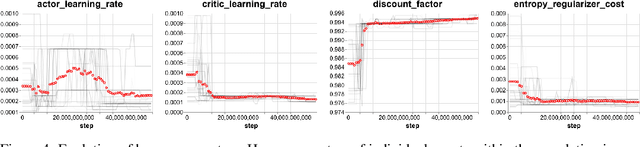
We study the emergence of cooperative behaviors in reinforcement learning agents by introducing a challenging competitive multi-agent soccer environment with continuous simulated physics. We demonstrate that decentralized, population-based training with co-play can lead to a progression in agents' behaviors: from random, to simple ball chasing, and finally showing evidence of cooperation. Our study highlights several of the challenges encountered in large scale multi-agent training in continuous control. In particular, we demonstrate that the automatic optimization of simple shaping rewards, not themselves conducive to co-operative behavior, can lead to long-horizon team behavior. We further apply an evaluation scheme, grounded by game theoretic principals, that can assess agent performance in the absence of pre-defined evaluation tasks or human baselines.