 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFogROS: An Adaptive Framework for Automating Fog Robotics Deployment
Aug 25, 2021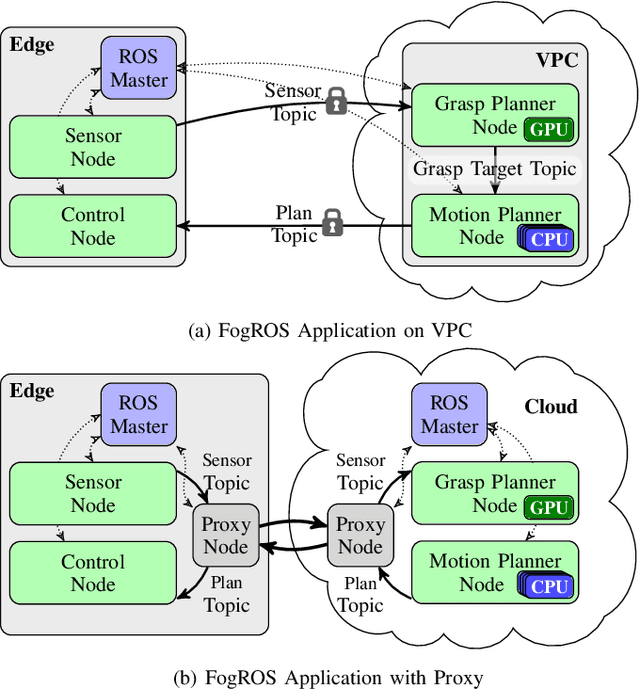
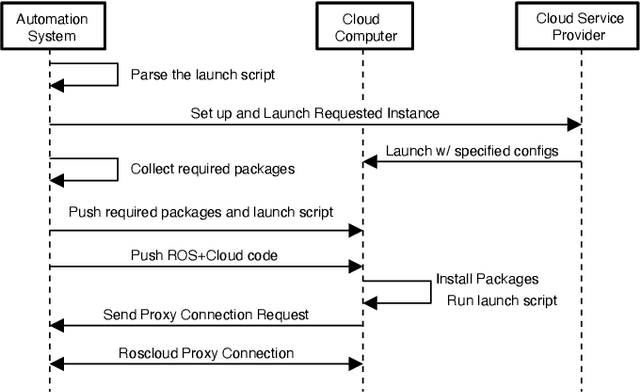
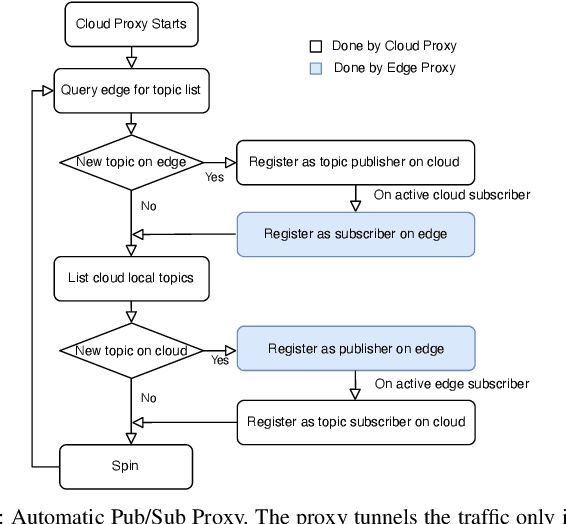
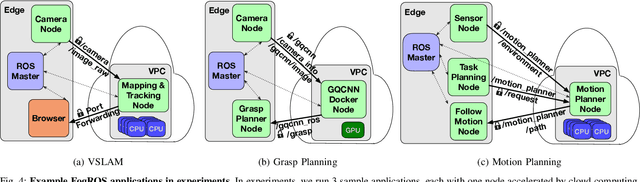
As many robot automation applications increasingly rely on multi-core processing or deep-learning models, cloud computing is becoming an attractive and economically viable resource for systems that do not contain high computing power onboard. Despite its immense computing capacity, it is often underused by the robotics and automation community due to lack of expertise in cloud computing and cloud-based infrastructure. Fog Robotics balances computing and data between cloud edge devices. We propose a software framework, FogROS, as an extension of the Robot Operating System (ROS), the de-facto standard for creating robot automation applications and components. It allows researchers to deploy components of their software to the cloud with minimal effort, and correspondingly gain access to additional computing cores, GPUs, FPGAs, and TPUs, as well as predeployed software made available by other researchers. FogROS allows a researcher to specify which components of their software will be deployed to the cloud and to what type of computing hardware. We evaluate FogROS on 3 examples: (1) simultaneous localization and mapping (ORB-SLAM2), (2) Dexterity Network (Dex-Net) GPU-based grasp planning, and (3) multi-core motion planning using a 96-core cloud-based server. In all three examples, a component is deployed to the cloud and accelerated with a small change in system launch configuration, while incurring additional latency of 1.2 s, 0.6 s, and 0.5 s due to network communication, the computation speed is improved by 2.6x, 6.0x and 34.2x, respectively. Code, videos, and supplementary material can be found at https://github.com/BerkeleyAutomation/FogROS.
C5T5: Controllable Generation of Organic Molecules with Transformers
Aug 23, 2021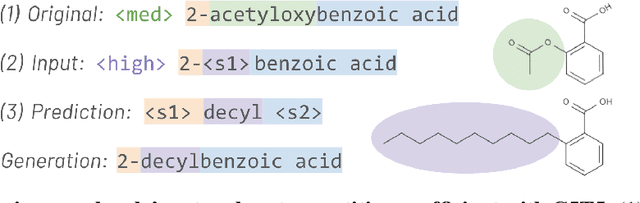

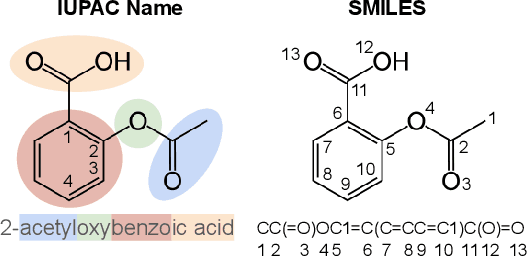
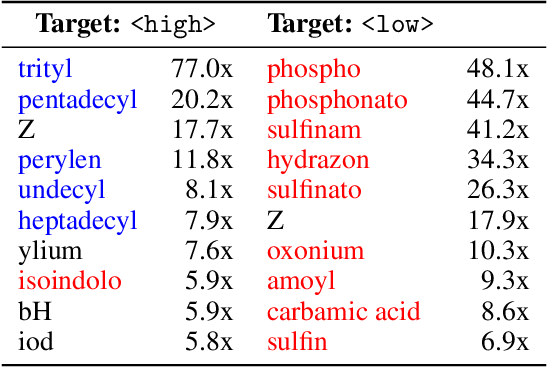
Methods for designing organic materials with desired properties have high potential impact across fields such as medicine, renewable energy, petrochemical engineering, and agriculture. However, using generative modeling to design substances with desired properties is difficult because candidate compounds must satisfy multiple constraints, including synthetic accessibility and other metrics that are intuitive to domain experts but challenging to quantify. We propose C5T5, a novel self-supervised pretraining method that enables transformers to make zero-shot select-and-replace edits, altering organic substances towards desired property values. C5T5 operates on IUPAC names -- a standardized molecular representation that intuitively encodes rich structural information for organic chemists but that has been largely ignored by the ML community. Our technique requires no edited molecule pairs to train and only a rough estimate of molecular properties, and it has the potential to model long-range dependencies and symmetric molecular structures more easily than graph-based methods. C5T5 also provides a powerful interface to domain experts: it grants users fine-grained control over the generative process by selecting and replacing IUPAC name fragments, which enables experts to leverage their intuitions about structure-activity relationships. We demonstrate C5T5's effectiveness on four physical properties relevant for drug discovery, showing that it learns successful and chemically intuitive strategies for altering molecules towards desired property values.
MADE: Exploration via Maximizing Deviation from Explored Regions
Jun 18, 2021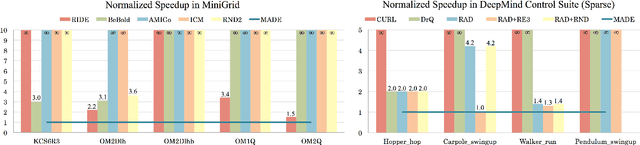
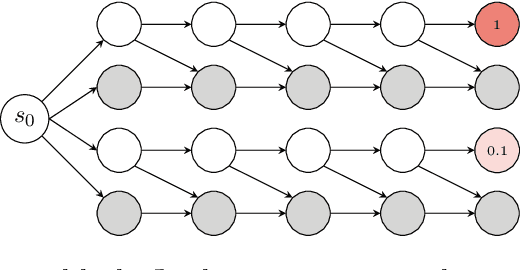
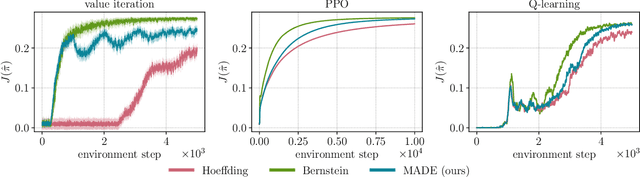

In online reinforcement learning (RL), efficient exploration remains particularly challenging in high-dimensional environments with sparse rewards. In low-dimensional environments, where tabular parameterization is possible, count-based upper confidence bound (UCB) exploration methods achieve minimax near-optimal rates. However, it remains unclear how to efficiently implement UCB in realistic RL tasks that involve non-linear function approximation. To address this, we propose a new exploration approach via \textit{maximizing} the deviation of the occupancy of the next policy from the explored regions. We add this term as an adaptive regularizer to the standard RL objective to balance exploration vs. exploitation. We pair the new objective with a provably convergent algorithm, giving rise to a new intrinsic reward that adjusts existing bonuses. The proposed intrinsic reward is easy to implement and combine with other existing RL algorithms to conduct exploration. As a proof of concept, we evaluate the new intrinsic reward on tabular examples across a variety of model-based and model-free algorithms, showing improvements over count-only exploration strategies. When tested on navigation and locomotion tasks from MiniGrid and DeepMind Control Suite benchmarks, our approach significantly improves sample efficiency over state-of-the-art methods. Our code is available at https://github.com/tianjunz/MADE.
Carbon Emissions and Large Neural Network Training
Apr 23, 2021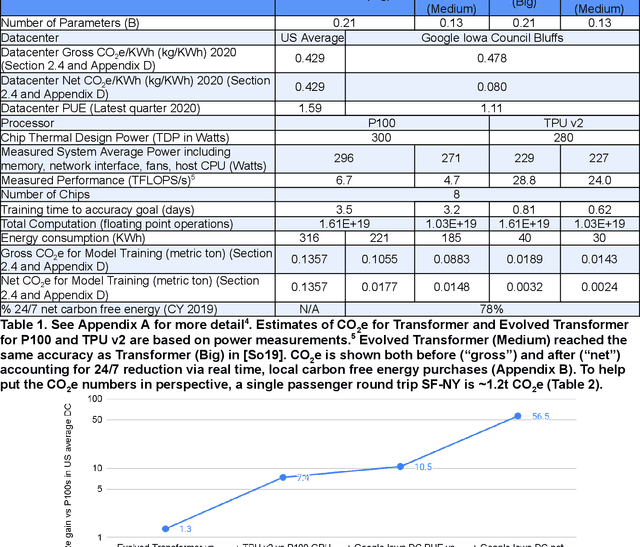

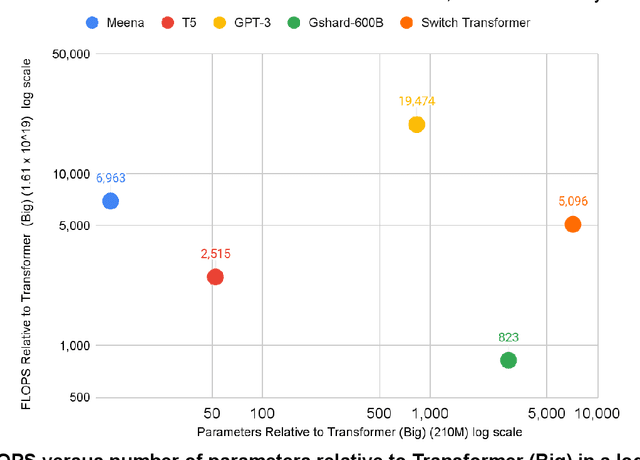
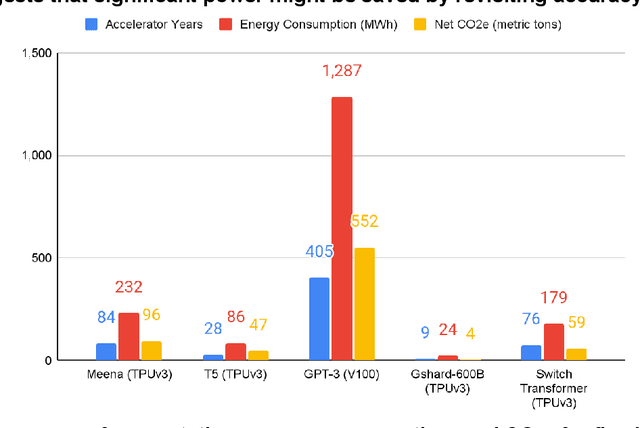
The computation demand for machine learning (ML) has grown rapidly recently, which comes with a number of costs. Estimating the energy cost helps measure its environmental impact and finding greener strategies, yet it is challenging without detailed information. We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3-and refine earlier estimates for the neural architecture search that found Evolved Transformer. We highlight the following opportunities to improve energy efficiency and CO2 equivalent emissions (CO2e): Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical. We are working to be more transparent about energy use and CO2e in our future research. To help reduce the carbon footprint of ML, we believe energy usage and CO2e should be a key metric in evaluating models, and we are collaborating with MLPerf developers to include energy usage during training and inference in this industry standard benchmark.
FetchSGD: Communication-Efficient Federated Learning with Sketching
Jul 15, 2020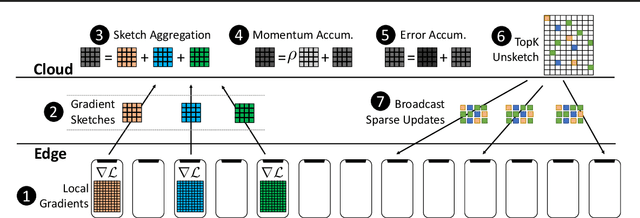

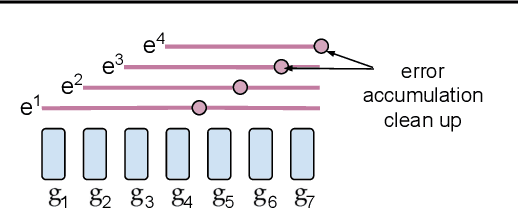
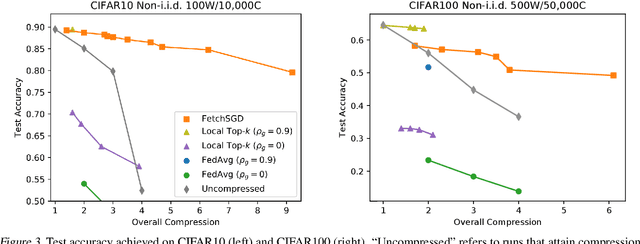
Existing approaches to federated learning suffer from a communication bottleneck as well as convergence issues due to sparse client participation. In this paper we introduce a novel algorithm, called FetchSGD, to overcome these challenges. FetchSGD compresses model updates using a Count Sketch, and then takes advantage of the mergeability of sketches to combine model updates from many workers. A key insight in the design of FetchSGD is that, because the Count Sketch is linear, momentum and error accumulation can both be carried out within the sketch. This allows the algorithm to move momentum and error accumulation from clients to the central aggregator, overcoming the challenges of sparse client participation while still achieving high compression rates and good convergence. We prove that FetchSGD has favorable convergence guarantees, and we demonstrate its empirical effectiveness by training two residual networks and a transformer model.
HyperSched: Dynamic Resource Reallocation for Model Development on a Deadline
Jan 08, 2020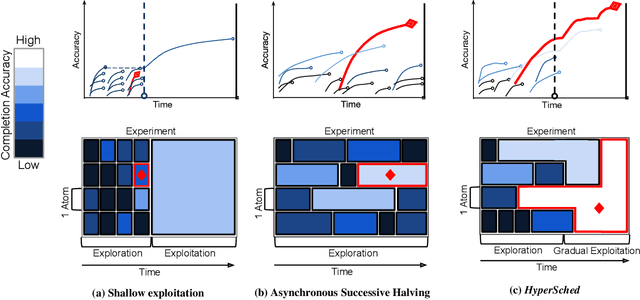
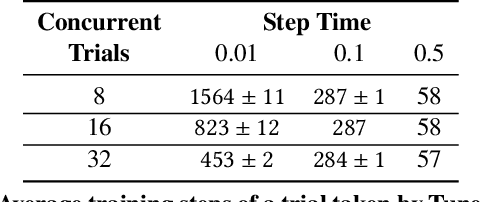
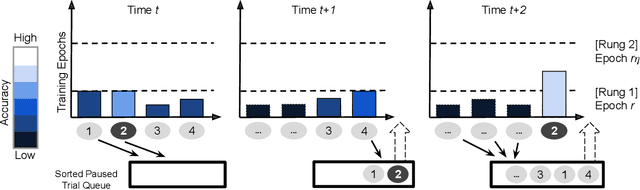
Prior research in resource scheduling for machine learning training workloads has largely focused on minimizing job completion times. Commonly, these model training workloads collectively search over a large number of parameter values that control the learning process in a hyperparameter search. It is preferable to identify and maximally provision the best-performing hyperparameter configuration (trial) to achieve the highest accuracy result as soon as possible. To optimally trade-off evaluating multiple configurations and training the most promising ones by a fixed deadline, we design and build HyperSched -- a dynamic application-level resource scheduler to track, identify, and preferentially allocate resources to the best performing trials to maximize accuracy by the deadline. HyperSched leverages three properties of a hyperparameter search workload over-looked in prior work - trial disposability, progressively identifiable rankings among different configurations, and space-time constraints - to outperform standard hyperparameter search algorithms across a variety of benchmarks.
Domain-Aware Dynamic Networks
Nov 26, 2019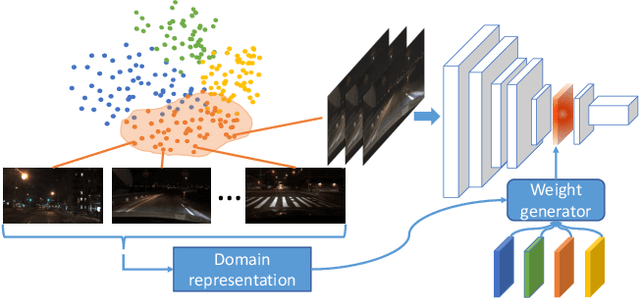
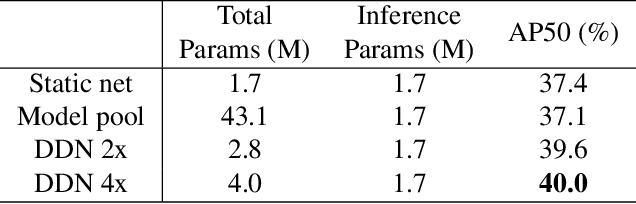
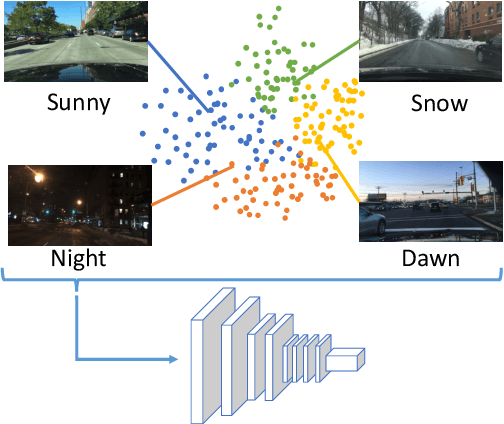
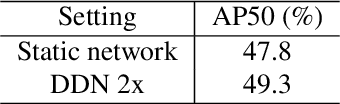
Deep neural networks with more parameters and FLOPs have higher capacity and generalize better to diverse domains. But to be deployed on edge devices, the model's complexity has to be constrained due to limited compute resource. In this work, we propose a method to improve the model capacity without increasing inference-time complexity. Our method is based on an assumption of data locality: for an edge device, within a short period of time, the input data to the device are sampled from a single domain with relatively low diversity. Therefore, it is possible to utilize a specialized, low-complexity model to achieve good performance in that input domain. To leverage this, we propose Domain-aware Dynamic Network (DDN), which is a high-capacity dynamic network in which each layer contains multiple weights. During inference, based on the input domain, DDN dynamically combines those weights into one single weight that specializes in the given domain. This way, DDN can keep the inference-time complexity low but still maintain a high capacity. Experiments show that without increasing the parameters, FLOPs, and actual latency, DDN achieves up to 2.6\% higher AP50 than a static network on the BDD100K object-detection benchmark.
A View on Deep Reinforcement Learning in System Optimization
Sep 04, 2019
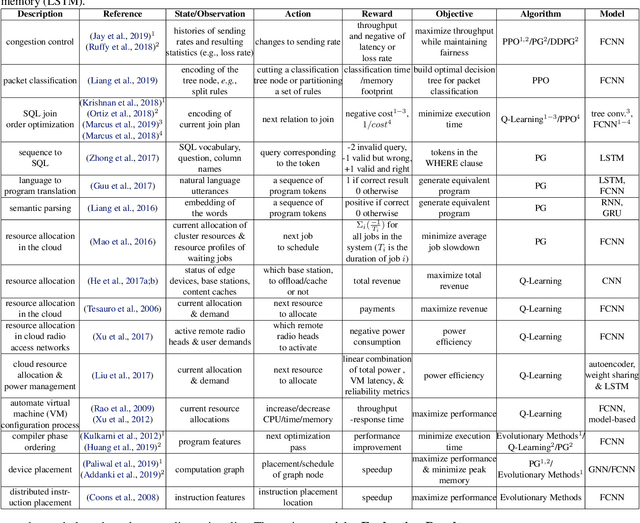
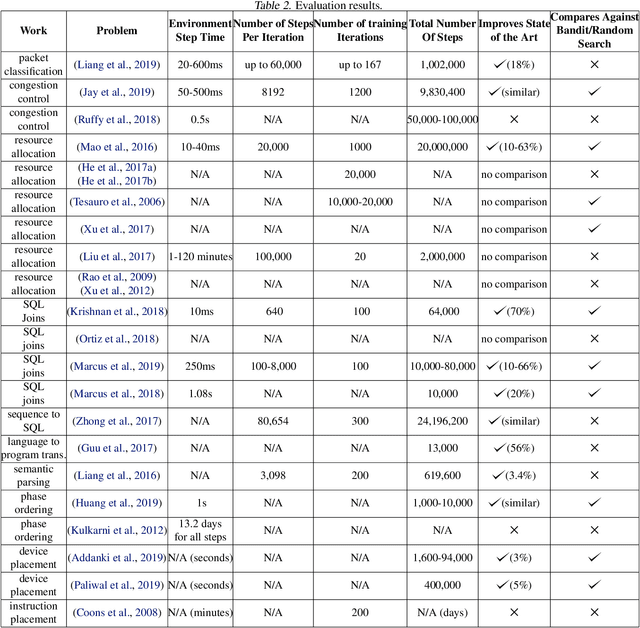
Many real-world systems problems require reasoning about the long term consequences of actions taken to configure and manage the system. These problems with delayed and often sequentially aggregated reward, are often inherently reinforcement learning problems and present the opportunity to leverage the recent substantial advances in deep reinforcement learning. However, in some cases, it is not clear why deep reinforcement learning is a good fit for the problem. Sometimes, it does not perform better than the state-of-the-art solutions. And in other cases, random search or greedy algorithms could outperform deep reinforcement learning. In this paper, we review, discuss, and evaluate the recent trends of using deep reinforcement learning in system optimization. We propose a set of essential metrics to guide future works in evaluating the efficacy of using deep reinforcement learning in system optimization. Our evaluation includes challenges, the types of problems, their formulation in the deep reinforcement learning setting, embedding, the model used, efficiency, and robustness. We conclude with a discussion on open challenges and potential directions for pushing further the integration of reinforcement learning in system optimization.
ANODEV2: A Coupled Neural ODE Evolution Framework
Jun 10, 2019

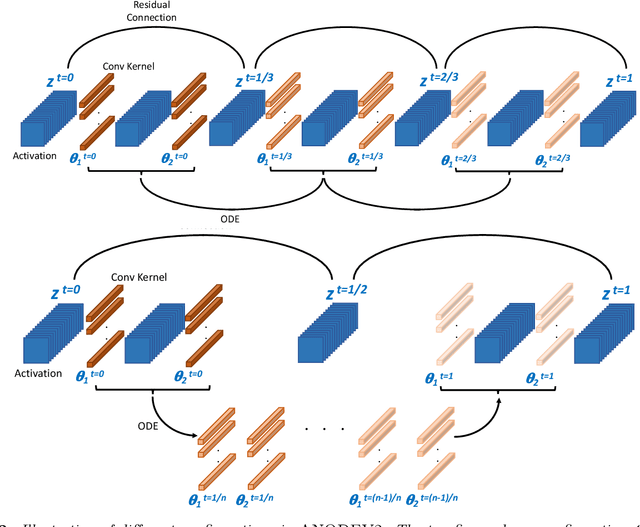

It has been observed that residual networks can be viewed as the explicit Euler discretization of an Ordinary Differential Equation (ODE). This observation motivated the introduction of so-called Neural ODEs, which allow more general discretization schemes with adaptive time stepping. Here, we propose ANODEV2, which is an extension of this approach that also allows evolution of the neural network parameters, in a coupled ODE-based formulation. The Neural ODE method introduced earlier is in fact a special case of this new more general framework. We present the formulation of ANODEV2, derive optimality conditions, and implement a coupled reaction-diffusion-advection version of this framework in PyTorch. We present empirical results using several different configurations of ANODEV2, testing them on multiple models on CIFAR-10. We report results showing that this coupled ODE-based framework is indeed trainable, and that it achieves higher accuracy, as compared to the baseline models as well as the recently-proposed Neural ODE approach.
On the Computational Inefficiency of Large Batch Sizes for Stochastic Gradient Descent
Nov 30, 2018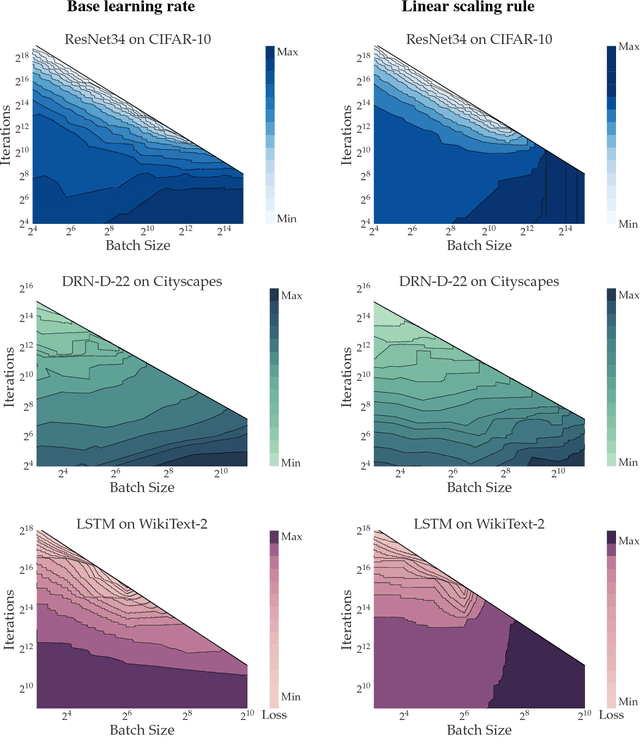
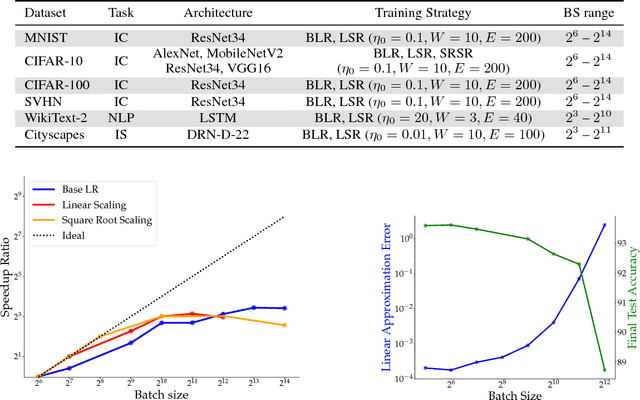
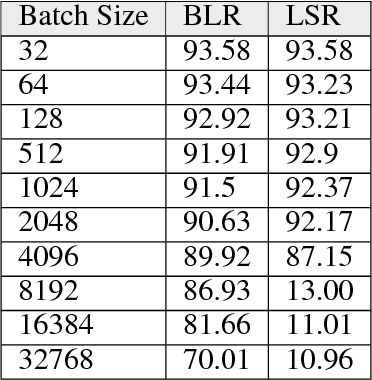
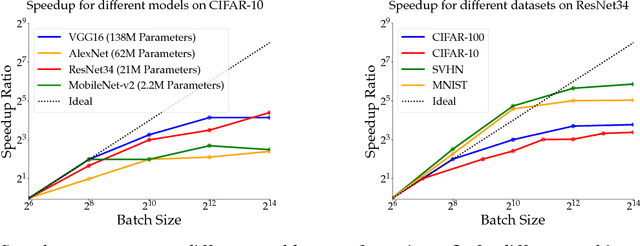
Increasing the mini-batch size for stochastic gradient descent offers significant opportunities to reduce wall-clock training time, but there are a variety of theoretical and systems challenges that impede the widespread success of this technique. We investigate these issues, with an emphasis on time to convergence and total computational cost, through an extensive empirical analysis of network training across several architectures and problem domains, including image classification, image segmentation, and language modeling. Although it is common practice to increase the batch size in order to fully exploit available computational resources, we find a substantially more nuanced picture. Our main finding is that across a wide range of network architectures and problem domains, increasing the batch size beyond a certain point yields no decrease in wall-clock time to convergence for \emph{either} train or test loss. This batch size is usually substantially below the capacity of current systems. We show that popular training strategies for large batch size optimization begin to fail before we can populate all available compute resources, and we show that the point at which these methods break down depends more on attributes like model architecture and data complexity than it does directly on the size of the dataset.