 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXShare: Collaborative in-Batch Expert Sharing for Faster MoE Inference
Feb 06, 2026Mixture-of-Experts (MoE) architectures are increasingly used to efficiently scale large language models. However, in production inference, request batching and speculative decoding significantly amplify expert activation, eroding these efficiency benefits. We address this issue by modeling batch-aware expert selection as a modular optimization problem and designing efficient greedy algorithms for different deployment settings. The proposed method, namely XShare, requires no retraining and dynamically adapts to each batch by maximizing the total gating score of selected experts. It reduces expert activation by up to 30% under standard batching, cuts peak GPU load by up to 3x in expert-parallel deployments, and achieves up to 14% throughput gains in speculative decoding via hierarchical, correlation-aware expert selection even if requests in a batch drawn from heterogeneous datasets.
Federated Learning Clients Clustering with Adaptation to Data Drifts
Nov 03, 2024



Federated Learning (FL) enables deep learning model training across edge devices and protects user privacy by retaining raw data locally. Data heterogeneity in client distributions slows model convergence and leads to plateauing with reduced precision. Clustered FL solutions address this by grouping clients with statistically similar data and training models for each cluster. However, maintaining consistent client similarity within each group becomes challenging when data drifts occur, significantly impacting model accuracy. In this paper, we introduce Fielding, a clustered FL framework that handles data drifts promptly with low overheads. Fielding detects drifts on all clients and performs selective label distribution-based re-clustering to balance cluster optimality and model performance, remaining robust to malicious clients and varied heterogeneity degrees. Our evaluations show that Fielding improves model final accuracy by 1.9%-5.9% and reaches target accuracies 1.16x-2.61x faster.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
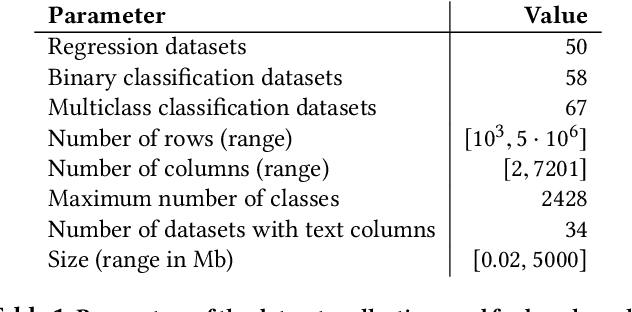
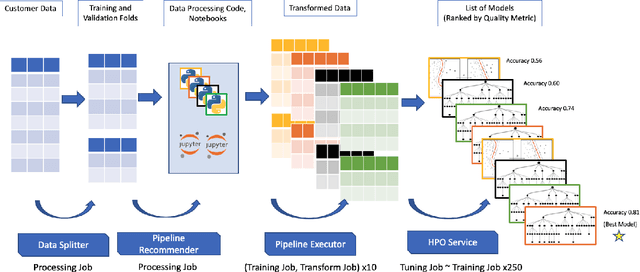
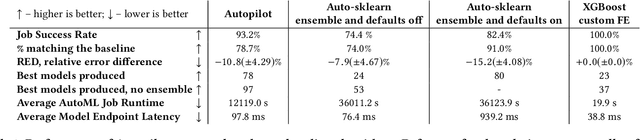
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
Sketch and Scale: Geo-distributed tSNE and UMAP
Nov 11, 2020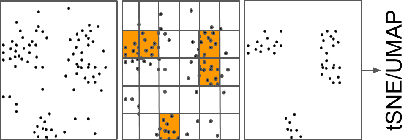
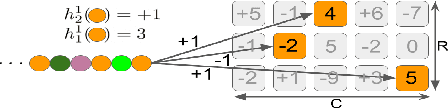
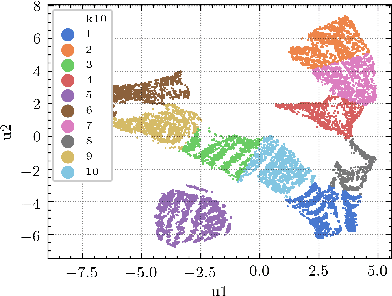

Running machine learning analytics over geographically distributed datasets is a rapidly arising problem in the world of data management policies ensuring privacy and data security. Visualizing high dimensional data using tools such as t-distributed Stochastic Neighbor Embedding (tSNE) and Uniform Manifold Approximation and Projection (UMAP) became common practice for data scientists. Both tools scale poorly in time and memory. While recent optimizations showed successful handling of 10,000 data points, scaling beyond million points is still challenging. We introduce a novel framework: Sketch and Scale (SnS). It leverages a Count Sketch data structure to compress the data on the edge nodes, aggregates the reduced size sketches on the master node, and runs vanilla tSNE or UMAP on the summary, representing the densest areas, extracted from the aggregated sketch. We show this technique to be fully parallel, scale linearly in time, logarithmically in memory, and communication, making it possible to analyze datasets with many millions, potentially billions of data points, spread across several data centers around the globe. We demonstrate the power of our method on two mid-size datasets: cancer data with 52 million 35-band pixels from multiple images of tumor biopsies; and astrophysics data of 100 million stars with multi-color photometry from the Sloan Digital Sky Survey (SDSS).
Practical and sample efficient zero-shot HPO
Jul 27, 2020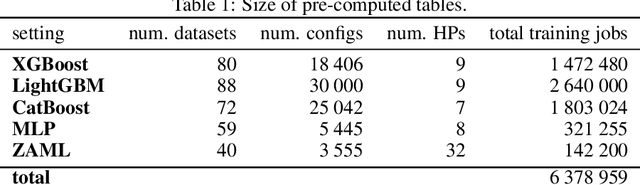
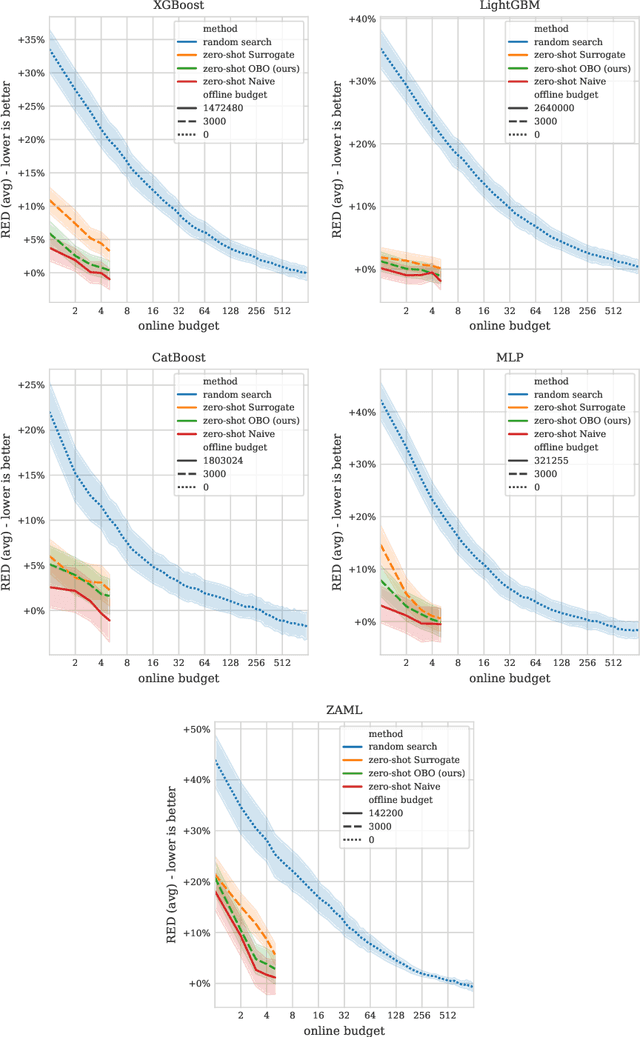
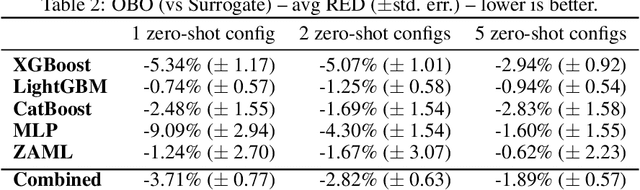
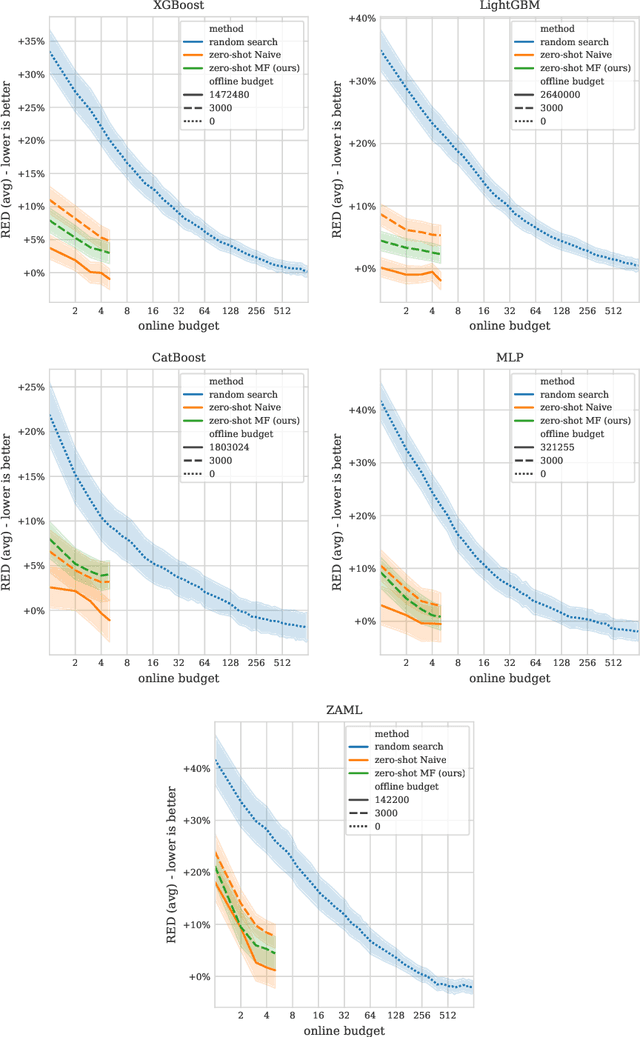
Zero-shot hyperparameter optimization (HPO) is a simple yet effective use of transfer learning for constructing a small list of hyperparameter (HP) configurations that complement each other. That is to say, for any given dataset, at least one of them is expected to perform well. Current techniques for obtaining this list are computationally expensive as they rely on running training jobs on a diverse collection of datasets and a large collection of randomly drawn HPs. This cost is especially problematic in environments where the space of HPs is regularly changing due to new algorithm versions, or changing architectures of deep networks. We provide an overview of available approaches and introduce two novel techniques to handle the problem. The first is based on a surrogate model and adaptively chooses pairs of dataset, configuration to query. The second, for settings where finding, tuning and testing a surrogate model is problematic, is a multi-fidelity technique combining HyperBand with submodular optimization. We benchmark our methods experimentally on five tasks (XGBoost, LightGBM, CatBoost, MLP and AutoML) and show significant improvement in accuracy compared to standard zero-shot HPO with the same training budget. In addition to contributing new algorithms, we provide an extensive study of the zero-shot HPO technique resulting in (1) default hyper-parameters for popular algorithms that would benefit the community using them, (2) massive lookup tables to further the research of hyper-parameter tuning.
FetchSGD: Communication-Efficient Federated Learning with Sketching
Jul 15, 2020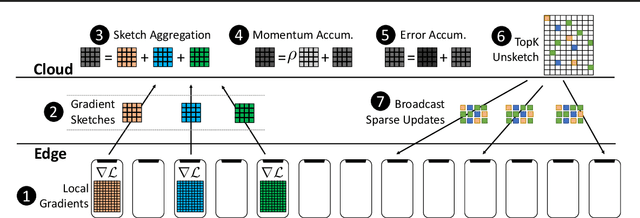

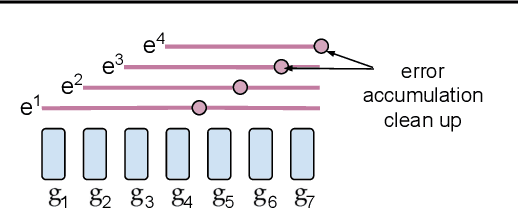
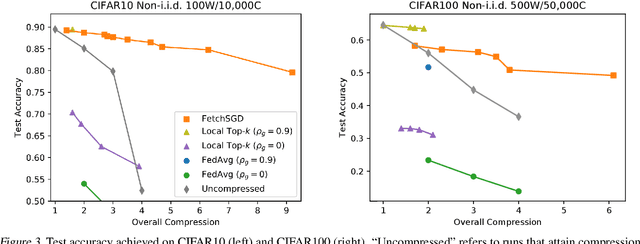
Existing approaches to federated learning suffer from a communication bottleneck as well as convergence issues due to sparse client participation. In this paper we introduce a novel algorithm, called FetchSGD, to overcome these challenges. FetchSGD compresses model updates using a Count Sketch, and then takes advantage of the mergeability of sketches to combine model updates from many workers. A key insight in the design of FetchSGD is that, because the Count Sketch is linear, momentum and error accumulation can both be carried out within the sketch. This allows the algorithm to move momentum and error accumulation from clients to the central aggregator, overcoming the challenges of sparse client participation while still achieving high compression rates and good convergence. We prove that FetchSGD has favorable convergence guarantees, and we demonstrate its empirical effectiveness by training two residual networks and a transformer model.
Streaming Quantiles Algorithms with Small Space and Update Time
Jun 29, 2019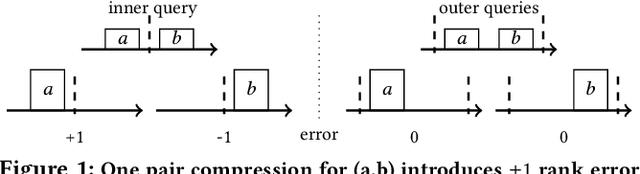
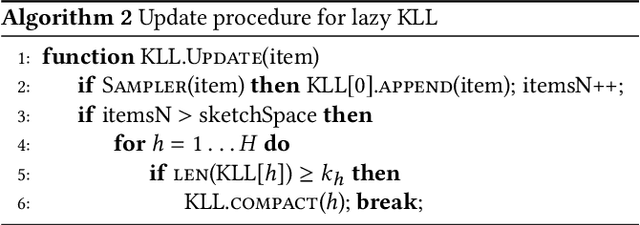

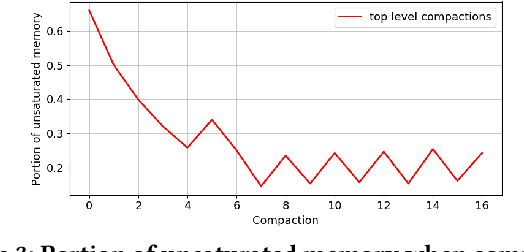
Approximating quantiles and distributions over streaming data has been studied for roughly two decades now. Recently, Karnin, Lang, and Liberty proposed the first asymptotically optimal algorithm for doing so. This manuscript complements their theoretical result by providing a practical variants of their algorithm with improved constants. For a given sketch size, our techniques provably reduce the upper bound on the sketch error by a factor of two. These improvements are verified experimentally. Our modified quantile sketch improves the latency as well by reducing the worst case update time from $O(1/\varepsilon)$ down to $O(\log (1/\varepsilon))$. We also suggest two algorithms for weighted item streams which offer improved asymptotic update times compared to na\"ive extensions. Finally, we provide a specialized data structure for these sketches which reduces both their memory footprints and update times.
Communication-efficient distributed SGD with Sketching
Mar 12, 2019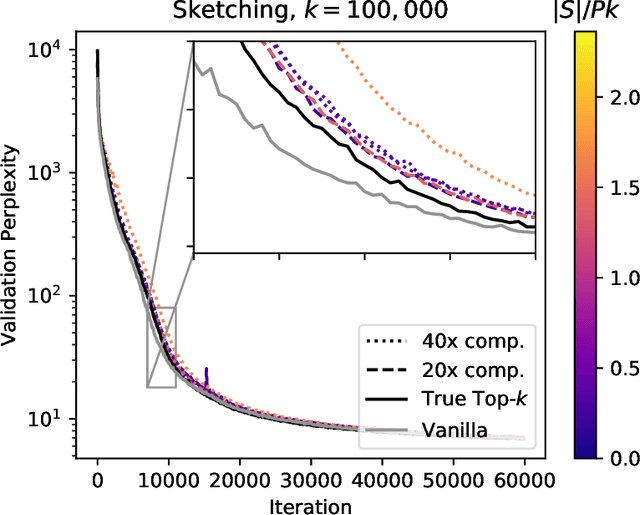
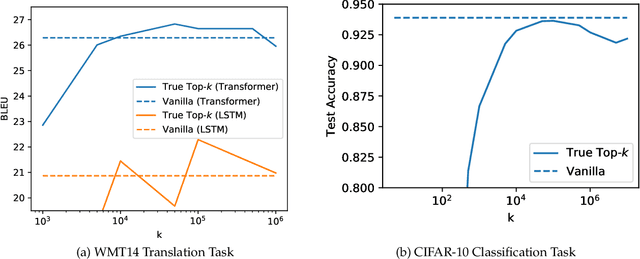
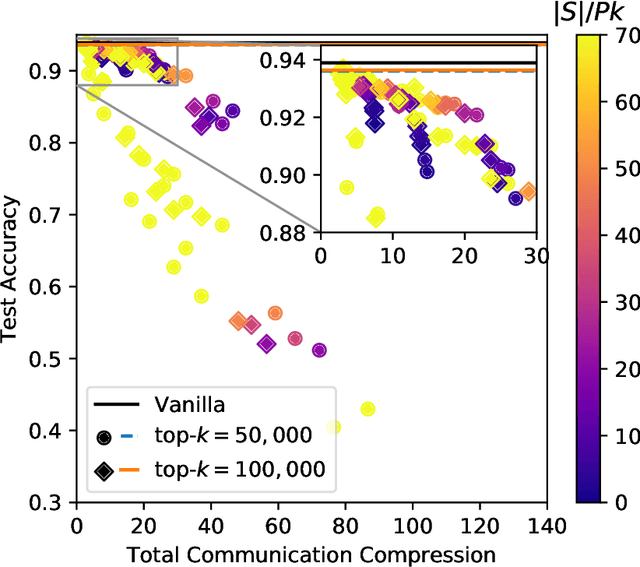
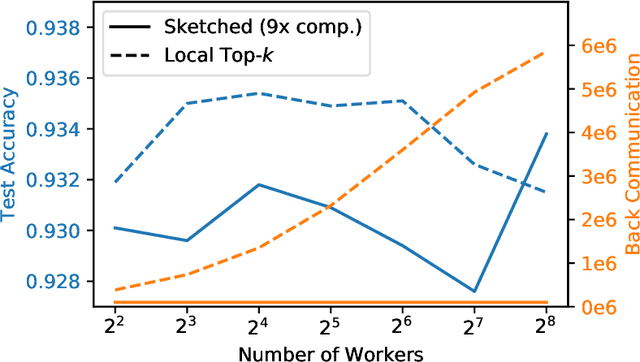
Large-scale distributed training of neural networks is often limited by network bandwidth, wherein the communication time overwhelms the local computation time. Motivated by the success of sketching methods in sub-linear/streaming algorithms, we propose a sketching-based approach to minimize the communication costs between nodes without losing accuracy. In our proposed method, workers in a distributed, synchronous training setting send sketches of their gradient vectors to the parameter server instead of the full gradient vector. Leveraging the theoretical properties of sketches, we show that this method recovers the favorable convergence guarantees of single-machine top-$k$ SGD. Furthermore, when applied to a model with $d$ dimensions on $W$ workers, our method requires only $\Theta(kW)$ bytes of communication, compared to $\Omega(dW)$ for vanilla distributed SGD. To validate our method, we run experiments using a residual network trained on the CIFAR-10 dataset. We achieve no drop in validation accuracy with a compression ratio of 4, or about 1 percentage point drop with a compression ratio of 8. We also demonstrate that our method scales to many workers.
DreamNLP: Novel NLP System for Clinical Report Metadata Extraction using Count Sketch Data Streaming Algorithm: Preliminary Results
Aug 26, 2018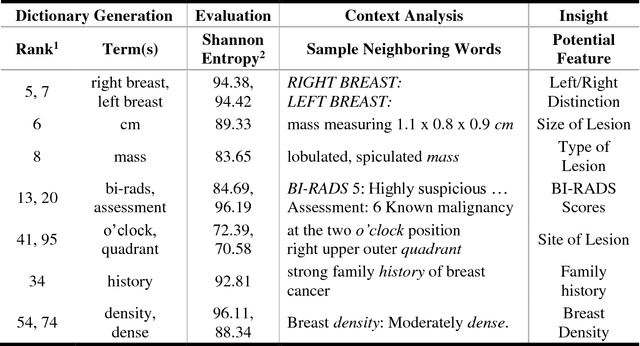
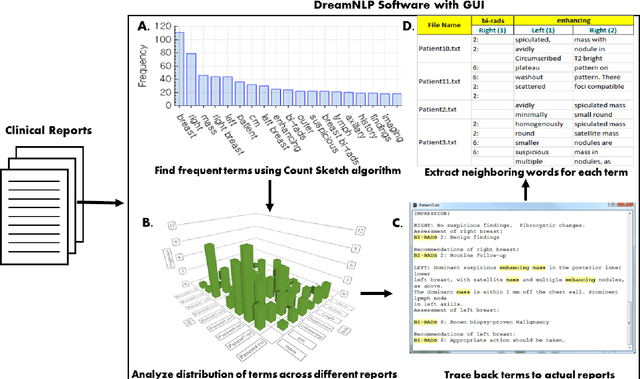
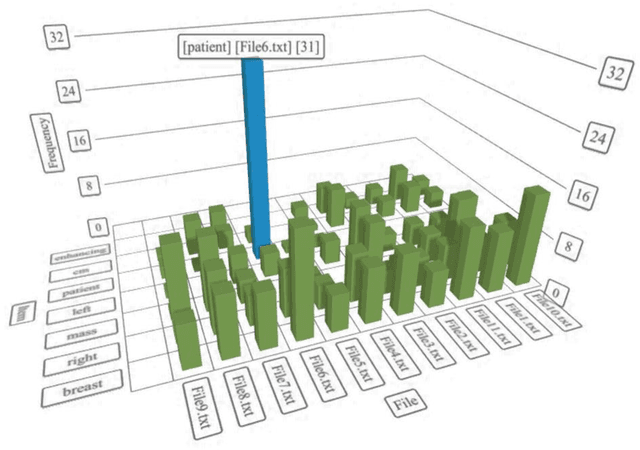
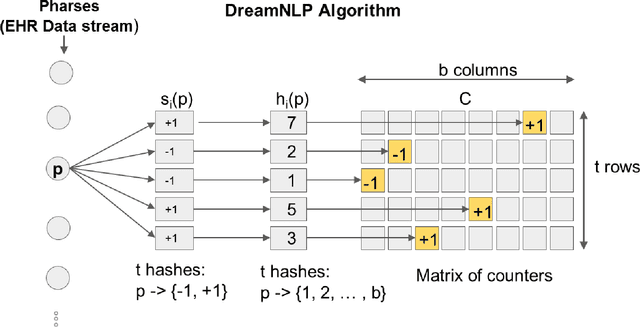
Extracting information from electronic health records (EHR) is a challenging task since it requires prior knowledge of the reports and some natural language processing algorithm (NLP). With the growing number of EHR implementations, such knowledge is increasingly challenging to obtain in an efficient manner. We address this challenge by proposing a novel methodology to analyze large sets of EHRs using a modified Count Sketch data streaming algorithm termed DreamNLP. By using DreamNLP, we generate a dictionary of frequently occurring terms or heavy hitters in the EHRs using low computational memory compared to conventional counting approach other NLP programs use. We demonstrate the extraction of the most important breast diagnosis features from the EHRs in a set of patients that underwent breast imaging. Based on the analysis, extraction of these terms would be useful for defining important features for downstream tasks such as machine learning for precision medicine.