 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Model Size on Worst-Group Generalization
Dec 08, 2021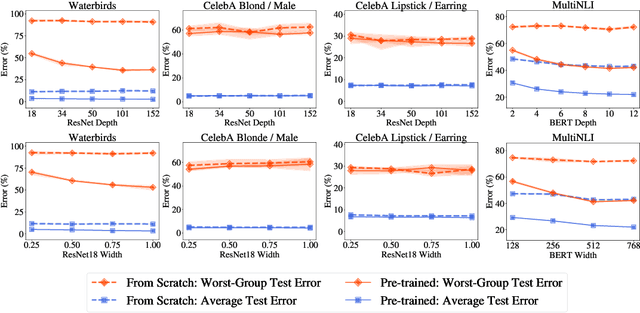
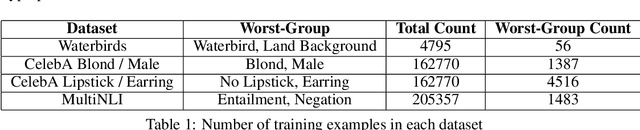
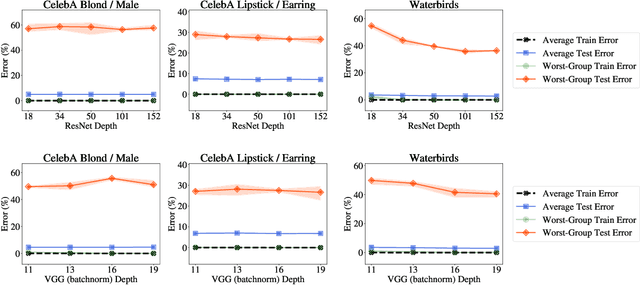
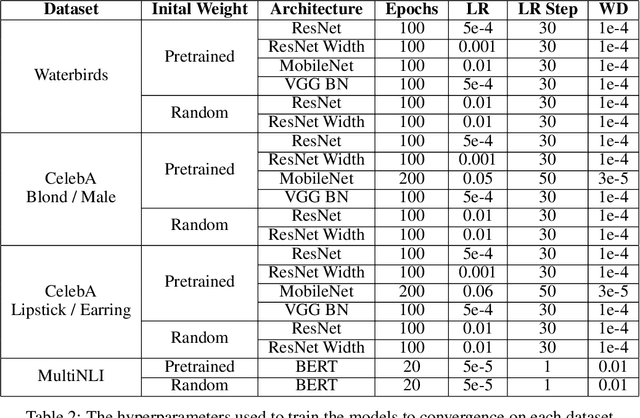
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
Hindsight Task Relabelling: Experience Replay for Sparse Reward Meta-RL
Dec 02, 2021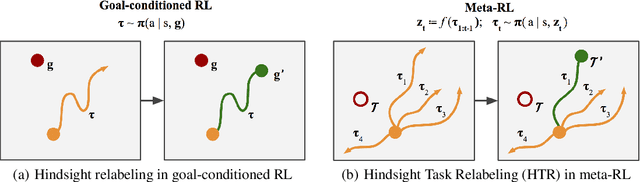

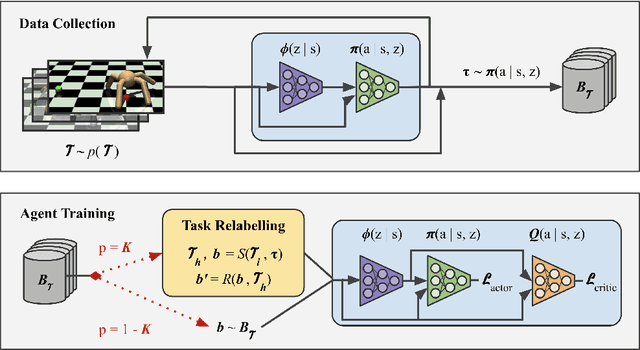
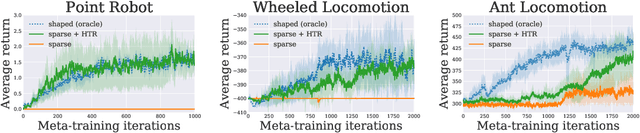
Meta-reinforcement learning (meta-RL) has proven to be a successful framework for leveraging experience from prior tasks to rapidly learn new related tasks, however, current meta-RL approaches struggle to learn in sparse reward environments. Although existing meta-RL algorithms can learn strategies for adapting to new sparse reward tasks, the actual adaptation strategies are learned using hand-shaped reward functions, or require simple environments where random exploration is sufficient to encounter sparse reward. In this paper, we present a formulation of hindsight relabeling for meta-RL, which relabels experience during meta-training to enable learning to learn entirely using sparse reward. We demonstrate the effectiveness of our approach on a suite of challenging sparse reward goal-reaching environments that previously required dense reward during meta-training to solve. Our approach solves these environments using the true sparse reward function, with performance comparable to training with a proxy dense reward function.
Grounded Graph Decoding Improves Compositional Generalization in Question Answering
Nov 05, 2021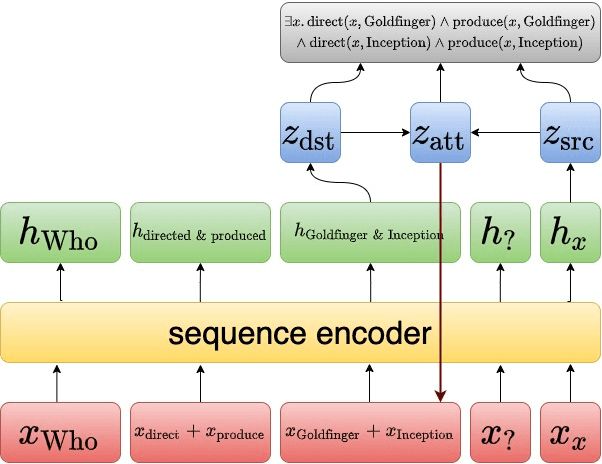
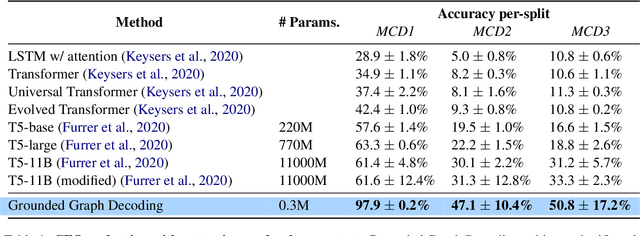
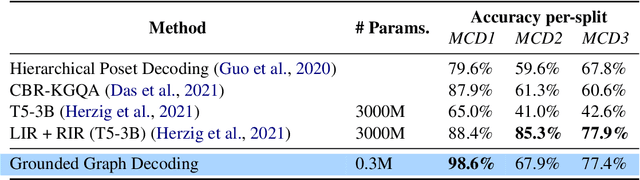
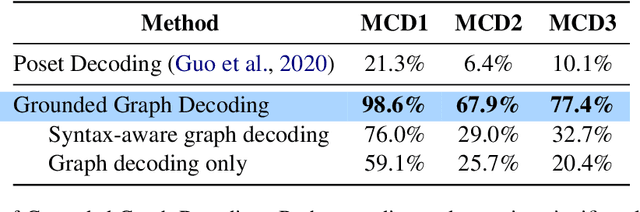
Question answering models struggle to generalize to novel compositions of training patterns, such to longer sequences or more complex test structures. Current end-to-end models learn a flat input embedding which can lose input syntax context. Prior approaches improve generalization by learning permutation invariant models, but these methods do not scale to more complex train-test splits. We propose Grounded Graph Decoding, a method to improve compositional generalization of language representations by grounding structured predictions with an attention mechanism. Grounding enables the model to retain syntax information from the input in thereby significantly improving generalization over complex inputs. By predicting a structured graph containing conjunctions of query clauses, we learn a group invariant representation without making assumptions on the target domain. Our model significantly outperforms state-of-the-art baselines on the Compositional Freebase Questions (CFQ) dataset, a challenging benchmark for compositional generalization in question answering. Moreover, we effectively solve the MCD1 split with 98% accuracy.
C-Planning: An Automatic Curriculum for Learning Goal-Reaching Tasks
Oct 22, 2021
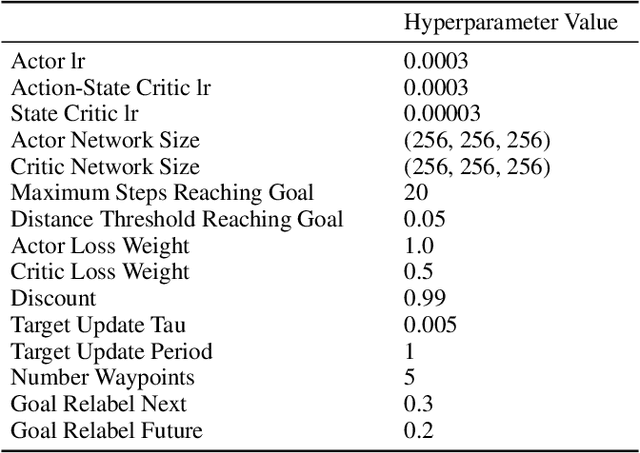

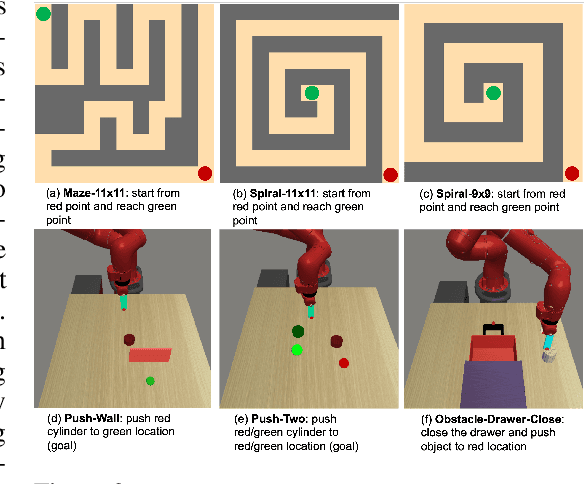
Goal-conditioned reinforcement learning (RL) can solve tasks in a wide range of domains, including navigation and manipulation, but learning to reach distant goals remains a central challenge to the field. Learning to reach such goals is particularly hard without any offline data, expert demonstrations, and reward shaping. In this paper, we propose an algorithm to solve the distant goal-reaching task by using search at training time to automatically generate a curriculum of intermediate states. Our algorithm, Classifier-Planning (C-Planning), frames the learning of the goal-conditioned policies as expectation maximization: the E-step corresponds to planning an optimal sequence of waypoints using graph search, while the M-step aims to learn a goal-conditioned policy to reach those waypoints. Unlike prior methods that combine goal-conditioned RL with graph search, ours performs search only during training and not testing, significantly decreasing the compute costs of deploying the learned policy. Empirically, we demonstrate that our method is more sample efficient than prior methods. Moreover, it is able to solve very long horizons manipulation and navigation tasks, tasks that prior goal-conditioned methods and methods based on graph search fail to solve.
Taxonomizing local versus global structure in neural network loss landscapes
Jul 23, 2021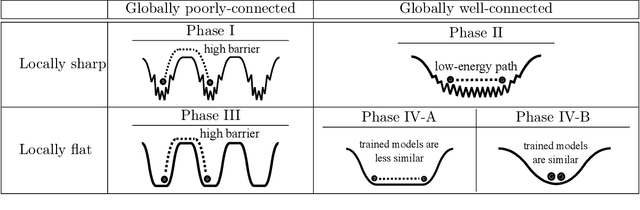
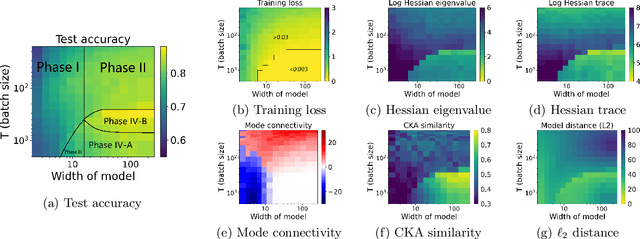
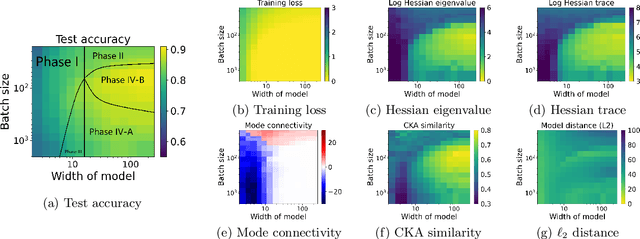
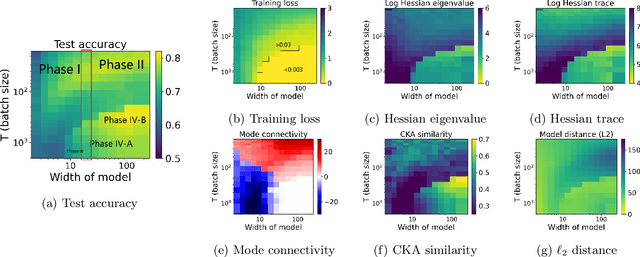
Viewing neural network models in terms of their loss landscapes has a long history in the statistical mechanics approach to learning, and in recent years it has received attention within machine learning proper. Among other things, local metrics (such as the smoothness of the loss landscape) have been shown to correlate with global properties of the model (such as good generalization). Here, we perform a detailed empirical analysis of the loss landscape structure of thousands of neural network models, systematically varying learning tasks, model architectures, and/or quantity/quality of data. By considering a range of metrics that attempt to capture different aspects of the loss landscape, we demonstrate that the best test accuracy is obtained when: the loss landscape is globally well-connected; ensembles of trained models are more similar to each other; and models converge to locally smooth regions. We also show that globally poorly-connected landscapes can arise when models are small or when they are trained to lower quality data; and that, if the loss landscape is globally poorly-connected, then training to zero loss can actually lead to worse test accuracy. Based on these results, we develop a simple one-dimensional model with load-like and temperature-like parameters, we introduce the notion of an \emph{effective loss landscape} depending on these parameters, and we interpret our results in terms of a \emph{rugged convexity} of the loss landscape. When viewed through this lens, our detailed empirical results shed light on phases of learning (and consequent double descent behavior), fundamental versus incidental determinants of good generalization, the role of load-like and temperature-like parameters in the learning process, different influences on the loss landscape from model and data, and the relationships between local and global metrics, all topics of recent interest.
Accelerating Quadratic Optimization with Reinforcement Learning
Jul 22, 2021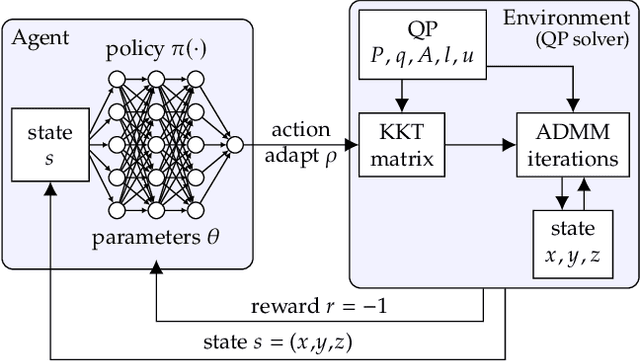
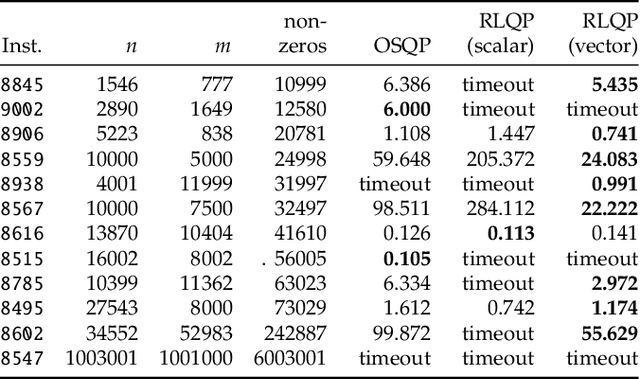
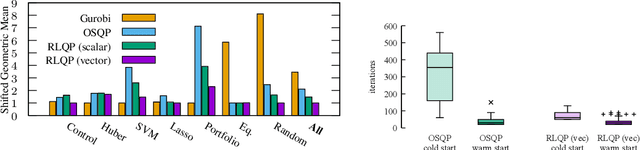
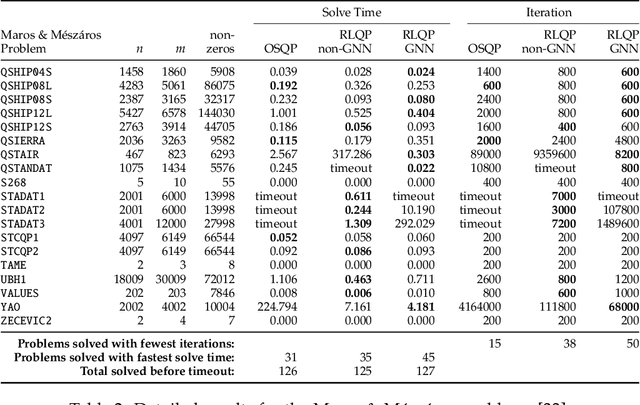
First-order methods for quadratic optimization such as OSQP are widely used for large-scale machine learning and embedded optimal control, where many related problems must be rapidly solved. These methods face two persistent challenges: manual hyperparameter tuning and convergence time to high-accuracy solutions. To address these, we explore how Reinforcement Learning (RL) can learn a policy to tune parameters to accelerate convergence. In experiments with well-known QP benchmarks we find that our RL policy, RLQP, significantly outperforms state-of-the-art QP solvers by up to 3x. RLQP generalizes surprisingly well to previously unseen problems with varying dimension and structure from different applications, including the QPLIB, Netlib LP and Maros-Meszaros problems. Code for RLQP is available at https://github.com/berkeleyautomation/rlqp.
Learning Space Partitions for Path Planning
Jul 14, 2021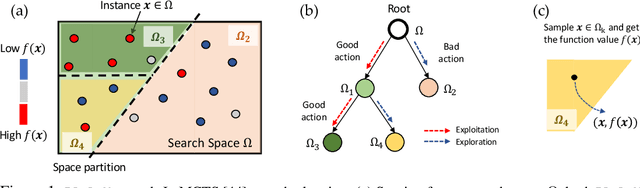

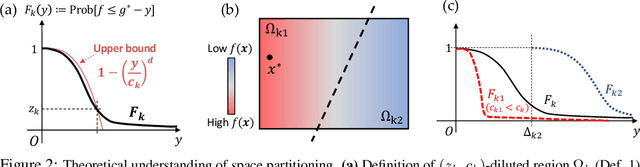
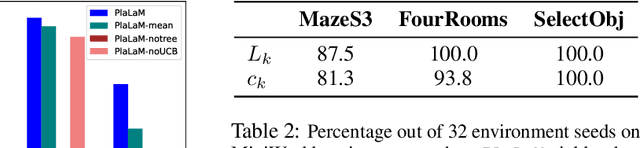
Path planning, the problem of efficiently discovering high-reward trajectories, often requires optimizing a high-dimensional and multimodal reward function. Popular approaches like CEM and CMA-ES greedily focus on promising regions of the search space and may get trapped in local maxima. DOO and VOOT balance exploration and exploitation, but use space partitioning strategies independent of the reward function to be optimized. Recently, LaMCTS empirically learns to partition the search space in a reward-sensitive manner for black-box optimization. In this paper, we develop a novel formal regret analysis for when and why such an adaptive region partitioning scheme works. We also propose a new path planning method PlaLaM which improves the function value estimation within each sub-region, and uses a latent representation of the search space. Empirically, PlaLaM outperforms existing path planning methods in 2D navigation tasks, especially in the presence of difficult-to-escape local optima, and shows benefits when plugged into model-based RL with planning components such as PETS. These gains transfer to highly multimodal real-world tasks, where we outperform strong baselines in compiler phase ordering by up to 245% and in molecular design by up to 0.4 on properties on a 0-1 scale. Code is available at https://github.com/yangkevin2/plalam.
LS3: Latent Space Safe Sets for Long-Horizon Visuomotor Control of Iterative Tasks
Jul 10, 2021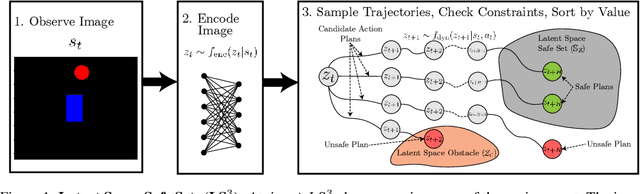
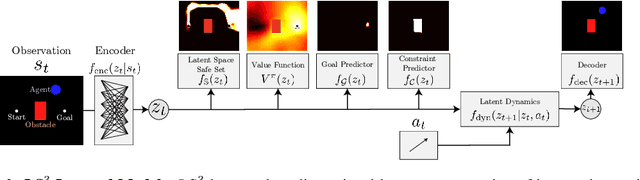


Reinforcement learning (RL) algorithms have shown impressive success in exploring high-dimensional environments to learn complex, long-horizon tasks, but can often exhibit unsafe behaviors and require extensive environment interaction when exploration is unconstrained. A promising strategy for safe learning in dynamically uncertain environments is requiring that the agent can robustly return to states where task success (and therefore safety) can be guaranteed. While this approach has been successful in low-dimensions, enforcing this constraint in environments with high-dimensional state spaces, such as images, is challenging. We present Latent Space Safe Sets (LS3), which extends this strategy to iterative, long-horizon tasks with image observations by using suboptimal demonstrations and a learned dynamics model to restrict exploration to the neighborhood of a learned Safe Set where task completion is likely. We evaluate LS3 on 4 domains, including a challenging sequential pushing task in simulation and a physical cable routing task. We find that LS3 can use prior task successes to restrict exploration and learn more efficiently than prior algorithms while satisfying constraints. See https://tinyurl.com/latent-ss for code and supplementary material.
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021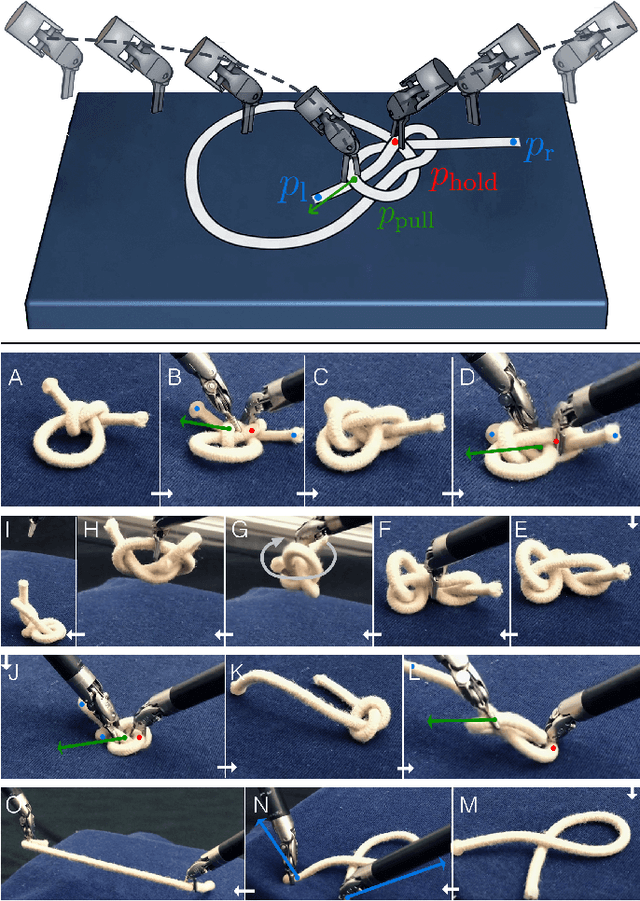
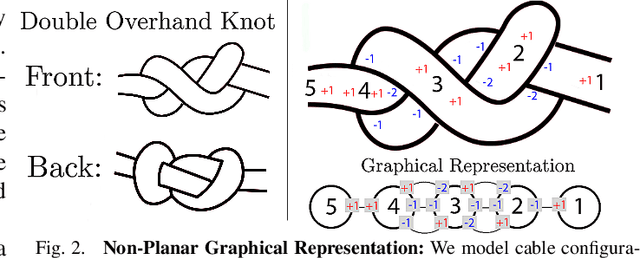
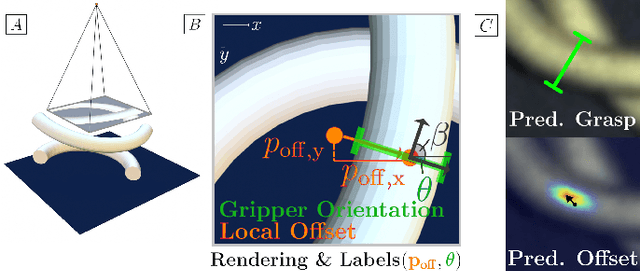
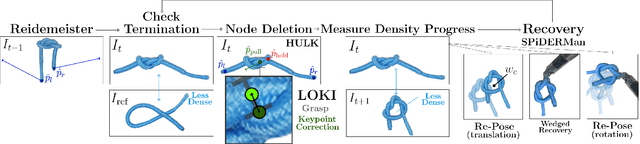
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.
CathAI: Fully Automated Interpretation of Coronary Angiograms Using Neural Networks
Jun 14, 2021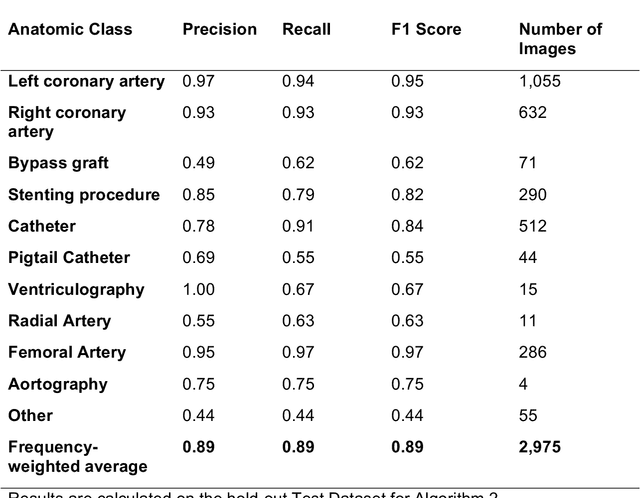
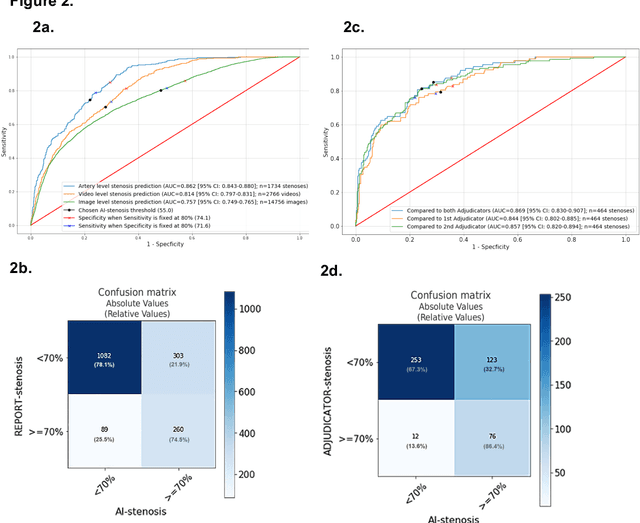
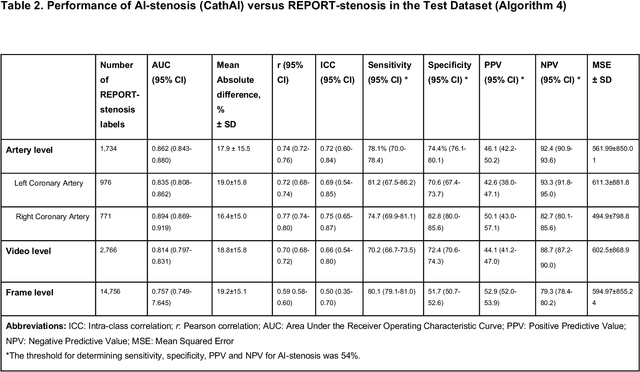
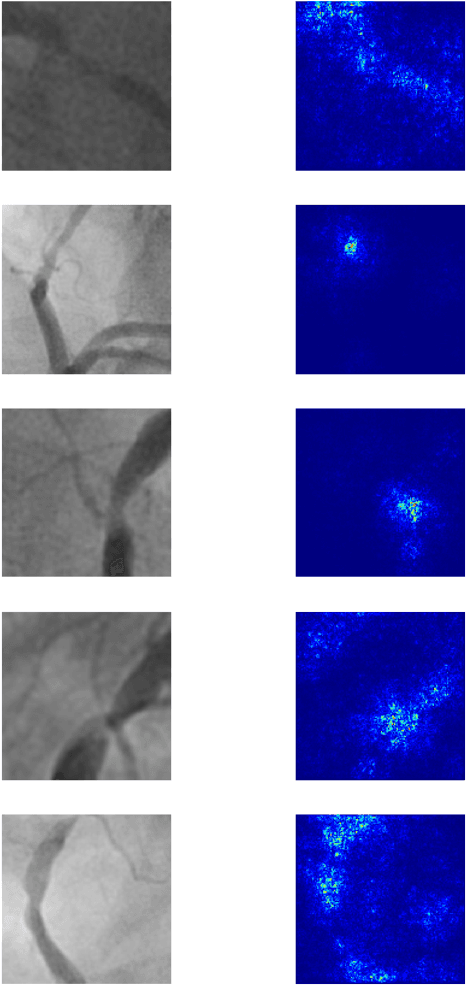
Coronary heart disease (CHD) is the leading cause of adult death in the United States and worldwide, and for which the coronary angiography procedure is the primary gateway for diagnosis and clinical management decisions. The standard-of-care for interpretation of coronary angiograms depends upon ad-hoc visual assessment by the physician operator. However, ad-hoc visual interpretation of angiograms is poorly reproducible, highly variable and bias prone. Here we show for the first time that fully-automated angiogram interpretation to estimate coronary artery stenosis is possible using a sequence of deep neural network algorithms. The algorithmic pipeline we developed--called CathAI--achieves state-of-the art performance across the sequence of tasks required to accomplish automated interpretation of unselected, real-world angiograms. CathAI (Algorithms 1-2) demonstrated positive predictive value, sensitivity and F1 score of >=90% to identify the projection angle overall and >=93% for left or right coronary artery angiogram detection, the primary anatomic structures of interest. To predict obstructive coronary artery stenosis (>=70% stenosis), CathAI (Algorithm 4) exhibited an area under the receiver operating characteristic curve (AUC) of 0.862 (95% CI: 0.843-0.880). When externally validated in a healthcare system in another country, CathAI AUC was 0.869 (95% CI: 0.830-0.907) to predict obstructive coronary artery stenosis. Our results demonstrate that multiple purpose-built neural networks can function in sequence to accomplish the complex series of tasks required for automated analysis of real-world angiograms. Deployment of CathAI may serve to increase standardization and reproducibility in coronary stenosis assessment, while providing a robust foundation to accomplish future tasks for algorithmic angiographic interpretation.